BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Things Accountants Will Likely Get Wrong about Transformation to Digital
Successful business models are built; overcoming adversity; then business models are undone. Burroughs is a perfect example of this. There are many others, all one needs to do is look.
It would be wishful thinking to believe that the institution of accountancy in whole or in part can escape the fate of the change from analog to digital. Change will come. There are two possible types of change: change by replacement (total disruption) and change by reform (adapt what exists). Likely the change will be a combination of replacement and reform.
The Great Upheaval, on pages 208 and 210, provides a summary of commonalities that stand out which industries get wrong during the transition from analog to digital. Here are the common patterns:
- Clinging tenaciously to business models and products too long, even after they were broken or even longer
- Making minimum alterations to business models in a piecemeal fashion by reform, repair, adaption
- Making knee jerk piecemeal responses to adapt rather than making holistic organizational changes
- Do not recognize the coming threat that digital technology posed nor the magnitude of that threat
- Change happened behind their backs while they were busy doing business as usual
- Half-heartedly throw a flurry of puny remedies and failed attempts to find solutions at the wall; but nothing sticks; leading to the belief that meant the market preferences current practices and approaches
- Thinking myopically and focusing on the short term rather than thinking strategically and thinking longer term
- Favoring financial cost cutting rather than investing in the future
- Not being aware of the emergence and growth of potential competitors
Things change; that is a given. No one can predict the future, not even me. But because it is unclear what will happen is not license to be ignorant of what is going on. "Digital" is not software; it is a mindset. This transformation we are in the midst of is not about technology, it is about talent.
 Charlie
in General Information
|
Charlie
in General Information
|
 Post a Comment
|
Post a Comment
|
 1 Reference
|
1 Reference
|  Email
|
Email
|  Print
Print
Answers: Simple but Wrong; Complex but Right
This cartoon says it all. As H. L. Mencken pointed out, "For every complex problem there is an answer that is clear, simple, and wrong." This is not to say that complex problems demand complex solutions.
A kluge is a term from the engineering and computer science world that refers to something that is convoluted and messy but gets the job done. Elegance is the quality of being pleasingly ingenious, simple, neat. Elegance is about beating down complexity.

Creating something complex is easy. Creating something simple and elegant is hard work.
Complexity can never be removed from a system, but complexity can be moved. The Law of Conservation of Complexity states (paraphrasing): "Every application has an inherent amount of irreducible complexity. The question is who will have to deal with that complexity: the application user, the application developer, or the platform developer that the application runs on?"
Irreducible complexity (paraphrasing) is explained as follows: A single system which is composed of several interacting parts that contribute to the basic function and where the removal of any one of the parts causes the system to effectively cease functioning.
For example, consider a simple mechanism such as a mousetrap. That mousetrap is composed of several different parts each of which is essential to the proper functioning of the mousetrap: a flat wooden base, a spring, a horizontal bar, a catch bar, the catch, and staples that hold the parts to the wooden base. If you have all the parts and the parts are assembled together properly, the mousetrap works as it was designed to work.
But if you remove one of the parts of the mousetrap then the mousetrap will no longer function as it was designed; it will simply not work.
That is irreducible complexity: the complexity of the design requires that it can't be reduced any farther without losing functionality.
Simplistic and simple are not the same thing.
Simplistic is dumbing down a problem in order to make the problem easier to solve. Simplistic ignores complexity in order to solve a problem which can get you into trouble. Simplistic is over-simplifying. Simplistic means that you have a naïve understanding of the world, you don't understand the complexities of the world. Removing or forgetting complicated things does not allow for the creation of a real world solution that actually work.
Simple is something that is not complicated, that is easy to understand or do. Simple means without complications. An explanation of something can be consistent with the real world, consider all important subtleties and nuances, and still be simple, straight forward, and therefore easy to understand.
Sensemaking is the process of determining the deeper meaning or significance or essence of the collective experience for those within an area of knowledge. Sensemaking is a tool. You can use sensemaking to construct a map you can share with others. Sensemaking is the art of analysing, understanding, clarifying, untangling, organizing, and synthesizing.
This graphic from the paper Toward a Deeper Understanding of Data Analysis, Sensemaking, and Signature Discovery helps you understand the sense making process.
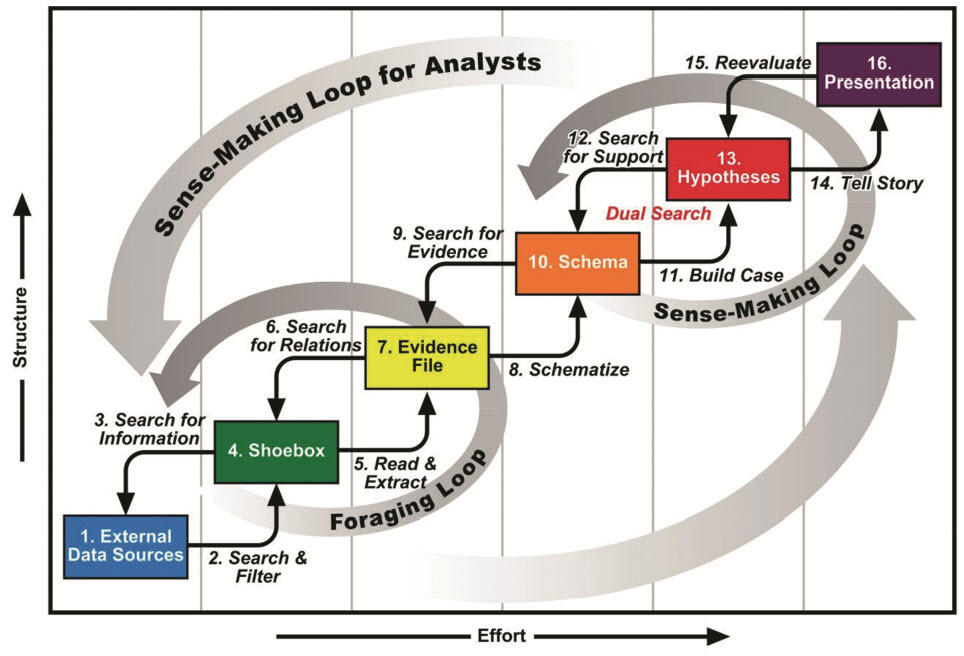
The results of my sensemaking related to accounting, reporting, auditing, and analysis has been summarized in the following documents that will help you wrap your head around the transition from an industrial, analog society to a knowledge, digital society for that area of knowledge. (best read in order)
- Essence of Accounting
- Computational Professional Services
- Financial Report Knowledge Graphs
- Seattle Method
- Essentials of XBRL-based Digital Financial Reporting
- Logical Theory Describing Financial Report
- Mastering XBRL-based Digital Financial Reporting (contains all of the above but adds more details)
To grasp the big picture of the environment we are in, great upheaval that we are in the midst of, I recommend the book by the same name, The Great Upheaval.
If you have a different perspective or ideas I would be very happy to hear them; please contact me.
######################
Charlie
in Digital Financial Reporting
|
Post a Comment
|
3 References
| Email
| Print
DAOs and the Future of Work
The Future of Work is Not Corporate — It’s DAOs and Crypto Networks points out that the future of work is not the corporation, it is the DAO or decentralized autonomous organization.
The purpose of a DAO is to facilitate coordination. DAOs are for facilitating human cooperation via collective ownership. A DAO is a community that allows its members to coordinate funds and resources toward the achievement of some specific goal. A DAO is a new mechanism to coordinate work. DAOs give communities coordination superpowers. DAO members are equity holders in the DAO. That equity can grow, and grow, and grow.
The article points out that not all DAOs are necessarily "decentralized" or "autonomous". It is best to think of DAOs as organizations that leverage the connectivity and other capabilities of the internet that are collectively owned and controlled by its members.
Participants fill different roles in a DAO. Here are some examples provided by the article referenced above:
- Core contributors: (work-to-earn) Core contributors are how we typically think of employees today; people focusing full-time on a project or organization. The singular focus allows the individual to be embedded within the project and amass contextual and strategic knowledge.
- Bounty hunters: (contribute-to-earn) Bounty Hunters complete clearly defined work for an agreed upon price and / or duration of time.
- Network participants: (participate-to-earn) Within any given DAO, this is where the majority of people will fall. Networks gain strength with more activity and additional participants, yet, for years, users, consumers, and participants have been adding value to networks without capturing their share of value. Functioning more like open economies than closed organizations, DAOs will reward each individual contribution based on the value it provides, regardless of who it comes from. This means that everyday actions that are valuable to a network will be turned into income-earning opportunities.
A DAO is a great way to build a product and bring it to market.
Here is more information about DAOs:
- What is a DAO and What is it Used for?
- Decentralized Autonomous Organizations (DAO)
- Where to Pay Attention to Blockchain in 2022
- ConstitutionDAO
- DAOhaus
- How to Create a DAO
#####################################
DAOs Are Not Scary, Part 1: Self-Enforcing Contracts and Factum Law
Charlie
in Digital Financial Reporting
|
Post a Comment
|
1 Reference
| Email
| Print
Global Master Plan for XBRL-based Digital Financial Reporting
We are in the midst of a great upheaval. As Levine and van Pelt point out in their book, "we are in a time of profound, unrelenting, and accelerating change of a magnitude and scope unequaled since the Industrial Revolution." We are transitioning from an analog, industrial economy to a digital, knowledge economy. We are transitioning from a national focus to a global focus.
As part of this transition from analog to digital, leaders within the institution of accountancy along with others have created the global standard XBRL technical syntax.
The next step is to create a global master plan for XBRL-based digital general purpose financial reports. Auditors should participate in the creation of this plan.
Today, there is pretty much a literal free-for-all when it comes to creating XBRL taxonomies for financial reporting and how to best create such XBRL taxonomies is blurred and confused for most. Regulators are taking different approaches. There is consensus that the quality of XBRL-based reports submitted to the SEC and ESMA are not of the quality that they need to be.
This free-for-all and the quality issues causes confusion and increases risk for pretty much everyone including software vendors, auditors, regulators, and economic entities that report. Making the confusion go away would help pretty much everyone.
And what if non-regulated private companies want to move from analog to digital; what are they to do? There is no global standard formal approach that they can adopt that is proven to work so well that they could implement digital reporting within their organization.
The Seattle Method and the Standard Business Report Model (SBRM) could end up as de facto best practices or good practices based approaches to implementing XBRL-based digital financial reporting. There are already over eight groups implementing or publically experimenting with these ideas that I can make you aware of at this point. Others I know of are experimenting in private.
XBRL-based digital general financial reports may never replace all paper-based or e-paper based general purpose financial reports. But they are a good tool if they work reliably and predictably. If there is not agreement as to what information is being conveyed by the reports and the quality of that information, there is no way such reports can ever be audited.
Optimally, there would be one set of standard XBRL-based digital financial report approaches. Not sure that will ever happen, but it is worth trying for and seeing what happens. In the United States, I see these use cases and markets (best information that I have):
- Public company financial reporting, about 6,000 companies.
- Private company financial reporting, about 85,000 larger companies with over 500 employees and up to 25,000,000 medium, small, and micro companies.
- State and local governmental financial reporting, about 110,000 states, towns, villages, cities, school districts, public utility districts, transit authorities, and so forth.
- Not-for-profit financial reporting, about 350,000 not-for-profits that report to the Federal Government in support of federal grants.
- ERISA pension plans financial reports, about 850,000 plans.
- DEFI financial reporting, about 7,000 crypto currencies and growing.
- Personal financial statements, about 1,000,000 individuals
But if XBRL-based digital financial reporting does not work (i.e. not "Better"), takes more time (i.e. is not "Faster", costs more money (i.e. is not "Cheaper"), or is too hard to use; then XBRL-based reporting by those groups above is a non-starter.
If the SEC or ESMA lifted their XBRL reporting mandates today, how many companies would continue to use XBRL? Probably 100%. Why? Because current approaches don't provide enough value, they are not BETTER, they are not FASTER, and they are not CHEAPER.
From what I can see, there are THREE current approaches:
- Standard Forms: Comparability is good, information quality is good, but there is a loss of idiosyncratic detailed information. This is useful in some cases even if detailed information is lost.
- Customized Free Form (or uncontrolled) Models: Idiosyncratic details are preserved; but information comparability is bad and information quality is poor.
- Customized but Controlled Models: Comparability is good, information quality is good, and idiosyncratic details of economic entities is preserved. Most regulators that use approach #1 will change to this approach when it works effectivly I predict.
This graphic below provides a comparison of the three approaches that was inspired by an academic paper that I referenced in another blog post:
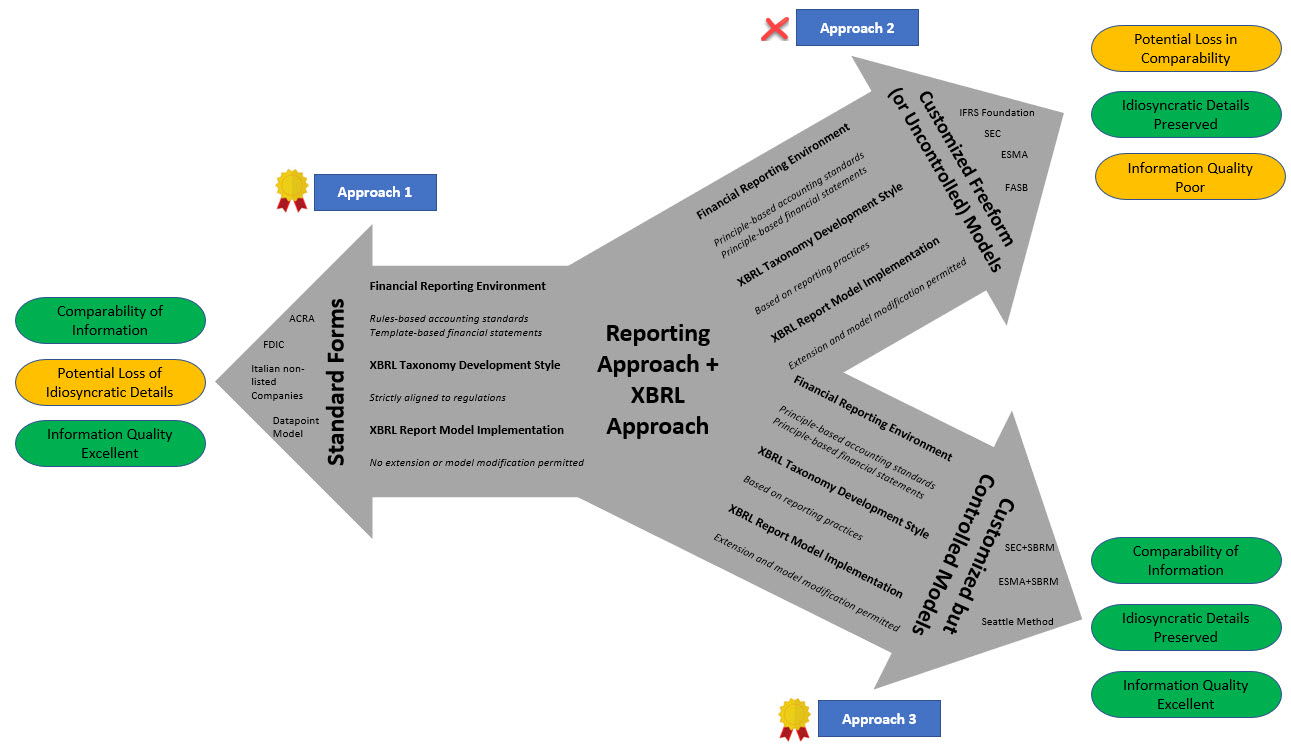
I hold the Seattle Method out as an example of what can be achieved. Whether the leadership in the institution of accounting can put something better together, time will tell. Whether the market will accept XBRL-based digital financial reporting is an unknown.
If you want to understand how change unfolds, I would encourage you to read the book The Great Upheaval. If you want to understand the environment in which all this will be operating, read New Rules for the New Economy. If you want to understand the details of the Seattle Method, I would point you to these resources.
Should you want to master XBRL-based digital financial reporting, here you go.
It will be interesting to see how all this unfolds.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Reporting Approaches + XBRL Approaches + Implementation Approaches
I ran across a very good academic paper that was published in 2013. The title of the paper is Critical Reflection on XBRL: A “Customisable Standard” for Financial Reporting? In the paper they compare two approaches for creating XBRL taxonomies and reports and they provide the following graphic from page 126 of that paper. They call the approaches "Standardization" which means a forms-based implementation with no extensions allowed and "Customization" which means extensions are allowed. Then at the bottom they provide information about the resulting ability to consume reported information and the idiosyncratic details provided within the report.
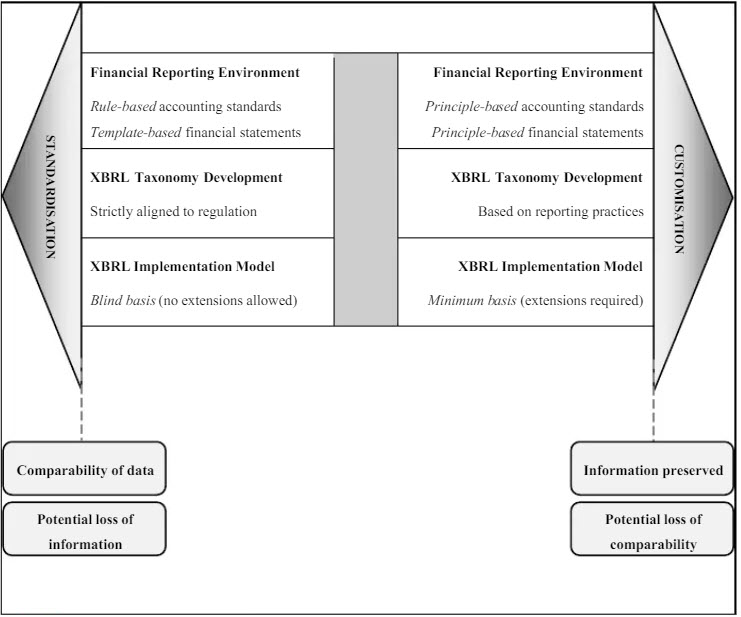
That is a good graphic, but the graphic is incomplete. And so I created my own graphic inspired by the graphic provided in the above academic paper. What I did was break the "Customization" down into two distinct parts:
- "Freeform Model" is where an implementer allows extensions to taxonomy report elements and to the creation of a report model but DOES NOT PROVIDE MECHANISMS TO CONTROL the extensions or reconfigurations to keep them within permitted boundaries.
- "Controlled Model" is also where an implementer allows extensions to taxonomy report elements and to the creation of a report model and ALSO PROVIDES A MECHANISM TO CONTROL the extensions and reconfigurations of the report model in order to keep them within permitted and expected boundaries.
This graphic is my enhanced version of what the paper above provides. I have also color coded the consequences of the implementation decision:
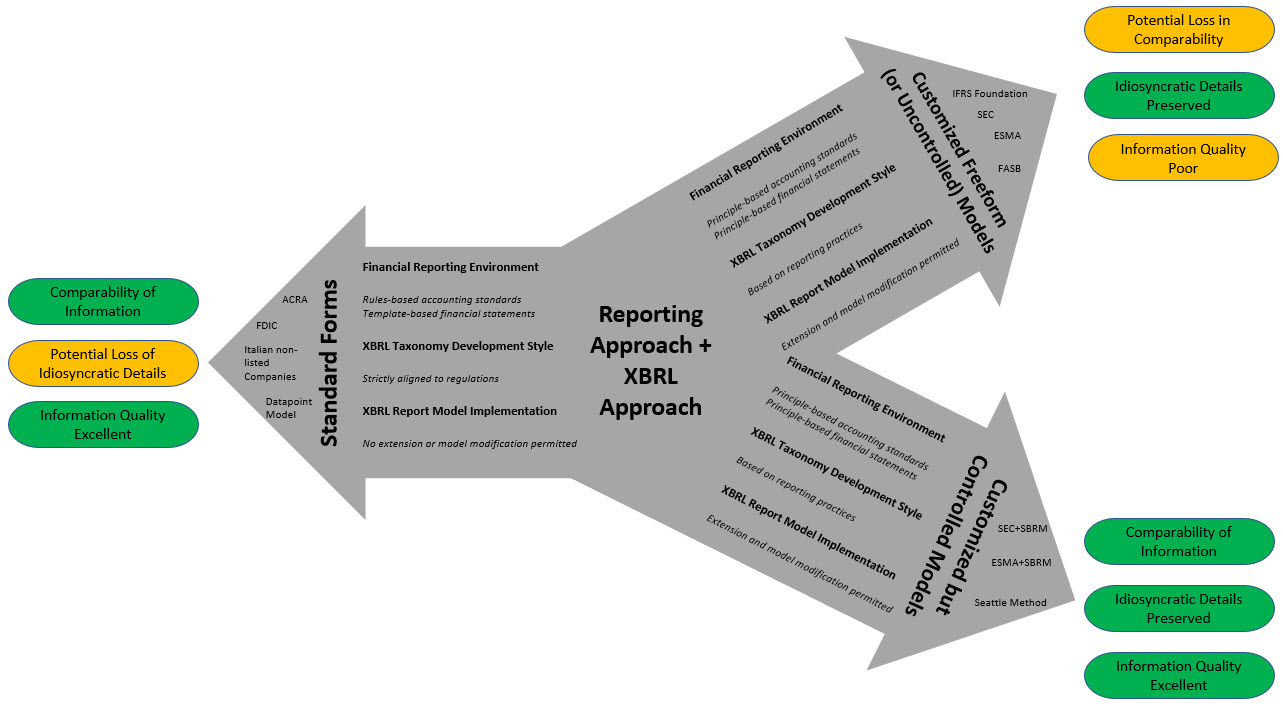
Granted, the Seattle Method did not exist in 2013 when that academic paper was written. But now it does exist.
Today, most existing XBRL implementations use the Standard Forms approach. Those that do allow for customization do not control the report model customization well, if at all really; as a result they have quality issues.
#################
Charlie
in Digital Financial Reporting
|
Post a Comment
|
1 Reference
| Email
| Print
