BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from November 1, 2020 - November 30, 2020
Logical English
Logical English is explained by Robert Kowalski Akber Datoo in the following goal:
Goal: The ultimate goal of Logical English is to serve as a general-purpose computer language, which can be understood by a reader without any training in computing, logic or mathematics. It is inspired in part by the language of law, which can be viewed as a programming language that is executed by humans rather than by computers.
You can get more details that explain Logical English here in this presentation by Robert Kowalski.
Accounting is also a language, the language of business. While the language of accounting might not have inspired Logical English, it can definitely leverage it. Others are creating languages for processing XBRL-based financial reports. XULE, created by XBRL US, is one example. To understand XULE, see this guide and these examples provided by XBRL US. Pacioli has its language. XBRL Formula has its language also. Sphinx is another proprietary language provided by CoreFiling. There are many more general and specific approaches to processing machine-readable information.
The question is not whether IF this sort of processing will be the way things are done in the future in accounting, reporting, auditing, and analysis. Computational professional services is inevitable. The question is: how to you get all this to work effectively. Here is how I get all this to work today including proof THAT it actually works effectively. How will all this work in the future? Maybe Logical English or something like Logical English.
For more on this, consider having a look at the special purpose model that I have created for financial reporting:
- Essence of Accounting
- Computational Thinking
- Computational Professional Services
- Logical Theory Describing Financial Report
Perhaps someone will distill all this down into a special purpose language for accounting, reporting, auditing, and analysis. Or, maybe a subset of Logical English will work. The more specific the language the easier it is to create and use. The more general, the harder it will be to use but the more powerful the language will be. Striking the right balance between general and specific is important to get the right balance between "ease of use" and "power" and "reliability" and "maintainability".
 Charlie
in Digital Financial Reporting
|
Charlie
in Digital Financial Reporting
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Pacioli Import
Pacioli has a lot of new functionality. One of the new features is the ability to import CSV. You can try this out yourself by doing the following:
- Download this ZIP archive that contains 9 CSV files and put it somewhere on your local computer. (This has the PROOF representation.)
- Go to this URL which allows you to Import into Pacioli.
- Either copy and then paste or drag and then drop the files from your local computer into the import page above. (you can either upload the one ZIP file or each file individually, does not matter)
- Press the "Import" button on the web page.
- You will get (a) a validation report that shows everything is logically valid which you can download and (b) an XBRL instance, XBRL taxonomy schema, XBRL linkbases, and XBRL formulas that was generated from the CVS. (The XBRL syntax is not dialed in yet, but it will get there very soon.)
- Try these two other simpler examples to understand the import format: Accounting Equation | SFAC 6 Elements of Financial Statement
- Modify the Proof, Accounting Equation, or SFAC 6 examples and try importing that.
You can create literally any XBRL-based financial report using CSV formatted similarly. We will document this to make it more understandable. Clearly you would not want to hand create CSV files, that is not the point. Luca also supports that same format using in the CSV.
Back to connecting the dots!
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
The Data-Centric Future Is Here, It Is Just Not Evenly Distributed
This interview of Alan Morrison of PriceWaterhouseCoopers is one of the best articles I have read in quite a while: The Data-Centric Future Is Here, It Is Just Not Evenly Distributed: A Dialogue with Alan Morrison, by Teodora Petkova.
Here are some interesting excerpts: (the entire article is worth reading, takes about 15 minutes)
Standards:
“There’s no machine understanding without shared semantics, and no shared semantics without standards.”
Drunk looking for his keys:
That problem, in other words, is the “drunk looking for his keys under the lamppost” problem. “Why are you looking under the lamppost, if you think your keys are over there in the dark?” he’s asked. “Because under the lamppost is where the light is,” the drunk answers.
Bits and bytes in buckets:
In reality, “knowledge”, “content” and “data” are all the same thing to a machine–bits and bytes in buckets that represent people, places, things and ideas. These representations are often poorly described.
Semantic Web:
We were quite bullish on the semantic web back then. In retrospect, there were four things we didn’t account for enough in our forecast:
- How alien the semantic web methods would be to enterprise IT and data management shops;
- How often enterprises couldn’t see the forest for the trees because of their preoccupation with applications, rather than interacting with data/information/knowledge more directly.
- How much tribalism and just pure ignorance or unwillingness of one tribe to learn from other tribes inhibits how technology evolves, and
- How much compute, networking and storage would have to improve to operationalize compute-intensive semantic graphs at scale. Eleven years later, enterprises are still struggling with these problems.
Knowledge Graphs:
A commitment to knowledge graphs gives these three groups the opportunity to share one method and one toolchain to contextualize and better describe data, content and knowledge as commonly modeled representations. The right leader can understand this bigger picture and break down the barriers between the teams and departments.
Utility of a method:
The key challenge is how to update and broaden the mentality of the organization with whatever methods you’re using. The compulsion for most is to see every problem as a nail and use RDBMSes as a hammer, along with the associated one database per application development habit, are just plain wasteful. The impulse for most is to look first to an RDBMS, because that’s what’s been comfortable for most.
Waste:
Companies are spending 10 to 100 times more on development than they need to, he says.
Need for a "guerilla team":
Thus the need for a guerilla team inside each organization, people who do have the passion and knowledge, a team that has leadership backing. That passionate core needs to exist in every company serious about data/information/knowledge-centric transformation.
Software Wasteland (book)
"This is the book your Systems Integrator and your Application Software vendor don't want you to read. Enterprise IT (Information Technology) is a $3.8 trillion per year industry worldwide. Most of it is waste."
Charlie
in General Information
|
Post a Comment
| Email
| Print
Engine B Common Data Model (CDM) V1.1
Engine B published their industry standard Common Data Model v1.1 on GitHub in the JSON format. Here is how Engine B explains their CDM.
I took the liberty to convert that JSON to XBRL, created several instances for testing purposes, and did a bunch of other stuff. You can have a look at what I put together here.
Amoung other things, note that I took the Microsoft Dynamics Sample Company (The World Online), loaded that onto an SQL Server, mapped the Dynamics tables to the CDM, and then generated XBRL instances for all of that data. You can download and have a look. This is what the SQL looks like: (first you see the Dynamics table, then you see the alias created which is the CDM field)
SELECT dbo_RM00101.CUSTNMBR AS customerId, dbo_RM00101.CUSTNAME AS name, dbo_RM00101.CUSTCLAS AS customerType, dbo_RM00101.ADDRESS1 AS addressStreetName, dbo_RM00101.CITY AS addressCity, dbo_RM00101.STATE AS addressRegion, dbo_RM00101.ZIP AS addressPostalCode, dbo_RM00101.COUNTRY AS addressCountry, dbo_RM00101.PHONE1 AS telephone, dbo_RM00101.FAX AS fax, dbo_RM00101.TAXSCHID AS taxType, dbo_RM00101.USERDEF1 AS customerGroup, dbo_RM00101.MODIFDT AS systemModifiedDateTime FROM dbo_RM00101;
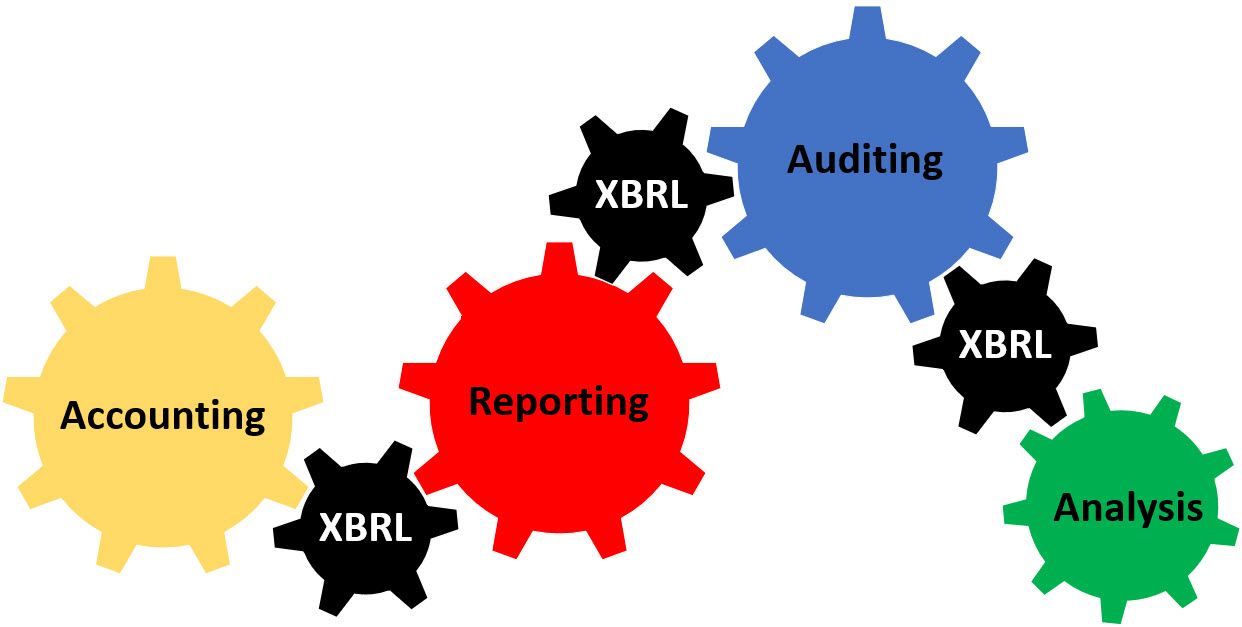
It is really that easy. This stuff is going to be so great when computational professional services is all up and working! "Always on" audits!!!
Might want to consider brushing up on your computational thinking.
############################
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Microsoft Dynamics 365 Supports XBRL
Microsoft Dynamics 365 accounting system now supports XBRL. I have not looked into this yet but will.
Other accounting systems and reporting tools support XBRL:
- Oracle Financials
- SAP
- CaseWare Working papers which flows into CaseWare Financials
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print

