Four Common Mistakes Related to Understanding Artificial Intelligence
There are four common mistakes that I see made over and over by both business professionals and technical professionals related to understanding and harnessing the capabilities of artificial intelligence:
- Having a "data" oriented perspective as contract to an "information" oriented perspective. (DIKW Pyramid)
- Not properly understanding the correlation between expressiveness and reasoning capacity. (Ontology Spectrum)
- Underestimating the power of "classification" and not understanding how software leverages classification. (Classification)
- Misunderstanding a machine’s capabilities to acquire knowledge. (Knowledge Aquisition)
The following sections explain each of these four mistakes and information about how to overcome each mistake:
Having a "data" oriented perspective as contract to an "information" oriented perspective
Information is data in context. That context information is generally not stored in a relational database. The graphic below shows the context information which are basically additional business rules that explain the data in more detail, put that data into context, turn the data into information, and then allow the information to be understood by or exchanged between software systems. To understand the difference between "data" and "information", see the DIKW Pyrimid. To overcome this mistake, think "information" rather than "data".
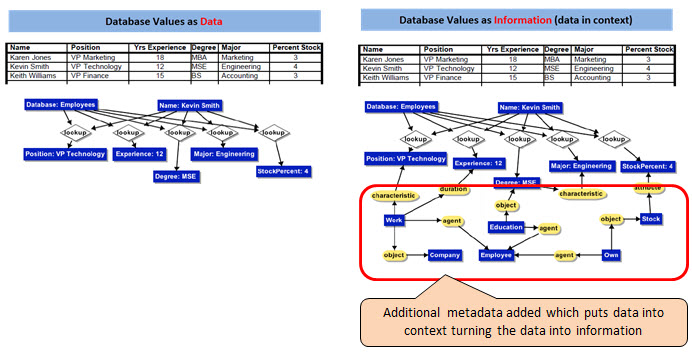 (Click image for larger view)
(Click image for larger view)
Not properly understanding the correlation between expressiveness and reasoning capacity
There is a direct correlation between the expressiveness provided by a taxonomy, ontology, logical theory, or some other classification method and the reasoning capabilities that can be achieved within software applications. The more expressive such a classification system is, and the more of that knowledge that is put into machine-readable form; the more powerful the reasoning capabilities of software applications which can read that machine-readable information. Further, if you have gaping holes in what is expressed in your taxonomy/ontology and you therefore don't meet the needs of the application you are trying to create you will experience quality problems. For more information see the ontology spectrum. Make sure you don't have an impedance mismatch between the taxonomy/ontology you create and the application you are using that taxonomy/ontology for.
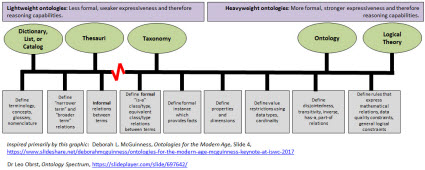
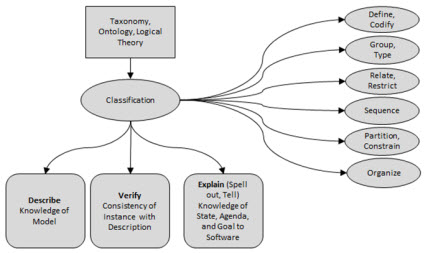
Underestimating the power of "classification" and not understanding how software leverages classification
Classification provides three things: First, you can "describe" the model of something. Second, you can use that description of the model to "verify" an instance of the model of something against that description. To the extent that you have machine-readable rules, that verification process can be automated. Third, you "explain" or spell out or tell a software application (software algorithm, AI) knowledge about the state of where you are in your agenda of tasks necessary to meet some goal. To the extent that you have machine-readable rules, software can assist human users of the software in completing the tasks in their agenda and achieving that goal. For more information see this blog post on the power of classification. Recognize that formal is better than informal and more is better than less.
Misunderstanding a machine’s capabilities to acquire knowledge
The utility of a "thick layer of metadata" (i.e. classifications) is not disputed. What is sometimes disputed is how to best acquire that thick layer of metadata. Basically, there are three approaches:
- Have a computer figure out what the metadata is: (machine-learning, patterns based approach) This approach uses artificial intelligence, machine learning, and other high-tech approaches to detecting patterns and figuring out the metadata. However, this approach is prone to error.
- Tell the computer what the metadata is: (logic and rules based approach) This approach leverages business domain experts and knowledge engineers to piece together the metadata so that the metadata becomes available. However, this approach can be time consuming and therefore expensive.
- Some combination of #1 and #2: Striking the correct balance and creating a hybrid approach where humans and computers work together to create and curate metadata.
Note that machine learning is prone to error. Also, machine learning requires training data. Machine learning works best where there is a high tolerance for error. Machine learning works best for: capturing associations or discovering regularities within a set of patterns; where the volume, number of variables or diversity of the data is very great; where the relationships between variables are vaguely understood; or, where the relationships are difficult to describe adequately with conventional approaches.
This PWC article is an excellent tool and helps you understand how to think about artificial intelligence. This article helps you better understand machine learning. For more general information, please see Computer Empathy.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments