BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from May 1, 2019 - May 31, 2019
Four Common Mistakes Related to Understanding Artificial Intelligence
There are four common mistakes that I see made over and over by both business professionals and technical professionals related to understanding and harnessing the capabilities of artificial intelligence:
- Having a "data" oriented perspective as contract to an "information" oriented perspective. (DIKW Pyramid)
- Not properly understanding the correlation between expressiveness and reasoning capacity. (Ontology Spectrum)
- Underestimating the power of "classification" and not understanding how software leverages classification. (Classification)
- Misunderstanding a machine’s capabilities to acquire knowledge. (Knowledge Aquisition)
The following sections explain each of these four mistakes and information about how to overcome each mistake:
Having a "data" oriented perspective as contract to an "information" oriented perspective
Information is data in context. That context information is generally not stored in a relational database. The graphic below shows the context information which are basically additional business rules that explain the data in more detail, put that data into context, turn the data into information, and then allow the information to be understood by or exchanged between software systems. To understand the difference between "data" and "information", see the DIKW Pyrimid. To overcome this mistake, think "information" rather than "data".
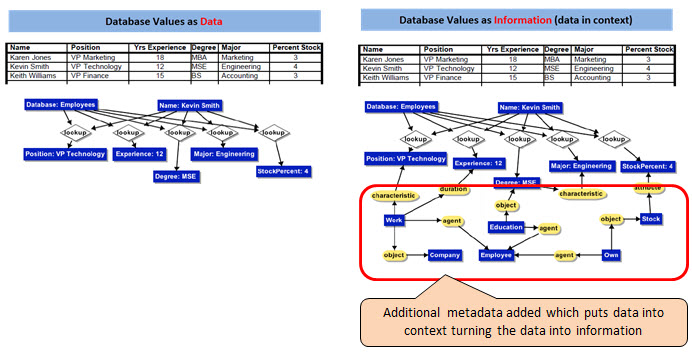 (Click image for larger view)
(Click image for larger view)
Not properly understanding the correlation between expressiveness and reasoning capacity
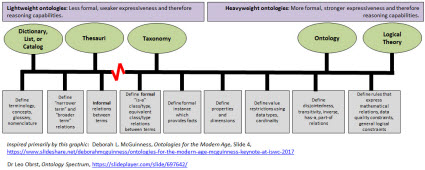
There is a direct correlation between the expressiveness provided by a taxonomy, ontology, logical theory, or some other classification method and the reasoning capabilities that can be achieved within software applications. The more expressive such a classification system is, and the more of that knowledge that is put into machine-readable form; the more powerful the reasoning capabilities of software applications which can read that machine-readable information. Further, if you have gaping holes in what is expressed in your taxonomy/ontology and you therefore don't meet the needs of the application you are trying to create you will experience quality problems. For more information see the ontology spectrum. Make sure you don't have an impedance mismatch between the taxonomy/ontology you create and the application you are using that taxonomy/ontology for.
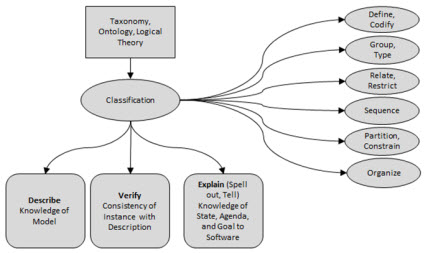
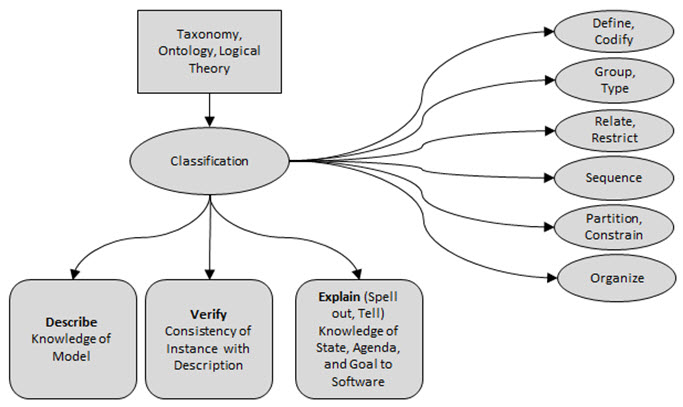
Underestimating the power of "classification" and not understanding how software leverages classification
Classification provides three things: First, you can "describe" the model of something. Second, you can use that description of the model to "verify" an instance of the model of something against that description. To the extent that you have machine-readable rules, that verification process can be automated. Third, you "explain" or spell out or tell a software application (software algorithm, AI) knowledge about the state of where you are in your agenda of tasks necessary to meet some goal. To the extent that you have machine-readable rules, software can assist human users of the software in completing the tasks in their agenda and achieving that goal. For more information see this blog post on the power of classification. Recognize that formal is better than informal and more is better than less.
Misunderstanding a machine’s capabilities to acquire knowledge
The utility of a "thick layer of metadata" (i.e. classifications) is not disputed. What is sometimes disputed is how to best acquire that thick layer of metadata. Basically, there are three approaches:
- Have a computer figure out what the metadata is: (machine-learning, patterns based approach) This approach uses artificial intelligence, machine learning, and other high-tech approaches to detecting patterns and figuring out the metadata. However, this approach is prone to error.
- Tell the computer what the metadata is: (logic and rules based approach) This approach leverages business domain experts and knowledge engineers to piece together the metadata so that the metadata becomes available. However, this approach can be time consuming and therefore expensive.
- Some combination of #1 and #2: Striking the correct balance and creating a hybrid approach where humans and computers work together to create and curate metadata.
Note that machine learning is prone to error. Also, machine learning requires training data. Machine learning works best where there is a high tolerance for error. Machine learning works best for: capturing associations or discovering regularities within a set of patterns; where the volume, number of variables or diversity of the data is very great; where the relationships between variables are vaguely understood; or, where the relationships are difficult to describe adequately with conventional approaches.
This PWC article is an excellent tool and helps you understand how to think about artificial intelligence. This article helps you better understand machine learning. For more general information, please see Computer Empathy.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Understanding the Power of Classification
It was the Greek philosopher Aristotle (384-322 B.C.) that first came up with the idea of classifying plants and animals by type, essentially creating the notion of a hierarchy or taxonomy. The idea was to group types of plants and animals according to their similarities thus forming something that looked like a "tree" with which most people are familiar.
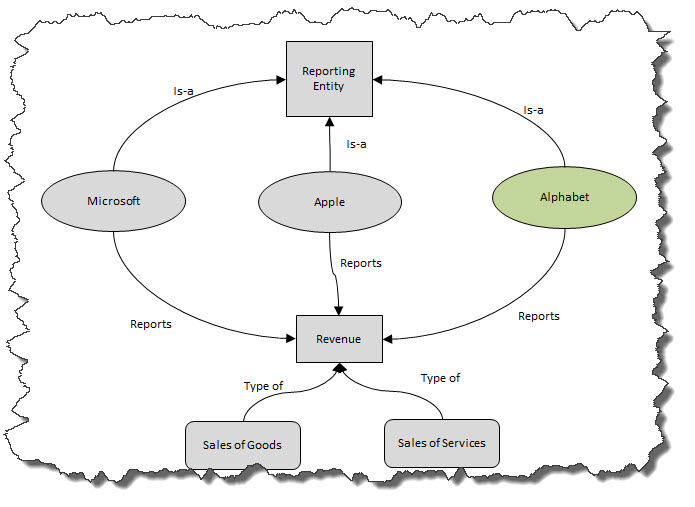
People tend to be less familiar with the notion of a "graph". A tree, or hierarchy, is actually a type of graph. Trees/hierarchies tend to be easier to get your head around. But the real world can be more complicated than the rather simple relations that can be represented by trees/hierarchies. Here is a simple example:
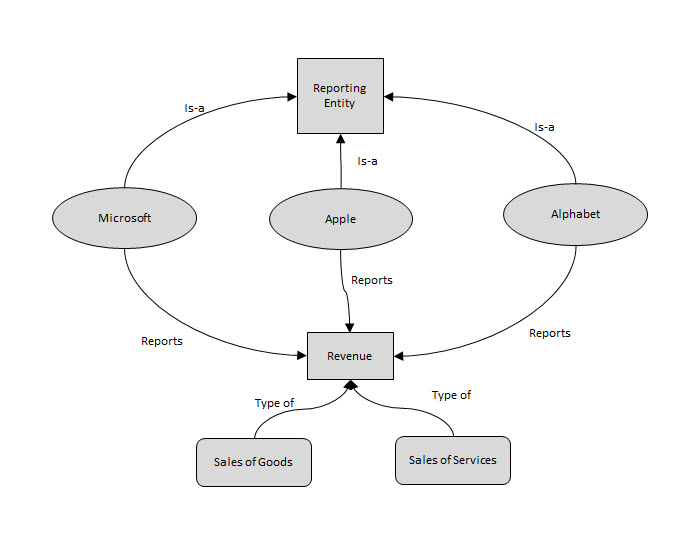
(Click image for larger view)
When you use some formal, explainable nomenclature (a system of naming) to define things; then you can uniquely idenfity and refer to those things. If you go a step further and classify those things by formally defining relations between those things you can do even more. Some types of formal relations include: Is-a, Has-a, Part-of, Part relations, Class relations, Subclass, Disjunction, Transitive.
And so classification helps you work with the "things' and the "relations between things". Put this information into machine-readable form and what looks like magic can occur.
Classification provides three things: First, you can “describe” the model of something. Second, you can use that description of the model to “verify” an instance of the model of something against that provided description. To the extent that you have machine-readable rules, that verification process can be automated. Third, you “explain” or spell out or tell a software application (software algorithm, AI) knowledge about the state of where you are in your agenda of tasks necessary to meet some goal. To the extent that you have machine-readable rules, software can assist human users of the software in completing the tasks in their agenda and achieving that goal. That is what is meant by "AI is taxonomies and ontologies coming to life."
(Click image for larger view)
And so how do you get all these terms and classification which helps you understand the relations between the terms? As explained in this article by PWC, you create them. That is what they mean by "you have to label the data". They did not explain that particularly well, but that is the reality. While it is true that eventually machines will be able to do some of this classification, machines first need to be trained. Machines need training data. There are different types of machine learning.
To get the best results the definition of terms and classification of those terms should be formal rather than informal. Formal puts you higher on the ontology spectrum. Done correctly, you can create powerful software tools that can reliably leverage the machine-readable terms and classifications.
And that, in a nutshell, is the power of classification. Or, that will help you understand why poor classifications or informal, unusable classifications inhibit functionality.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Complex Systems
As was pointed out in Object-Oriented Analysis and Design with Applications (page 28), the role of a software development team is to engineer the illusion of simplicity.
As stated starting on page 12 here, and similarly here, by Grady Booch, there are five common characteristics to all complex systems:
- There is some hierarchy to the system.
- The primitive components of a system depend on your point of view.
- Components are more tightly coupled internally than they are externally.
- There are common patterns of simple components which give rise to complex behaviors.
- Complex systems which work evolved from simple systems which worked.
The process of defining requirements usually results in incomplete specifications and incorrect specifications. A study in 1999 of requirements specifications found that they are typically only 7% complete and 15% correct.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
AI is Taxonomies and Ontologies Coming to Life
PWC makes the following statement in this article: "artificial intelligence (AI) has the power to change almost everything about the way they do business". You might ask, "How?"
In her presentation, AI and Machine Learning Demystified, Carol Smith makes the following statement on slide 12:
"AI is taxonomies and ontologies coming to life."
I could not agree with her more. But I would say this a bit more precisely. It is not that just any old thing called a "taxonomy" or "ontology" is what you need. You want formal, machine-readable, highly expressive taxonomies and ontologies. Artificial intelligence (AI) works by providing context that the AI can make use of. Taxonomies and ontologies are about classification. Classification turns unusable "dark data" into knowledge and understanding. While sometimes it is possible to let machines create classifications using clustering techniques of machine learning; for complex knowledge domains, like financial reporting, humans need to create the classifications. Once you get a solid foundation, then the machine learning processes can leverage the human created information and you get a hybrid approach to expanding taxonomies and ontologies. Basically, it is taxonomies and ontologies that enable the creation of machine-readable knowledge. For example:
(Click image for larger view)
And so that is exactly why I created the framework that I did. It is that knowledge that enables Pesseract to do what it does. This is what is meant by the statement "stronger expressiveness and therefore reasoning capabilities" per the ontology spectrum.
Using the thick metadata layer provided by the framework, a business rules processing engine, and mechanisms to present information in human readable form things like this and this and this can be created. Essentially what you can get is similar to the logic and rules-based approach of imlementing artificial intelligence that is similar to the functionality of TurboTax. (Does not work exactly the same, TurboTax is a form; but a financial report is not a form.)
Over the coming years as people see more and more software effectively automating tasks they will come to learn that AI will have a significant impact. PWC points out that most business leaders have no clue how to implement AI within their organizations. This ignorance on the part of business leaders will lead to wasted money when the snake oil salesmen come around and try and sell you "AI". It will also result in many business leaders acting either too soon, too late, or going the wrong direction when trying to adapt to this inevitable, and immanent, new paradigm.
"Know how" is a type of knowledge. PWC offers some excellent advice that will help you and your organization maximize their ROI or AI. Where do you start to turn ignorance into know how? Computer Empathy is the summary that I created from my lab notes.
If you are still having a hard time getting your head around all this, check out this video about how self driving cars work. Or this video.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding Answer Set Programming
So you have a thick metadata layer that describes reports, you have highly-expressive ontologies that describe reported information, and you have all the reported facts themselves that are provided in the report. But you are still missing two things from your knowledge based system.
- You need software to process all that information (i.e. rules engine).
- You need a mechanism to help the user of the software understand the results of the processing (i.e. justification mechanism).
As I pointed out before, XBRL Formula processors have specific defeciencies in their capabilities so they alone will not do.
So what do you do?
Well, you could build your own rules engine to process everything. After all, everything distills down to logic gates that are used for processing. What it is possible to build your own rules engine, creating a rules engine is not a trivial task.
What about using existing processing tools? That can work. You could convert everything to the semantic web stack of technologies and use existing semantic reasoners. That could work.
I thought that PROLOG or DATALOG could work. Those could work, but as I understand it PROLOG uses backward chaining and you will need forward chaining for many of the types of problems you need to solve.
Another approach that I have heard of is answer set programming. The best description of answer set programming that I have run across is this: (from Answer Set Programming: A Primerby Thomas Eiter, Giovambattista Ianni, and Thomas Krennwallner)
Answer Set Programming (ASP) is a declarative problem solving paradigm, rooted in Logic Programming and Nonmonotonic Reasoning, which has been gaining increasing attention during the last years.
The article Answer Set Programming at a Glance by GERHARD BREWKA, THOMAS EITER, AND MIROSLAW TRUSZCZYNSKI explains the motivation benind and key concepts of answer set programming which is a promising approach to declarative problem solving.
Answer set programming seems to be related to PROLOG.
There are free answer set programming processors such as Potassco. (you can download Potassco here) DLVHEX is another. Here is a comparison of implementations.
You can do an online demo here.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

