BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from May 5, 2019 - May 11, 2019
AI is Taxonomies and Ontologies Coming to Life
PWC makes the following statement in this article: "artificial intelligence (AI) has the power to change almost everything about the way they do business". You might ask, "How?"
In her presentation, AI and Machine Learning Demystified, Carol Smith makes the following statement on slide 12:
"AI is taxonomies and ontologies coming to life."
I could not agree with her more. But I would say this a bit more precisely. It is not that just any old thing called a "taxonomy" or "ontology" is what you need. You want formal, machine-readable, highly expressive taxonomies and ontologies. Artificial intelligence (AI) works by providing context that the AI can make use of. Taxonomies and ontologies are about classification. Classification turns unusable "dark data" into knowledge and understanding. While sometimes it is possible to let machines create classifications using clustering techniques of machine learning; for complex knowledge domains, like financial reporting, humans need to create the classifications. Once you get a solid foundation, then the machine learning processes can leverage the human created information and you get a hybrid approach to expanding taxonomies and ontologies. Basically, it is taxonomies and ontologies that enable the creation of machine-readable knowledge. For example:
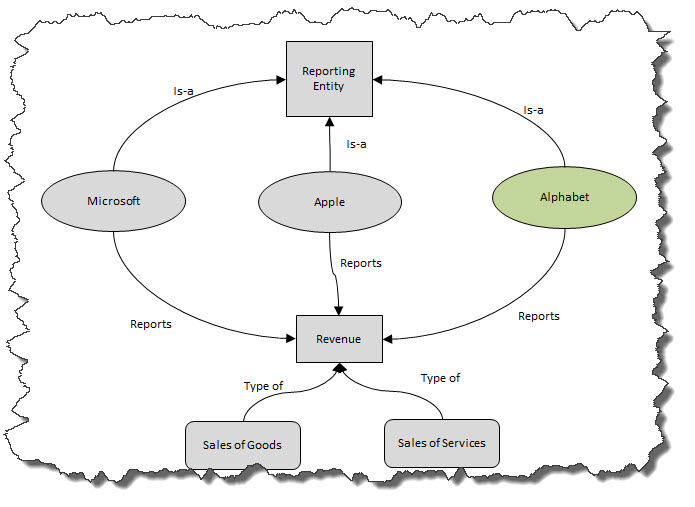
(Click image for larger view)
And so that is exactly why I created the framework that I did. It is that knowledge that enables Pesseract to do what it does. This is what is meant by the statement "stronger expressiveness and therefore reasoning capabilities" per the ontology spectrum.
Using the thick metadata layer provided by the framework, a business rules processing engine, and mechanisms to present information in human readable form things like this and this and this can be created. Essentially what you can get is similar to the logic and rules-based approach of imlementing artificial intelligence that is similar to the functionality of TurboTax. (Does not work exactly the same, TurboTax is a form; but a financial report is not a form.)
Over the coming years as people see more and more software effectively automating tasks they will come to learn that AI will have a significant impact. PWC points out that most business leaders have no clue how to implement AI within their organizations. This ignorance on the part of business leaders will lead to wasted money when the snake oil salesmen come around and try and sell you "AI". It will also result in many business leaders acting either too soon, too late, or going the wrong direction when trying to adapt to this inevitable, and immanent, new paradigm.
"Know how" is a type of knowledge. PWC offers some excellent advice that will help you and your organization maximize their ROI or AI. Where do you start to turn ignorance into know how? Computer Empathy is the summary that I created from my lab notes.
If you are still having a hard time getting your head around all this, check out this video about how self driving cars work. Or this video.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Understanding Answer Set Programming
So you have a thick metadata layer that describes reports, you have highly-expressive ontologies that describe reported information, and you have all the reported facts themselves that are provided in the report. But you are still missing two things from your knowledge based system.
- You need software to process all that information (i.e. rules engine).
- You need a mechanism to help the user of the software understand the results of the processing (i.e. justification mechanism).
As I pointed out before, XBRL Formula processors have specific defeciencies in their capabilities so they alone will not do.
So what do you do?
Well, you could build your own rules engine to process everything. After all, everything distills down to logic gates that are used for processing. What it is possible to build your own rules engine, creating a rules engine is not a trivial task.
What about using existing processing tools? That can work. You could convert everything to the semantic web stack of technologies and use existing semantic reasoners. That could work.
I thought that PROLOG or DATALOG could work. Those could work, but as I understand it PROLOG uses backward chaining and you will need forward chaining for many of the types of problems you need to solve.
Another approach that I have heard of is answer set programming. The best description of answer set programming that I have run across is this: (from Answer Set Programming: A Primerby Thomas Eiter, Giovambattista Ianni, and Thomas Krennwallner)
Answer Set Programming (ASP) is a declarative problem solving paradigm, rooted in Logic Programming and Nonmonotonic Reasoning, which has been gaining increasing attention during the last years.
The article Answer Set Programming at a Glance by GERHARD BREWKA, THOMAS EITER, AND MIROSLAW TRUSZCZYNSKI explains the motivation benind and key concepts of answer set programming which is a promising approach to declarative problem solving.
Answer set programming seems to be related to PROLOG.
There are free answer set programming processors such as Potassco. (you can download Potassco here) DLVHEX is another. Here is a comparison of implementations.
You can do an online demo here.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Achieving High Expressiveness on the Ontology Spectrum with XBRL
I have mentioned the ontology spectrum. I have mentioned that "AI is taxonomies and ontologies coming to life", meaning that artificial intelligence will only work to the extent that you have high-quality and extensive set of metadata. For example, this framework.
But, can you provide this high-quality and extensive set of metadata using XBRL? If so, how the heck do you do that? Well, here is the answer to this question: Yes you can and here is how you do it.
First, have a look a this graphic. In particular, look at the gray boxes at the bottom. I will show you how to achieve each of those items on the ontology spectrum using XBRL by providing an existing example that works. (I am going to take as many examples as possible from my IPSAS prototype.)
- Define terms: Terms are defined in XBRL using XML Schema. This is refered to as an XBRL taxonomy schema. Here is an example XBRL taxonomy schema. In addition to defining terms you can supplement the definitions with an XLink linkbase:
- Labels (any number of labels, identifiable with specific roles, in any language)
- Documentation (this is just a label linkbase with the label having a specific role, http://www.xbrl.org/2003/role/documentation)
- Commentary (again, a label linkbase with the role http://www.xbrl.org/2003/role/commentary)
- References to authitative and other literature
- Define narrower/broader term relations: These relations are defined using XBRL definition relations using the "general-special" arcrole. Or, you can use the "wider-narrower" arcrole defined by the XBRL International Link Role Registry. You can also define two terms as being equivalent using "essence-alias". But generally I avoid these, see "Defining formal relations".
- Define informal relations: One type of informal relations is XBRL presentation relations. They are informal in that they use exclusively the "parent-child" arcrole to define relations. Here is an example. The intent of the XBRL presentation relations is to define the structural relations that are used to generate renderings of information. Because many business professionals tend to be overly presentation focused, they tend to imply informal information to the XBRL presentation relations. This approach should be avoided in favor of "Define formal relations".
- Define formal relations: Formal relations are defined using the XBRL definition linkbase using specificly defined arcroles, preferably from the XBRL International Link Role Registry. Alternatively, you can define your own arcroles, here is an example of some arcroles I created. An excellent example of using formally defined relations are XBRL Dimensions relations. Here is an example. Another example of formal relations are my disclosure mechanics rules. This includes class-subclass (a.k.a. is-a). Here is an example of class relations.
- Define formal instance: Formal instances are defined by XBRL. Here is an example. Alternatively, an instance can be formally defined essentially within an XHTML document using Inline XBRL. Here is an Inline XBRL example of a formal instance (best viewed using Google Chrome).
- Define properties and dimensions: XBRL defines core properties by extending XML Schema. Dimensions are defined using XBRL Dimensions. Additional properties can be defined using an XML Schema. Here is an example of defining properties. Here is how you express that a concept has a property. Note that you can add labels, documentation, comentary, and references to properties that are defined to further explain the properties.
- Define value restrictions: Value restrictions are defined using XML Schema Part 2: Data Types. Data Types are assigned to concepts within an XBRL Taxonomy Schema. See the type attribute in this example. Cardinality can be defined in XBRL using tuples. Tuples are generally not used for financial reporting. Another approach to defining cardinality is using XBRL Dimensions. (I may not be understanding cardinality 100% here.) Note that units can be defined and used from the XBRL International Units Registry or you can define your own units as necessary.
- Define disjointedness, transitive and other relations: Disjointedness, transitive, has-a, part-of (meronymy) (a.k.a mereology) and other relations can be defined using arcroles. Here is an example of defining a disjointed relation. Here are reporting checklist rules which use these ideas. Disclosure mechanics rules also use these ideas and provide an example. Also note that the notions of "disjointedness" and "transitive" and "inverse" can be imbedded in the defintion of specific arcroles so that basically the defnitions are composite rather than using each notion separately.
- Define mathematical and logical rules: Simple mathematical roll up relations can be defined using XBRL Calculation relations. Here is an example. More complex mathematical and other logical relations can be defined using XBRL Formula or XBRL definition relations. Here is an example of XBRL Formula mathematical relations. Here are additional logical rules. The structural relations defined by XBRL Dimensions also seem to be logical rules.
If you cannot express what you need to express using the basic parts of XBRL 2.1, XBRL Dimensions, and XBRL Formula; there is one additional option. That option is XBRL Generic Links. With XBRL Generic Links you can define pretty much anything you want. Generic Links, like XBRL itself, uses XLink to define functionality.
Also, I would point out that XBRL complies with ISO Standards since XBRL is based on the W3C XML 1.0 technical syntax and XML is SGML: (ISO 8879:1986 Information processing -- Text and office systems -- Standard Generalized Markup Language (SGML)
Further, XBRL is complies with W3C standards because XBRL uses the W3C standards: XML, XML Schema, XLink, XPath, XPointer, XML Base, and XML Names.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Digital Maturity
In their book The Technology Fallacy, authors Gerald C. Kane, Anh Nguyen Phillips, Jonathan R. Copulsky, and Garth R. Andrus dispel the myth that technology is behind digital transformation and shows how people are the real key. The authors define digital maturity:
Digital maturity is primarily about people and the realization that effective digital transformation involves changes to organizational dynamics and how work gets done.
Everyone is creating their buzz words so you know things are starting to get serious. PWC packages these changes as 4IR (i.e. the fourth industrial revolution). KPMG calls it Industry 4.0. EY is onboard with the Fourth Industrial Revolution. Deloitte calls it Industry 4.0 also. EY points out four things you need to know about the fourth industrial revolution.
As I have pointed out in the past, XBRL has a role in the fourth industrial revolution. That role is getting clearer and clearer. On slide 12 of this presentation, Carol Smith points out that "AI is taxonomies and ontologies coming to life (NOT like humans learn)". The ontology spectrum explains what is necessary to create expressive taxonomies/ontologies.
If you still don't understand this stuff, if you want to increase your digital maturity; consider reading the information I have collected over the past 10 years and summarized in the document Computer Empathy.
Here is my ontology. A financial report is not one big thing, it is made up of many pieces that are individually identifiable. Many pieces, highly expressive ontology, software that understands the pieces and the ontology, Lean Six Sigma process measurement and control philosophies and techiques. Think about that.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print

