Consider this. A public company takes information about their financial position and financial condition out of a database and/or electronic spreadsheet. The put that information into the XBRL format and send that financial information to the U.S. Securities and Exchange Commission (SEC). The SEC, and others, take that financial information and put it into another database.
The database the information came out of typically does not understand the the information that is coming out of the database. The database has no understanding of business context, it just stores data.
The XBRL-based format does have context, but most XBRL processors don't understand that context. Just because current XBRL processors don't understand the context does not mean that the context is not there. For example, just because public companies and software vendors make basic mistakes in representing the information in the XBRL format does not mean that the context does not exist. The context does exist within the XBRL format.
The database that the information ends up going into typically does not understand the context of the information being put into the database. The 28msec database, SECXBRL.info, is a little different in that the context of the information from the XBRL is stored. Not the XBRL technical syntax, the context of the information. There is a big difference between the two. Now, the 28msec database does not understand much of that context such as the relations between facts in the database such as "Assets" and "Liabilities and Equity". Why? Because they don't have the machine-readable rules that articulate that context. But what if their database did have those machine-readable rules? They do have some.
The graphic below tries to show what I am talking about. The graphic was inspired from another graphic which I modified to better communicate what I am trying to point out. Here is my version of this graphic:
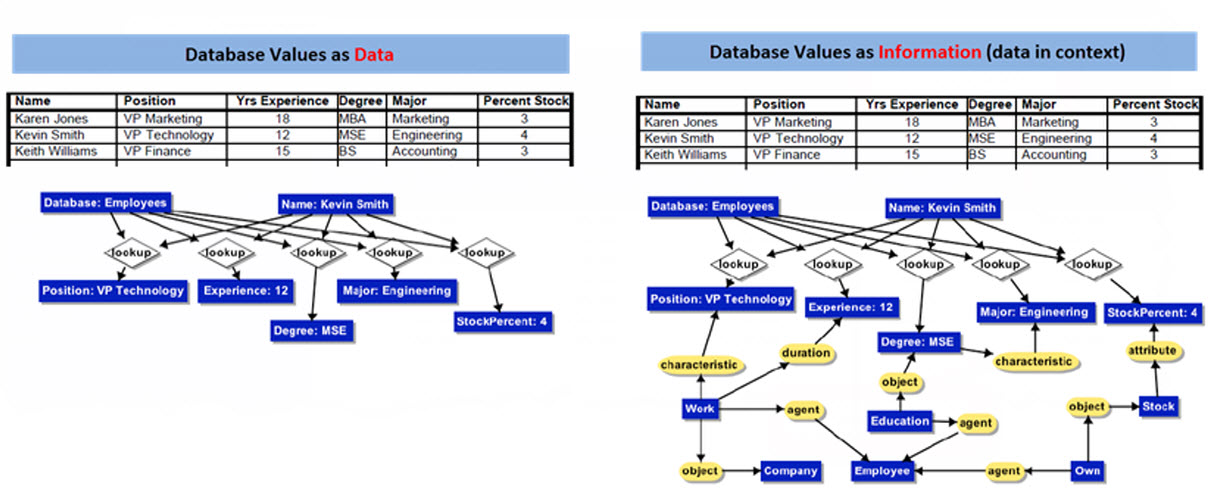 (Click image for larger view)
(Click image for larger view)
The paper Semantics in Databases points out many issues related to storing and working with semantics in database management systems (DBMS). The first thing the paper points out is the many different ways people use the term "semantics" in computer science. The paper goes on to point out that DBMS incomplete and partially unsound facilities for handling semantics. This statement from the paper succinctly articulates the issue:
"The same statement must have a stable interpretation and cannot be differently interpreted by different computer systems."
That statement gets to the same point that I have been making for many years: achieving a meaningful exchange of information.
This is perhaps a little bit of a leap. But, what if XBRL was a global-standard facility for expressing, exchanging, and verifying DBMS semantics? Could it be that XBRL is a solution to some of the issues pointed out by that paper?
That paper makes the statement, "This widespread usage of the term 'semantics' has led to very different goals, methods, and applications." Why would ISO create a global standard for Common Logic? What, some people did not have anything better to do one weekend? I don't think so. Why are people creating RuleML?
It seems to me that the semantic web is struggling. While there are issues with getting XBRL to work, the folks creating electronic medical records are having similar sorts of issues. Will the vision of the semantic web ever be realized? Does XBRL have a role in that vision? I think it does.
What do you think?
******MORE INFORMAION*********
Book, Semantics in Databases.