BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries in Modeling Business Information Using XBRL (213)
Understanding Distributed Extensibility
A good way to understand distributed extensibility is to contrast it to the more common term "extensibility". People throw that term "extensibility" around. But what does it really mean?
How do you really know if something is "extensible" or not? How do you know if the extensibility actually works? Extensibility of what? All good questions.
Consider this basic definition of extensibility as a starting point:
- Extensibility: You can add "stuff".
OK, you can add "stuff" what stuff? Well, if you are looking at XBRL, you might want to add one of the following: a Network, a Table (hypercube), an Axis (dimension), a Member, a Concept, or an Abstract. You might also add a new relation between, say, one Concept and another Concept such as a roll up relation. Or you might want to represent the parts of a whole. So, extensibility for XBRL is that you can add those sorts of things that exist within XBRL; "stuff" and "relations between stuff".
People sometimes use the terms "open taxonomy" and "closed taxonomy". I have used those terms myself. But those terms are not appropriate.
I corrected myself, realizing that taxonomies can have openings. The way that I see this now is that taxonomies MUST ALWAYS be "closed" or rather have conscious, known, understandable boundaries. Or more precisely, a taxonomy provides specific, conscious "openings" where those reporting against the taxonomy can consciously articulate specific information and therefore extend the taxonomy in conscious, known, specific ways ONLY.
US GAAP-based financial reporting is open. While US GAAP does prescribe many specific disclosures; a reporting entity can add additional disclosures as it sees fit. An entity must provide the minimum, but they can supplement what they disclosue with additional information. Also, some relations can be moved around to a degree. But, US GAAP based financial reporting is not a "form" that you fill in and it is also not "random".
So, when you employ XBRL-based digital financial reporting and you want to "extend" what might be reported, how you provide that extended information is not random or arbitrary. Recall the definitions of standard and arbitrary:
- Standard: used or accepted as normal or average; something established by authority, custom, or general consent as a model or example
- Arbitrary: based on random choice or personal whim, rather than any reason or system; depending on individual discretion (as of a judge) and not fixed by law
Consider that there is one SEC and that there are about 8,000 public companies and each of those public companies can "extend" the US GAAP XBRL Taxonomy. How is the extension of the US GAAP XBRL Taxonomy coordinated by the SEC to each of the 8,000 reporting entities? Well, that is done through the use of standards, the XBRL standard (technical standard) and US GAAP (domain standard) and other forms of cooperation and coordination.
I would throw out these two different types of "extensibility" (this is influenced by but different from what is described in this video which I pointed out in an earlier blog post):
- Distributed extensibility: Extensibility that is not explicitly controlled and coordinated by one organization but rather using standard-based mechanisms and rules. For example, US GAAP-based financial reporting to the SEC is a type of distributed extensibility because while the entire system is controlled by some standard set of rules, each reporting entity has control and can extend the system; but they must stay within a set of rules which coordinates the extensibility.
- Local extensibility: Extensibility that is "inside the walls" of one organization and all extensibility is explicitly coordinated and controlled within and by one organization. For example, a chart of accounts of an organization is an example of local extensibility.
Local extensibility is far, far easier to implement because there is less coordination necessary. And generally local extensibility was all that was needed until the internet came along and interconnected everyone. The interconnectedness blurs system boundaries. What does "internal" mean for say the SEC EDGAR system. Is only the SEC "internal" or are each of the entities that report to the SEC "internal" to the system also?
Coordinating and controlling a system when users of the system are allowed to change the system is very powerful functionality. Not change the system in random or arbitrary ways. But rather change the system in standard and agreed upon ways.
These "agreed upon ways" are the rules of system extensibility. They explain exactly how the system can be extended. This agreement is achieved by using appropriate rules. I will repeat my mantra for anyone who might have missed it:
The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
It is the rules which provide to control and coordination which makes the distributed extensibility work effectively. It is the rules which turn the guessing game into a reliable, predictable, repeatable and therefore useful distributed, yet coordinated, system. It is the rules that form the agreement in a distributed environment. It is the rules which are a cooperation tool.
As I said in my book XBRL for Dummies, "Agreement is an important element that acts as the invisible glue to make XBRL really work." Agreement does all sorts of powerful things.
Business professionals are taught a basic idea in business school, "If you cannot measure it, you cannot control it." H. James Harrington puts it this way:
Measurement is the first step that leads to control and eventually to improvement. If you can’t measure something, you can’t understand it. If you can’t understand it, you can’t control it. If you can’t control it, you can’t improve it.
My disclosure analysis of the Fortune 100 is an example of measurement. Control is trying to get all the cells in the matrix GREEN which means that all parties agree.
The XBRL-based public company financial filings in the SEC's EDGAR system is an example of distributed extensibility almost done right. Based on my measurements, the system appears to be about 90% correct. With just a little more coordination and cooperation in the area of defining classes and relations between classes, we will dial in the remaining 10%.
That, in my view, is an example of the utility of XBRL toward achieving distributed extensibility.
 Charlie
in Modeling Business Information Using XBRL
|
Charlie
in Modeling Business Information Using XBRL
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Understanding Cell Stores and NOLAP, the Future of the Spreadsheet
Ghislain Fourny of 28msec, creators of SECXBRL.info, came up with the notion of the Cell Store which he describes in a paper he wrote on the subject. He describes a cell store as:
Cell stores provide a relational-like, tabular level of abstraction to business users while leveraging recent database technologies, such as key-value stores and document stores. This allows to scale up and out the efficient storage and retrieval of highly dimensional data. Cells are the primary citizens and exist in different forms, which can be explained with an analogy to the state of matter: as a gas for efficient storage, as a solid for efficient retrieval, and as a liquid for efficient interaction with the business users.
The XBRL standard helped to inspire the idea of the cell store. One thing that the paper does not mention but should have mentioned is the XBRL Abstract Model 2.0. The XBRL Abstract Model 2.0 basically articulates the high-level semantic model of a business report.
There are a handful of other adjustments that I would make to the Cell Stores paper.
First, the paper is not clear enough on how business rules are used to both enforce quality and enforce semantics between cells. Cells can be related to other cells. Part of the power of a cell store is the complexity of what can be represented. A perfect example of this is public company financial filings. Those are complex documents with many, many complex relations. Fundamental relations such as "assets = liabilities and equity" and more complex relations. These business rules are critical because they keep the information quality high. But the business rules provide something else: increased reasoning capacity of software applications.
Second, the notion of "concept arrangement patterns" and "member arrangement patterns" are not explained well in the paper and some errors exist. This is partly my fault. These names have changed (from pattern, to metapattern, to accounting concept arrangement pattern, and finally to concept arrangement pattern). These relations exist and they are critical to making this system work correctly. The notion of a "whole-part" relation is left out all together.
Third, the paper says that these concept arrangement patterns and member arrangement patterns exist "according to me". That is not the case. What I have done is observed and documented. These patterns exist in SEC XBRL financial filings. It is those financial reports that state that these patterns exist. I simply made the observation and wrote the information down. Empirical evidence proves that these relations exist, not my opinion.
Finally, the paper points out very clearly that XBRL enables the interchange of "data" between different systems. What the paper does not point out clearly enough is that not only can you exchange "the data" but you can also exchange "the model", the metadata. This is a crucial distinction. Which brings us to NOLAP.
Another notion that Ghislain came up with was NOLAP. NOLAP, which is explained in the Cell Store paper and which I explain here, overcomes issues with OLAP. Here is a summary of issues with OLAP:
- There is no global standard for OLAP
- Cube rigidity
- Limited computation support, mainly roll ups
- Limited business rule support and inability to exchange business rules between implementations
- Inability to transfer cubes between systems, each system is a "silo" which cannot communicate with other silos
- Inability to articulate metadata which can be shared between OLAP systems
- Focus on numeric-type information and inconsistent support for text data types
- OLAP systems tend to be internally focused within an organization and do not work well externally, for example across a supply chain
- OLAP tends to be read only
Over the years I have mentioned the notion of a "semantic spreadsheet". NOLAP (not only OLAP) is essentially the same thing as my idea of a semantic spreadsheet. This video of the application Quantrix is the closest visual that I have of what a semantic spreadsheet is and how it might work. (Here are more videos)
But Quantrix has issues:
- It is OLAP, not NOLAP
- The format is proprietary, not a global standard
- Quantrix does not understand domain semantics, only report level semantics
I point out these issues not to knock Quantrix, but to point out what NOLAP needs to be. Imagine a ubiquitous spreadsheet format (i.e. not owned by Microsoft) that works within Microsoft Excel, Google spreadsheet, Apple Pages, OpenOffice, connected to relational databases, other proprietary applications, etc.
The application is not like a normal spreadsheet which is "glued" together presentationally with the notion of a workbook, worksheet, row, column, or cell. The spreadsheet is glued together with meaning. Because the spreadsheet is glued together with meaning, in order to understand how to use it you only need to understand the meaning. The spreadsheet acts more like a pivot table. The pivot table is read/write. Information is stored not locally (although it could be, that format would be XBRL), but within a cell store. Or, the information could be taken out of one cell store and transferred into another cell store internal to your organization or external to your organization.
Folks, you don't have to imagine this. You can experience this, right now, today. Call me crazy, but the XBRL-based EDGAR system of public company financial information is exactly that. But there are some issues.
There are some details that are not quite working as they need to work. OK fine, fix the issues. Here are the issues and how to fix each issue:
- Performance: Querying the SEC EDGAR system information is not performant, it is simply a bunch of files within a file system. THE FIX: Put the files into a cell store or some other database.
- Information quality: The quality of the data of XBRL-based financial filings is poor. However, it is improving and it can be improved even more by using more rules. The rules keep the relations between the cells, the information, correct. THE FIX: Add more rules where the information is incorrect to force it to be correct.
- Creation software: Most software vendors made two mistakes in creating software for creating XBRL-based public company SEC filings. (a) The software is too hard to use because it was not built correctly and (b) the software vendor took a myopic view and made the software ONLY work with SEC filings. THE FIX: Build better software and make the software work with XBRL-based SEC financial filings, but not ONLY with SEC XBRL-based financial filings.
- General profile: Six years ago, Rene van Egmond and I pointed out that XBRL implementations are not interoperable. No system uses all aspects of XBRL. However, there is no real "application profile" defined which can be used to create "general" XBRL-based semantic spreadsheets. You have specifications for creating an SEC filings, you have all the rules for that. Those rules come from the US GAAP itself, the US GAAP XBRL Taxonomy and the SEC Edgar Filer Manual (EFM). Someone defined that profile. THE FIX: Create an agreed upon "general profile" which software vendors can implement, for example this is a general profile that I created which is based on and leverages the good aspects of the US GAAP XBRL Taxonomy Architecture/SEC system architecture, but overcomes the bad aspects.
Maybe I missed a few details. But that is all they are, details. I count 22 software vendors who already support the creation of XBRL-based SEC financial filings. 28msec already has a database. There are several other databases that I am aware of. XBRL Cloud has the validation capabilities, see their EDGAR Dashboard. There is already analysis software. What is missing is (a) software vendors collaborating to put these pieces together and (b) an understanding of the existence of a general application profile for doing this.
Companies that don't innovate risk becoming extinct. Do you want to take that risk?
Charlie
in Modeling Business Information Using XBRL
|
Post a Comment
| Email
| Print
Summary of SEC XBRL Financial Filing Verification/Validation Results
The following is a summary of verification/validation results for a set of 7,199 SEC XBRL financial filings. All filings are 10-Ks for the fiscal year 2012 filed with the SEC between March 1, 2012 and February 28, 2013.

Here is some information helpful in understanding these validation/verification results:
- XBRL technical syntax. This information comes from the XBRL Cloud EDGAR Dashboard. Basically 99.9% of all SEC XBRL financial filings in the set of filings I looked at were valid per the XBRL technical syntax specification. What is a little odd is that there were 8 filings which were not valid. What that means is that there are some XBRL interoperability issues. The XBRL validator(s) used by the SEC for inbound validation did not detect the 8 filings as not being valid against the XBRL specification. XBRL Cloud believes that there are XBRL technical syntax errors in these 8 filings. I validated each one against another XBRL processor and sure enough, I found errors in each of the 8 filings reported by that XBRL processor also. As such, I would concur with XBRL Cloud's assessment. (I also posted a message to the XBRL Specification Working Group informing them of these errors. Hopefully a conformance suite test will be added for each of the offending errors, which would improve consistency between XBRL processors.
- Edgar Filer Manual (EFM) automatible rules. Again, this information comes from XBRL Cloud. Why would XBRL Cloud's EFM validation differ from SEC EFM validation? Mainly because of different interpretation of the rules by software vendors (i.e. the ones with the errors), the SEC, and XBRL Cloud. It would be very helpful if all software vendors and the SEC reported the same consistent results. This is getting better, but still has a ways to go given that almost 20% of all filings have EFM rule violations. And these are only the automatable rules.
- US GAAP Taxonomy Architecture Model Structure. These rules relate to the relationships between [Table]s, [Axis], [Member]s, [Line Items], [Abstract]s, and Concepts within an XBRL taxonomy. They also relate to a degree to differences (i.e. ambiguity) between presentation, calculation, and definition relations. These relations are explained in the US GAAP Taxonomy Architecture (see section 4.5, Implementation of Tables). Of all the 10-K filers, 98% follow these rules.
- US GAAP Domain Level Rules. These are a small set of rules (i.e. there are many more) which every SEC XBRL financial filing must follow: assets must be reported, liabilities and equity must be reported, assets = liabilities and equity, equity must be reported, net income (loss) must be reported, and net cash flow must be reported. Why are these rules true? Well, given that 96% of all filers follow these rules and that every filing which I looked at clearly did NOT follow the rule (but should have); it is pretty safe to say that all filers should pass these rules. That is what "domain level" means, US GAAP specifies these sorts of things. Ever hear of the accounting equation: Assets = Liabilities + Equity?
- Balance sheet roll up rules missing. Balance sheets have "assets" and "liabilities and equity". Balance sheets also balance. "Assets" adds up, or "rolls up". Same for "Liabilities and equity". 93% of all filers provide business rules in the form of XBRL calculations which are used to prove that the roll ups are working correctly. 7% did not. If the rules are provided, then automated processes can be used to prove that the line items of the balance sheet roll up. If they are not provided, you can only resort to manual error to make sure things add up. A clue as to which process might work best: automated processes save time and money.
- Income statement roll up rules missing. As with the balance sheet, the income statement rolls up. It foots. Part of the reason why there are so many missing XBRL calculation relations is that filers put numbers in their XBRL filings backwards because they try to get the polarity (positive or negative) to match the presentation. I speculate that they give up in frustration or believe that they just cannot get them to add up correctly. A clue that you CAN make these add up is that about 80% of all filers seem to be able to provide these XBRL calculation rules.
- Cash flow statement roll up rules missing. Again, same deal for the cash flow statement; the line items add up and filers seem to be having problems with the polarity.
This is just a small set of the automatable rules which one can test for. Why would you do that, seems like more work? Well, it is actually less work. Automating the testing of correct modeling, computations, and other rules and relations makes it easier to prove to yourself that you did a good job creating your SEC XBRL financial filing.
As the automated rules grows the quality of SEC XBRL financial filings will improve. Why? Click here.
Charlie
in Creating SEC XBRL Financial Filings, Modeling Business Information Using XBRL
|
Post a Comment
| Email
| Print
Achieving Meaningful Exchange of Information
This information is highly influenced by these three sources: Barry Smith's Introduction to Ontologies, this Semantics Overview, and An Intrepid Guide to Ontologies. I encourage business users, particularly accountants, trying to understand XBRL or digital financial reporting to watch a these videos and read all this material, it is very helpful.
The only way a meaningful exchange of information can occur is the prior existence of agreed upon semantics and syntax rules. This is the only way. These rules are a precondition for a meaningful information exchange. To the extent that a meaningful exchange occurs the information exchanged can be effectively reused without human intervention. There is a direct correlation between the "agreed upon semantics and syntax rules" and the "meaningful exchange of information." Full stop.
"Agreed upon semantics" has two important aspects: structure and formalism. Both structure and formalism are aspects for classifying semantics and constitute the expressiveness of the semantics which have been agreed to.
Structure
There are many ways to capture the semantics, or meaning, of the things and the relations between the things which make up a domain. These are referred to as organizational systems or classification systems. These are several sorts of such systems:
- A controlled vocabulary or dictionary can provide a good list of things but tends to be weaker at expressing the relations between the things. A controlled vocabulary is basically a set of standard terms. Also, the properties of each of the terms is generally limited.
- A taxonomy or classification system adds the notion of a hierarchy between the members of a controlled vocabulary. For example, the terms "horse" and "cat" and "dog" are all types of "mammals". So, you have a good list of things the general sorts of relations between those things.
- Something like a thesaurus provides a specific type of relationship, a similar term, a broader term, or a narrower term; between the pieces some controlled vocabulary. But again, only some sorts of relations are covered.
- An ontology allows you to define your controlled vocabulary, a very rich set of properties for the things within that controlled vocabulary, and your own types of relationships between the things in the vocabulary. Specific, explicit types of relationships rather than general "parent-child" type relationships.
Formalism
Creating a structured system can be more formal, or less formal.
The graphic below shows the "bridging role" that something like an ontology plays between a domain and the content of that domain. Every ontology attempts to “define” and bound a domain. The graphic tries to highlight the trade-off between semantics v. pragmatic considerations.

As pointed out above, the different types of organizational systems have more, or less, expressive power. The more expressive power, the more time and money it takes to achieve that expressiveness and the higher the semantic clarity of the organizational system which one might create. This is represented graphically below:
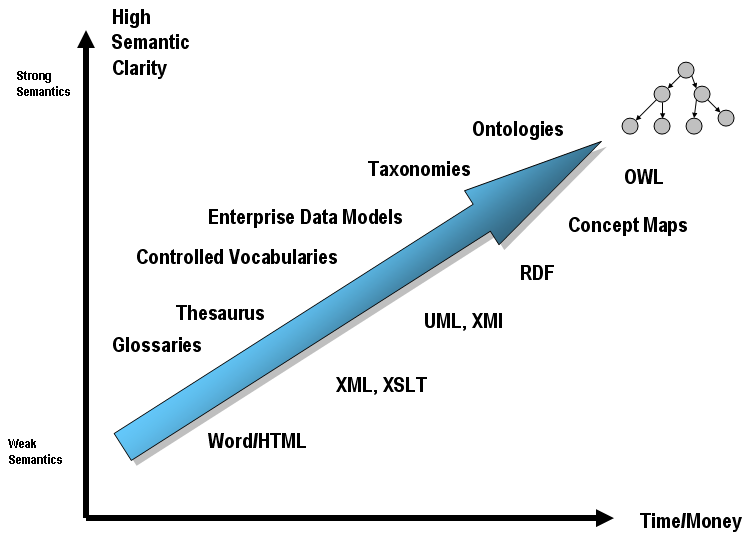 Based on work by Leo Obrst of Mitre as interpreted by Dan McCreary, we can view this as a trade-off as one of semantic clarity v. the time and money required to construct the formalism - See more at: http://www.mkbergman.com/date/2007/05/16/#sthash.mDBjSUHi.dpuf
Based on work by Leo Obrst of Mitre as interpreted by Dan McCreary, we can view this as a trade-off as one of semantic clarity v. the time and money required to construct the formalism - See more at: http://www.mkbergman.com/date/2007/05/16/#sthash.mDBjSUHi.dpuf
Information quality
And so, the quality of the information expressed can only be as good as the rules expressed which force the information to be correct, particularly via automated verification processes enforced by computer software. Now, granted, you will always need some manual processes to make sure the information is correct, for example it is impossible for a an automated process to pick the correct metadata to assign to, say, some reported fact in a financial report. A computer process can help, but it cannot do everything. The more a computer can do, the more that can be automated. The more that can be automated, the higher the quality of the information created and the less time and money it takes to make sure the information is correct.
This is particularly true if there are thousands and thousands of different people are creating this information, for example such as the thousands of reporting entities creating something like an SEC XBRL financial filings using XBRL.
Any expression of these "things" and the "relations between the things" in an ontology or whatever the classification system must be in a form that business people understand. This must be true because only the business people which have expertise within the domain for which the organizational system is being expressed can tell you if the expression of those things and relations are correct.
By correct I mean a sensible, logical, consistent, complete, accurate. Each piece of something like a digital financial report must be correct and the relations between each piece must be correct. For example, "Assets = Liabilities + Equity" is true in the domain of financial reporting and therefore must be true in any expression of "Assets" and "Liabilities and Equity" in any financial report. This is a simple example to make a point, there are much more complicated situations. Only domain experts understand these situations.
The bottom line is this: if business users cannot create correct digital financial reports, for example an SEC XBRL financial filing, then those digital financial reports cannot be useful. If they are not useful, they will not be used.
Software must help business users be successful, software must be interoperable
Software can, will, and in fact is being built to help business users work with whatever classification system might be available. The higher the semantic expressiveness and clarity, the more the software will be able to do for the business user.
To solve the usability issues, a number of software vendors are already (and more will follow) creating their own proprietary "models". The XBRL Abstract Model 2.0 is helpful in assuring interoperability between these implementations, but it is not sufficient to assure semantic interoperability.
The wrong debate
There is a debate about which is the appropriate way to express XBRL information: (a) Inline XBRL is pushed by some, (b) Data Point Model (DPM) is pushed by others, (c) Global Filing Manual, not sure how that is going, (d) the SEC/US GAAP Taxonomy is similar to the Global Filing Manual approach.
However, this is the wrong debate. Not one of these approaches can offer definitive proof that it actually works to enable a meaningful exchange of information and none of these approaches addresses the fundamental fact that "meaningful exchange can only occur to the extent of prior existence of agreed upon semantics and syntax rules."
Syntactic rules and therefore syntactic interoperability at the XBRL technical syntax level is very good, it has been since about 2003 when XBRL International started building conformance suites. However, semantic interoperability still suffers, so information use suffers.
I would encourage XBRL International and software vendors to focus on enabling business users to achieve semantic interoperability to the level that syntactic interoperability was achieved.
To the extend semantic interoperability is achieved, meaningful exchange of information can occur.
Charlie
in Digital Financial Reporting, Modeling Business Information Using XBRL
|
Post a Comment
| Email
| Print
Looking at Characteristics Used to Describe Balance Sheet Facts in SEC XBRL Financial Filings
Until now I have been focused my analysis of SEC XBRL financial filings on concept usage. I am now expanding that to have a closer look at how filers use [Axis] within SEC XBRL financial filings to express characteristics used to describe reported facts. For this blog post I am focusing on balance sheets.
This is a list of 82 SEC filers who each provide balance sheets. Now, because XBRL requires an entity, a period, and a concept; every filer has to provide at least these 3 characteristics. The range of characteristics goes from 3 to 7. Why?
First off, let me quickly explain the terminology which I am using. (All my terms are defined on the Financial Report Ontology wiki.)
- Fact. A fact defines a single, observable, reportable piece of information contained within a financial report, or fact value, contextualized for unambiguous interpretation or analysis by one or more characteristics.
- Characteristic. A characteristic provides information necessary to describe a fact. A fact may have any number of characteristics.
- Axis. An axis is a means of providing information about the characteristics of a fact reported within a financial report. An [Axis] is a class of report element used by the US GAAP Taxonomy and therefore in SEC XBRL financial filings. (The term used in XBRL for [Axis] is dimension which is defined by the XBRL Dimensions Specification as, "Each of the different aspects by which a fact may be characterized.")
So why the variation between what characteristics SEC XBRL filers report? Well, let's have a look.
As I said three characteristics are required: Entity, period, and concept. XBRL requires this. Entity, or more appropriately reporting entity or the CIK number of the filer is used on 82 out of 82 SEC XBRL financial filings. Period or again more precisely calendar period is likewise used on all 82 filings I looked at. The concept is also required and used by all 82 filers for all reported facts. So, all 82 filings consistently use those characteristics on every balance sheet fact.
Focus on that statement for a moment, "every balance sheet fact." That is important to understand. Characteristics defined relate to every fact within that component.
A popular characteristic is "Legal Entity [Axis]", it is used by 20 of the 82 SEC filings I looked at? why only 20, why not all 82? What is the legal entity of the other 62 reporting entities? What does this mean, that the others don't have a legal entity? No. If a legal entity axis is not provided, then the legal entity of "consolidated entity" is assumed per SEC XBRL filing rules in the EFM. So whether you do, or do not, provide the legal entity [Axis], users of the information will either explicitly or implicitly understand which legal entity a filer is talking about.
Another popular [Axis] is the "Class of stock [Axis]" (us-gaap:StatementClassOfStockAxis). Of the 82, a total of 13 used that [Axis]. Remember what I said about the characteristic expressed by the [Axis] for a component (i.e. within a [Table]) being applicable for all the facts within that component/[Table]? Well, in my view the way the class of stock [Axis] is being used is a mistake. Cash and cash equivalents, total assets, long-term debt, and other stuff found on those balance sheets should not be characterized by the class of stock [Axis]. A breakdown of the details of some category of stock using this axis, sure. But not the entire balance sheet. This is a modeling mistake. Chrysler, which has capital units, did a similar thing as those who modeled class of stock, they just used Capital Units [Axis] (us-gaap:CapitalUnitsByClassAxis).
The next most popular [Axis] is the "Reporting Scenario [Axis]" (us-gaap:StatementScenarioAxis). 11 filers used this [Axis]. Interestingly, of the 11; all 11 used the member of the [Axis] (or the value of the characteristic) "scenario unspecified". What is the reporting scenario which should be assumed per SEC EFM filing rules? Nothing is said. In my view, using this [Axis] is a modeling mistake. It helps nothing.
Three filers used the "Variable Interest Entities, by Classification of Entity [Axis]" (us-gaap:VariableInterestEntitiesByClassificationOfEntityAxis). This seems reasonable, however the name of the [Axis] is not reasonable. The phrase "...by Classification of Entity..." is not necessary in the name of the [Axis]. That explains what the [Axis] does, not what the [Axis] is. "Variable interest entity [Axis]" would be more appropriate in my view. This is a common issue on [Axis] within the US GAAP Taxonomy. But the [Axis] itself does seem reasonable. What is assumed if it does not appear? No variable interest entities exist which need to be reported. Comparability should be fine.
One filer, American Express, created an extension to define the axis "Error Correction And Prior Period Adjustments Restatement By Restatement Period And Amount [Axis]". This is an error in my view. First, for something as common as a restatement, no one should need to create an extension concept. Second, the "thing that moves" in a restatement is the report date. Therefore, the report date [Axis] is what should have been used. The "Report Date [Axis]" already exists in the US GAAP Taxonomy. In my view, this is a modeling mistake.
Berkschire Hathaway created an extension axis "Financial Segments [Axis]" but does not define what a financial segment is as compared to a Business Segment [Axis], which does exist in the US GAAP Taxonomy. Not sure what to think about that. I can sort of see the rational. The information is comparable and properly modeled. So I guess I would see no problem with this. But hold on a minute; in the business segment disclosure, they also used that same extension axis. Nope, this is a modeling error. Should have used the existing business segment axis.
Ford created an extension axis "Business Sectors [Axis]". This seems to be the same deal as the extension created above. Looking at the disclosures, business segment breakdown...Ford uses the same extension axis. Yeah...no; this is a modeling error. No need for that extension axis. Besides, if you look at the balance sheet in the HTML document and compare that to the XBRL, I am not sure what the creators of this balance sheet were thinking. I would avoid using the Ford balance sheet as an example.
Again, have a look of the 82 SEC filers which I took a look at for yourself. I am going to do a more comprehensive analysis of [Axis] for the balance sheet and other components after all the 10Ks get filed.
The bottom line for me is that the SEC filers have a lot of adjustments which need to be made with their [Axis] use. Use of the information by analysts is really the ultimate test. As long as more information is provided and as long as how the [Axis] are used do not hinder analysis; then I think more detail really does not hurt anything. But, using existing [Axis] is far better than creating extension report elements.
Charlie
in Modeling Business Information Using XBRL
|
Post a Comment
| Email
| Print

