BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from June 15, 2014 - June 21, 2014
Calcbench Analysis Shows SEC XBRL Filing Errors
An analysis provided by Calcbench shows three types of common errors in SEC XBRL financial filings:
- Sign switches (about 50% of filings), which is reporting the incorrect polarity of a number such as reporting a negative number which should have been positive
- Scale errors (about 8% to 12% of filings), which is reporting 5 when the number 5000 should have been reported
- DEI errors (about 3% of filings), such as incorrect infomation for the fiscal period, fiscal year, or document balance sheet date
For more information on errors, you can see my analysis of a basic set of minimum criteria here necessary to make safe, reliable, repeatable, predicatable use of SEC XBRL financial filings. Details which explain each of those minimum criteria can be found here.
Digitizing Disclosures (Part 2)
This blog post builds upon the post Digitizing Disclosures (Part 1). In Part 1 I shows that a disclosure can be broken down into pieces. Some people call this "structured", I call it "digitizing" the information. In this part I try and paint the big picture and point out the advantages of digital financial reporting and point out where we fall short today. Part 3 will show exactly how disclosures are digitized, how business rules help quality, and how to create an automated digital version of a disclosure checklist.
This is a summary of the pieces which you want to keep straight in your mind.
First, external financial reporting managers and other such accountants create reports such as financial reports. I am focusing on financial reports as an example because I am an accountant. But these ideas also follow for other types of reports.
Second, these reports are can be very complex. There is lots of information which must be correct, complete, consistent, and accurate. To make a mistake is to risk noncompliance with laws/regulations. How do the accountants who create and publish this information get the job done?
- Vast amounts of knowledge and skill they have crammed into their brain
- Resources which the accountants use to find the things that don't know off the top of their head, for example a disclosure checklist which they use as a memory jogger
- Lots and lots of manual effort
- Software publishing tools which has zero knowledge of financial reporting; these tools may have some information extraction capabilities and/or content management capabilities, but they truly know nothing about financial reporting
Why is this process used? Well, because up until now there has been no other alternative. How might this alternative work:
- Take as much knowledge of financial reporting as possible (necessary) and put that information in not only human readable form, but also into machine readable form
- Take other resources which accountants use and put that into human readable and machine readable form also
- Manual effort, but replace as much manual effort as possible with automated processes
- Use software which leverages the machine readable information which has been expressed about how to correctly, completely, consistently and accurately create a financial report and therefore can appear to understand financial reporting and actively assist and even guide an accountant through that process of creating a financial report
Note that I am NOT saying that this process will be 100% automated, NOT saying that computer will exercise judgment because they cannot, NOT saying professionals will be eliminated from the process; what I am saying is that what can and should be automated will be automated and what cannot be automated or should be manual will be manually performed by humans.
How is this possible? Magic? There is zero magic involved. Artificial intelligence? No artificial intelligence at work. Hard work and attention to detail? Lots of that. Beating down complexity by simplifying as much as possible? Yes. And I don't mean make things simplistic. Simplicity and elegance are the ultimate sophistication. Simplifying is extremely hard work.
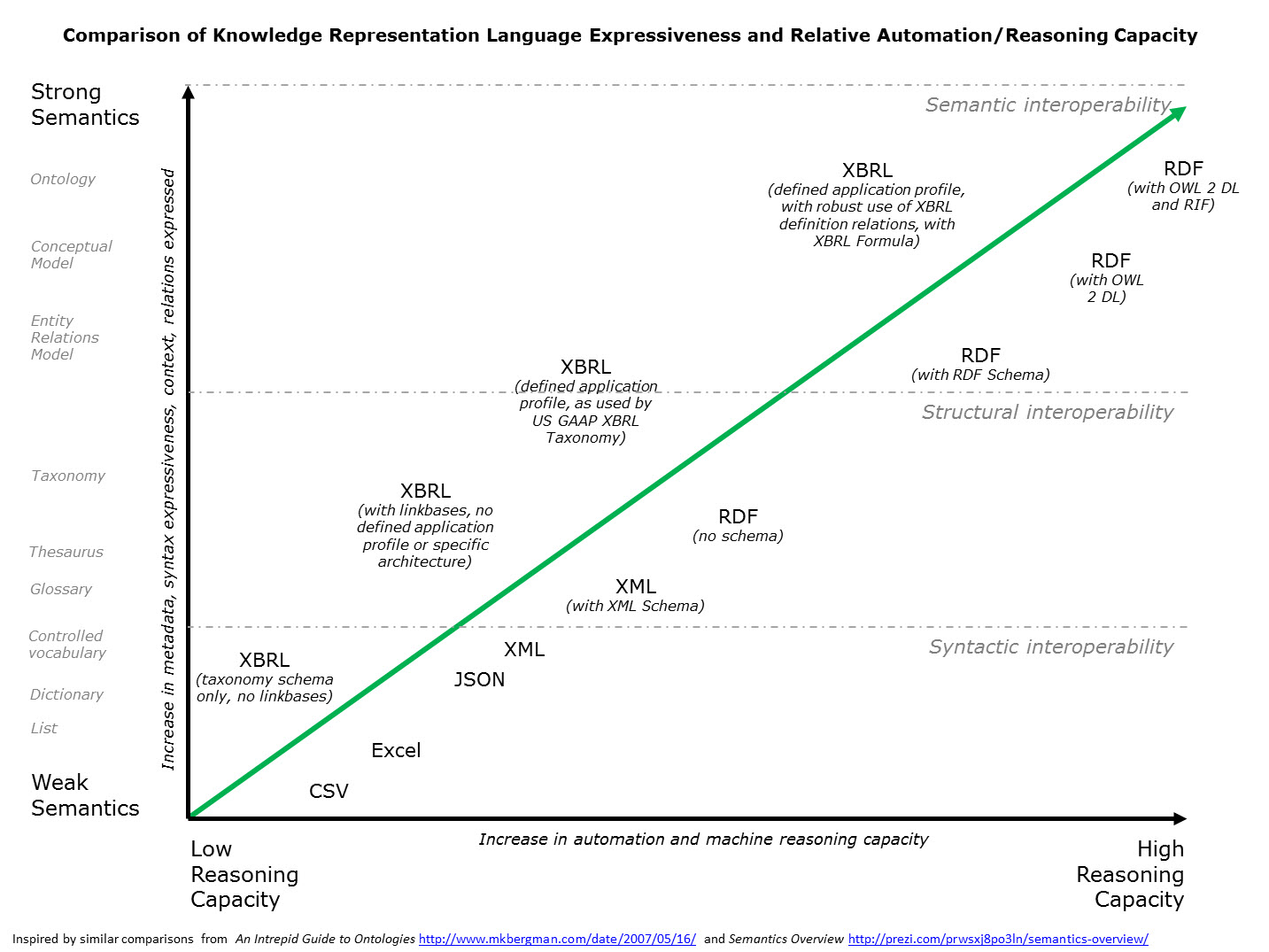
This graphic explains visually how this will be achieved:
 (Click image for larger view)
(Click image for larger view)
Here is the narrative with walks you through the graphic.
First, there are a lot of different ways to express information in a machine readable format: CSV, Excel, JSON, XML, XML plus an XML Schema, RDF, RDF with a schema, RDF with a schema and ontology, or XBRL. The XBRL syntax is a global standard format for doing this.
Next, you take all the things which make up a financial report and you express them in a machine readable form, such as the way the US GAAP XBRL Taxonomy does this for US GAAP and the IFRS XBRL Taxonomy does this for IFRS. Eventually other taxonomies will do this same thing for State and Local Governmental financial reporting. The specific format matters less, what matters more is how much meaning or "semantics" which you can pack into machine readable form. You need all the "things" and the "relations between the things" which make up a financial report. Not everything related to accounting and reporting, just the stuff that ends up in a report.
If you notice the graphic, you can see that there is a correlation between the level of semantics (weak or strong) and the reasoning capacity of a machine such as a computer (low or high).
Part of the necessary semantics are the relations between the things in a financial report. One of the things which plagues SEC XBRL financial filings to day are errors in the relationships. The following succinct statement summarizes the reason why data quality problems exist in SEC XBRL financial filings:
The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
Digitizing disclosures has little to do with XBRL mandates.
An external financial reporting manager needs to create external financial reports in an efficient and effective manner and insure compliance with legal requirements to minimize the risk of lawsuit, regulatory non-compliance, other reporting error, or other risk factor. Software companies began creating disclosure management software long before the SEC mandated reporting by public companies in the XBRL format. Clarity (now IBM FRS), Hyperion (now owned by Oracle), cundus (now owned by SAP), WebFilings, Trintech and others all were creating disclosure management systems before they retrofitted their software to support XBRL.
But each of these software solutions, while they can output XBRL formatted financial reports; none of these systems actually understands financial reporting semantics. This software does not fit the digital financial reporting bill because it does not provide the necessary functionality. For example, none of these software products, to the best of my knowledge, offers a digitized disclosure checklist which replaces the manual "memory jogger" approach.
I would argue that the market for disclosure management software, if it provided the correct functionality, is not the 10,000 public companies which file with the SEC. I personally see the market as being approximately the following in the United States alone:
- Those 10,000 public companies
- Private companies who provide audited or reviewed financial statements in support of commercial loans, I hear that there are between 14,000,000 and 24,000,000
- Not for profits who provide audits in support of grants, about 360,000 as I understand it
- State and local governmental entities required to create financial reports, about 90,000
But none of these reporting entities would ever purchase software that works the way software works today for creating SEC XBRL financial filings. That software provides no real benefit when working with structured information, only additional work. And besides, there is another problem: quality.
The XBRL syntax is fine, 99.9% of SEC XBRL financial filings have the proper XBRLtechnical syntax. Domain semantic rules are not even remotely sufficient, however, so the SEC XBRL financial filings have a boatload of quality problems. See the quote above, pretty straight forward. You can tell by the patterns in the errors that not one software application has the processes in place to systematically detect errors. Software has systemic process problems.
So, that is why quality issues exist in SEC XBRL financial filings, missing domain semantics rules or "business rules" they are commonly called. Plus, even if they magically existed, the software does not leverage those rules. The best that software today could do is run the rules after the digital financial report is created. That is helpful in creating proper XBRLformatted financial reports, but it is of no help in actually creating the report in the first place. The XBRL formatting is simply bolting on additional work to the end of an already complex process. What needs to change are the fundamental work practices.
Seem impossible? It is not impossible. Two things are necessary to make digital financial reporting work: (a) the metadata which assures a meaningful information exchange and (b) software which understands and leverages the metadata to guide the accountant in the process of creating a financial report. The software will be simple to use but will provide sophisticated functionality because the complexity of dealing with the thousands and thousands of individual pieces of a structured report and the relations between the structures are managed, behind the scenes, by the software.
While validation software such as XBRL Cloud's Edgar Dashboard or the SECXBRL.info validation of basic financial information is helpful, that validation needs to be imbedded in software so the software will not let business users make these mistakes. Further, this validation must be comprehensive. Rather than covering, for example, a set of minimum criteria; all aspects of every disclosure must be verified by creation software.
As I will show in Part 3 of this series, there is not that much of a difference between verifying the minimum criteria and verifying disclosures. Stay tuned.
To start thinking about this "digitation" process, first take a look at this HTML and this XML (here is a rendered version of the XML if you don't understand how to read the XML).
XBRL Definitions Prohibition Example
In my prior blog post I talked about how XBRL can be used to prohibit relations. So I created an example of this and show how it would be used. I will walk you through how I did this.
Here is the end result: XBRL Taxonomy Schema, XBRL Definition Relations. (Both of these should load into any quality XBRL tool. If you can use the Arelle GUI which is open source.)
So here is the use case. OK, there are some set of business rules which have been defined, organized, and generated in the XBRL format such as these which I used in that prior blog post. But those rules are somewhat LAX, you want a more STRICT set of rules. Say you want to do the following:
- You don't want to allow the concept us-gaap:LiabilitiesAndPartnersCapital because it has been deprecated
- You dont want to allow the concept us-gaap:CommonStockholdersEquity because it has also been deprecated.
- You don't want your company to use the concepts us-gaap:OrganizationConsolidationAndPresentationOfFinancialStatementsDisclosure, us-gaap:OrganizationConsolidationAndPresentationOfFinancialStatementsDisclosureAndSignificantAccountingPolicies, us-gaap:OrganizationConsolidationBasisOfPresentationBusinessDescriptionAndAccountingPoliciesDisclosure because you would prefer your organization to break each disclosure into the individual pieces, rather than pack several disclosures together.
Here is how you prohibit those relations which disallow those options:
- You create an empty XBRL taxonomy schema. Here is an example. That is just a schema which references the XBRL schema.
- You import the set of business rules you are using. That is the business rules from the previous example in this case.
- You save the schema then open it in your XBRL taxonomy editor and create new relations which prohibit the existing relations.
- You resave the schema and your XBRL taxonomy editor will automatically save the definition relations you articulated and link it to your taxonomy schema. (Again, this is the end result which is the same as above: XBRL Taxonomy Schema, XBRL Definition Relations)
Visually, what you created looks something like what my XBRL taxonomy editor shows in the graphic below:
 (Click image for larger view)
(Click image for larger view)
If you look at the XBRL definition relations, you will notice that you did not really delete anything. You cannot do that because you don't "own" the business rules. You cannot edit those. What you do is create new relations which prohibit the existing relations. You can see this if you look at the XBRL Definition relations, notice the use='prohibited' attribute on the definitionArc element.
That is all there is to it.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Understanding the Power of XBRL Graphs
Graphs are amazing little tools. When I say graphs, I mean the graph theory definition of a graph which is "structures used to model pairwise relations between objects". And in writing that, I don't know if it is the graphs that are amazing or if it is the formats used to represent graphs which is amazing.
This is what I mean.
RDF is an approach to expressing things using a graph-type format. Basically you represent what amounts to a flat list of stuff and then software which processes RDF organizes the flat list of stuff into relationships generally displayed in the form of a "tree". This offers a lot of flexibility.
Well, XBRL does the same thing. Or rather, XLink does the same thing and XBRL leverages XLink so in that way XBRL can express graphs. XBRL presentation relations, calculation relations, and definition relations are graphs.
So here is a very basic example. Below is a "tree" which represents information about financial reporting topics expressed using XBRL. This is the XBRL definition linkbase which expresses those relations.
 Topics
Topics
If you go look at the XBRL definition relations you will see that there is a flat list of stuff. The XBRL processor takes that flat list and renders a human readable view of the information.
So here is another set of XBRL definition relations which have information about financial reporting topics and also has information about financial disclosures. The disclosures refer to the topics in order to organize the disclosures into the related topic. (Here is the XBRL definition relations for the topics and disclosures.)
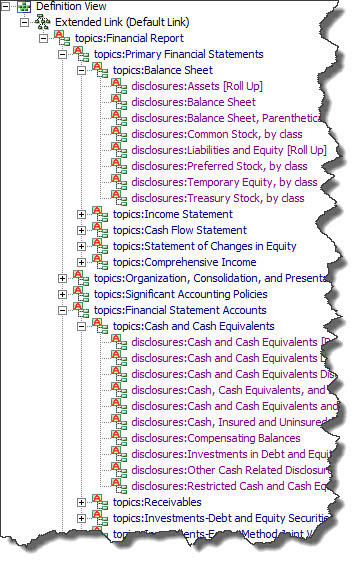 Topics plus Disclosures
Topics plus Disclosures
So basically, the list of topics and the list of disclosures are combined into ONE list. (Bear with me for a moment here.)
OK, so here is another list I created. This is interesting for two reasons. First, notice that the information is flat. Second, that is actually not just one XBRL definition linkbase. That is a set of about 221 XBRL definition linkbases which are combined together using this XBRL taxonomy schema. (Here is one example set of business rules, I will explain those in another blog post.)
 Business rules
Business rules
This is where things get really interesting.
Below you see the financial reporting topics, the financial disclosures organized by topic, and then the business rules that I created organized by financial disclosure. I put all those pieces together with this XBRL taxonomy schema. For good measure and so I can read the information using labels rather than just element names, I added the US GAAP XBRL Taxonomy and DEI Taxonomy labels.
 Topics, Disclosures, Business Rules
Topics, Disclosures, Business Rules
Because I organized the information correctly and paid attention to the extended link roles I used, all of these pieces are merged into one graph by the XBRL processor which displays that information. XBRL was designed this way in order to provide the extensibility which was required as a feature. Here you see that feature in action.
That may not seem like much, but when you think about it the utility of this starts to make sense. Ever try and merge to XML hierarchies together? There is no standard way to do that. You can physically merge two hierarchies of things, but someone has to write code to make that happen on a case-by-case basis. Same deal with combining two relational database tables. You can do it, but there is no global standard way to do it and you have to again combined things on a case-by-case basis. XBRL (via XLink) and RDF both allow for this type of flexibility.
But wait, there is even more! XBRL has two additional useful features. I don't think that RDF has either of these, but I need to check some more to be sure. The first is the ability to partition graphs into different networks. What this allows is different sets of things which can never collide. Networks basically keep sets distinct. I think you can achieve this using RDF by physically separating information into different files.
The other feature is prohibition. Say you don't like a relation which has been expressed. Well, XBRL allows you to turn the relationship off by prohibiting the relation. XBRL basically provides and "audit trail" so to speak so you can track the expression of the relation, if someone turned the relation of, and then even if someone recreated the relation. Of course, the system making use of XBRL can allow or disallow prohibition. (Here is a prohibition example I created.)
The bottom line here is that graphs offer flexibility and XBRL can articulate graphs of information. The way most others use XML, they cannot do this and there is certainly not a global standard way to do this, each case is therefore a point solution which requires someone writing code. Same for relational database tables, particularly across systems.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

