Most people look at XBRL as simply a means of exchanging information. For example, in the US public companies exchange information with the SEC using the XBRL format. Others around the world are doing the same. Most of these companies use XBRL because they have to.
But XBRL will enable more than an ability to exchange information. In fact, the exchange of information is really only a by product of the structured nature of XBRL. As I point out in my book XBRL for Dummies (page 12), XBRL is:
A means of modeling the meaning of business information in a form comprehendible by computer applications.
It is the structured nature of the informationexpressed in XBRL which is the key. This enables the effective information exchange between business systems. But the structuring of the information causes something else to be structured: metadata. Looking closely at the US GAAP Taxonomy will reveal that the metadata of financial reporting is articulated in a taxonomy which can be used by a computer software application. That metadata, along with other metadata, will enable software developers to create interesting new software.
As I pointed out in a previous blog post, Microsoft Word is used to create 85% of all financial statements yet Word knows nothing about financial reporting.
Looking at three diagrams will help you understand why this structured metadata and the structured nature of XBRL will enable this interesting new software.
Software today
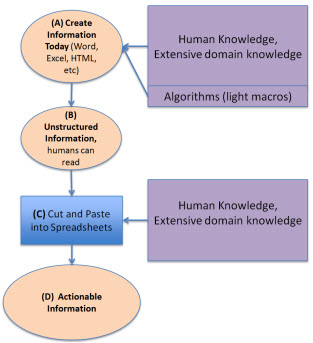
When a financial statement is created today using Microsoft Word, a highly skilled domain expert has to structure that information into the form of a financial statement within Word. That highly skilled person has extensive domain knowledge. They might use some light weight computer algorithms (macros) to assist in the process, but it is mostly a highly skilled domain expert, perhaps with someone else doing the actual typing of information, which hammers out the financial statement.
Then, because the information in the financial statement is unstructured, to reuse the information another domain expert with extensive domain knowledge "cuts and pastes" that financial information into a spreadsheet analysis model or perhaps some other software.
This diagram shows this process: (A) create information, (B) the unstructured information is read by humans or (C) cut and pasted into spreadsheet models, which (D) leads to actionable information, or information which "supports action", information you can do something with.
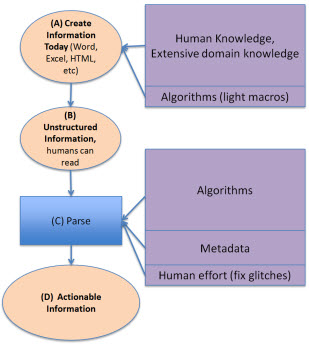
Rather than "cutting and pasting" the information you could do what Edgar Online has been doing for years which is creating parsing routines which minimize the need for "cut and paste" and use software algorithms to parse the information. Edgar Online parses SEC HTML and SGML filings and then makes the information available to those that use the information, for example analysts.
A key point to realize here is that these parsing routines are driven by domain metadata. It is those computer understandable algorithms and metadata which allows a computer to recognize that, say, a piece of information is a specific balance sheet line item. Rather than the human "cut and paste" by a highly skilled domain expert, it is a computer algorithm and metadata created by highly skilled domain experts and software developers which puts the information where you want it. The key thing to not here is how the domain knowledge moved around a bit.
Semantic, Structured, Model-based Authoring
What if we moved this metadata and some of these algorithms to the creation end of the financial statement creation, rather than the reuse end? That is what semantic, structured, model-based authoring is all about. The unstructured form and the need to parse the unstructured form into some more useful structured form is totally eliminated because the information is structured in the first place.
How does this happen? Magic? Voodoo? Artificial intelligence? Nope, it happens because of the metadata. Computers may not be able to do everything for the user who wants to create a financial statement, but there is an incredible amount that a computer can, and will, do. Human effort is reduced by the algorithms and metadata, costs are saved. Having a highly skilled domain expert doing cut and paste operations is a waste of their skills. Using a 10 key to verify that the numbers in the financial statement add up is not only a waste of skill, but humans get tired and make mistakes. Computers don't get tired. These repetitive, simple, time consuming tasks can be taken over by computer software leaving the highly skilled domain experts to focus on things like judgment; things a computer will never have.
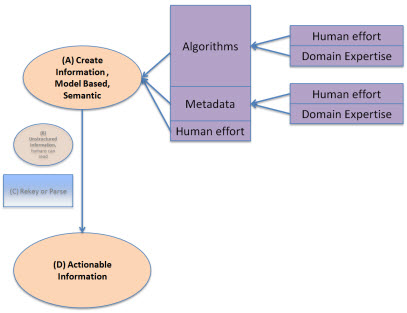
Metadata
What is the only thing better than metadata? More metadata. Metadata can take various forms such as business rules, for example:
- Assertions: For example asserting that the balance sheet balances or Assets = Liabilities + Equity.
- Computations: For example, calculating things, such as Total Property, Plant and Equipment = Land + Buildings + Fixtures + IT Equipment + Other Property, Plant, and Equipment.
- Process-oriented rules: For example, the disclosure checklist commonly used to create a financial statement which might have a rule, "If Property, Plant, and Equipment exists, then a Property, Plant and Equipment policies and disclosures must exist."
- Regulations: Another type of rule is a regulation which must be complied with, such as "The following is the set of ten things that must be reported if you have Property, Plant and Equipment on your balance sheet: deprecation method by class, useful life by class, amount under capital leases by class . . ." and so on. Many people refer to these as reportability rules.
- Instructions or documentation: Rules can document relations or provide instructions, such as "Cash flow types must be either operating, financing, or investing.
Another type of metadata is relations. For example, how one concept is related to another concept.
The US GAAP Taxonomy itself is metadata, it defines concepts and relations between concepts used in financial reporting.
Other metadata is the conceptual framework of US GAAP itself. Not all this metadata will be, or even has to be, expressed using XBRL. It only needs to be understandable to a computer. Who will create this metadata? Humans who have domain knowledge.
It is this metadata which articulates the semantics which today exist in books and other forms not understandable by computers. It is the semantics which will drive the software. It is the model-based nature, which is really more metadata, which enables this new approach to authoring.
The world is already going down this path. Many software companies started down this path long before XBRL even existed. Many tools already exist for specialized tasks, but they are very expensive.