This is probably one of the best examples of the problems caused when a machine is forced to imply information. It is an example of where one error can lead to another error which masks the first error. It is also an example of the consequences which occur when a filer in essence redefines the meaning of a concept by using a concept in a different way than it was intended.
I will use this AT&T filing to make my point. I am not picking on AT&T, it is just that I happen to run across this in my tuning of the fundamental accounting concept impute rules.
If you look at the income statement of AT&T, focusing on the operating income section:
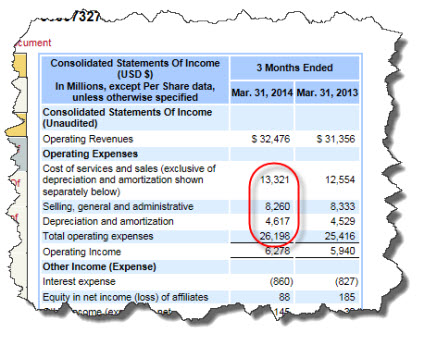
The income statement looks straight-forward enough. Note the line item "Total operating expenses". If you examine the concept using the SEC interactive data viewer, you see that the filer used the concept us-gaap:OperatingExpenses to represent that fact:

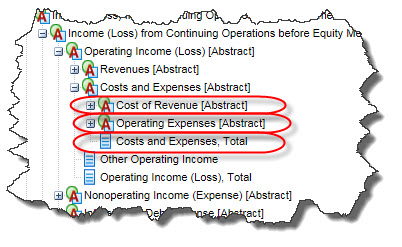
However, if you examine the US GAAP XBRL Taxonomy, you notice that the concept Operating Expenses does not include Cost of Revenue. The total of Cost of Revenue and Operating Expenses is the concept Costs and Expenses:
However, if you take a look at the AT&T income statement again, AT&T included the line item "Costs of services and sales" within the line item Total operating expenses.
So, the problem is that AT&T should have used the concept us-gaap:CostsAndExpenses to represent the line item they refer to as "Total operating expenses". While the label is similar to the concept they did use, the meaning of what they are representing matches the concept Costs and Expenses which includes Cost of Revenue.
The problem is that my fundamental accounting concept relations conformance testing did not pick up this error. The impute algorithm imputed a value incorrectly. So, the error made by the filer who used the wrong concept is masked by an error in the impute algorithm which imputed a value incorrectly. The results of my validation report did not show any errors.
But I found this when I looked at the validation report. Now, a human can figure out that an error occurred by looking at the information, but a machine stumbles over this and does not realize that it made an error. But if I never happend to look at the report, I would not detect the mistake.
This is why it is better to explicitly provide information rather than force a machine to try to imply a fact.