Achieving Meaningful Exchange of Information
This information is highly influenced by these three sources: Barry Smith's Introduction to Ontologies, this Semantics Overview, and An Intrepid Guide to Ontologies. I encourage business users, particularly accountants, trying to understand XBRL or digital financial reporting to watch a these videos and read all this material, it is very helpful.
The only way a meaningful exchange of information can occur is the prior existence of agreed upon semantics and syntax rules. This is the only way. These rules are a precondition for a meaningful information exchange. To the extent that a meaningful exchange occurs the information exchanged can be effectively reused without human intervention. There is a direct correlation between the "agreed upon semantics and syntax rules" and the "meaningful exchange of information." Full stop.
"Agreed upon semantics" has two important aspects: structure and formalism. Both structure and formalism are aspects for classifying semantics and constitute the expressiveness of the semantics which have been agreed to.
Structure
There are many ways to capture the semantics, or meaning, of the things and the relations between the things which make up a domain. These are referred to as organizational systems or classification systems. These are several sorts of such systems:
- A controlled vocabulary or dictionary can provide a good list of things but tends to be weaker at expressing the relations between the things. A controlled vocabulary is basically a set of standard terms. Also, the properties of each of the terms is generally limited.
- A taxonomy or classification system adds the notion of a hierarchy between the members of a controlled vocabulary. For example, the terms "horse" and "cat" and "dog" are all types of "mammals". So, you have a good list of things the general sorts of relations between those things.
- Something like a thesaurus provides a specific type of relationship, a similar term, a broader term, or a narrower term; between the pieces some controlled vocabulary. But again, only some sorts of relations are covered.
- An ontology allows you to define your controlled vocabulary, a very rich set of properties for the things within that controlled vocabulary, and your own types of relationships between the things in the vocabulary. Specific, explicit types of relationships rather than general "parent-child" type relationships.
Formalism
Creating a structured system can be more formal, or less formal.
The graphic below shows the "bridging role" that something like an ontology plays between a domain and the content of that domain. Every ontology attempts to “define” and bound a domain. The graphic tries to highlight the trade-off between semantics v. pragmatic considerations.

As pointed out above, the different types of organizational systems have more, or less, expressive power. The more expressive power, the more time and money it takes to achieve that expressiveness and the higher the semantic clarity of the organizational system which one might create. This is represented graphically below:
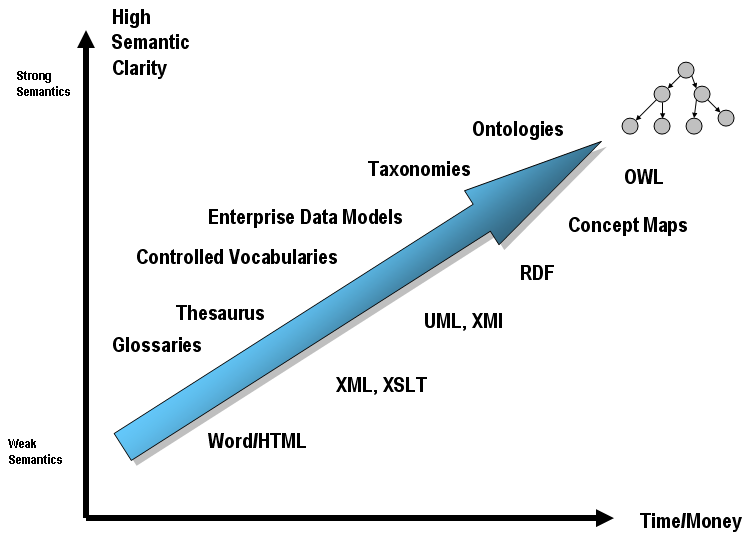 Based on work by Leo Obrst of Mitre as interpreted by Dan McCreary, we can view this as a trade-off as one of semantic clarity v. the time and money required to construct the formalism - See more at: http://www.mkbergman.com/date/2007/05/16/#sthash.mDBjSUHi.dpuf
Based on work by Leo Obrst of Mitre as interpreted by Dan McCreary, we can view this as a trade-off as one of semantic clarity v. the time and money required to construct the formalism - See more at: http://www.mkbergman.com/date/2007/05/16/#sthash.mDBjSUHi.dpuf
Information quality
And so, the quality of the information expressed can only be as good as the rules expressed which force the information to be correct, particularly via automated verification processes enforced by computer software. Now, granted, you will always need some manual processes to make sure the information is correct, for example it is impossible for a an automated process to pick the correct metadata to assign to, say, some reported fact in a financial report. A computer process can help, but it cannot do everything. The more a computer can do, the more that can be automated. The more that can be automated, the higher the quality of the information created and the less time and money it takes to make sure the information is correct.
This is particularly true if there are thousands and thousands of different people are creating this information, for example such as the thousands of reporting entities creating something like an SEC XBRL financial filings using XBRL.
Any expression of these "things" and the "relations between the things" in an ontology or whatever the classification system must be in a form that business people understand. This must be true because only the business people which have expertise within the domain for which the organizational system is being expressed can tell you if the expression of those things and relations are correct.
By correct I mean a sensible, logical, consistent, complete, accurate. Each piece of something like a digital financial report must be correct and the relations between each piece must be correct. For example, "Assets = Liabilities + Equity" is true in the domain of financial reporting and therefore must be true in any expression of "Assets" and "Liabilities and Equity" in any financial report. This is a simple example to make a point, there are much more complicated situations. Only domain experts understand these situations.
The bottom line is this: if business users cannot create correct digital financial reports, for example an SEC XBRL financial filing, then those digital financial reports cannot be useful. If they are not useful, they will not be used.
Software must help business users be successful, software must be interoperable
Software can, will, and in fact is being built to help business users work with whatever classification system might be available. The higher the semantic expressiveness and clarity, the more the software will be able to do for the business user.
To solve the usability issues, a number of software vendors are already (and more will follow) creating their own proprietary "models". The XBRL Abstract Model 2.0 is helpful in assuring interoperability between these implementations, but it is not sufficient to assure semantic interoperability.
The wrong debate
There is a debate about which is the appropriate way to express XBRL information: (a) Inline XBRL is pushed by some, (b) Data Point Model (DPM) is pushed by others, (c) Global Filing Manual, not sure how that is going, (d) the SEC/US GAAP Taxonomy is similar to the Global Filing Manual approach.
However, this is the wrong debate. Not one of these approaches can offer definitive proof that it actually works to enable a meaningful exchange of information and none of these approaches addresses the fundamental fact that "meaningful exchange can only occur to the extent of prior existence of agreed upon semantics and syntax rules."
Syntactic rules and therefore syntactic interoperability at the XBRL technical syntax level is very good, it has been since about 2003 when XBRL International started building conformance suites. However, semantic interoperability still suffers, so information use suffers.
I would encourage XBRL International and software vendors to focus on enabling business users to achieve semantic interoperability to the level that syntactic interoperability was achieved.
To the extend semantic interoperability is achieved, meaningful exchange of information can occur.
 Charlie
in Digital Financial Reporting, Modeling Business Information Using XBRL
|
Charlie
in Digital Financial Reporting, Modeling Business Information Using XBRL
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments