BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from July 7, 2019 - July 13, 2019
Ontology-like Things for Industry
Michael Uschold, Senior Ontology Consultant with Semantic Arts, provides this presentation Ontologies and Semantics for Industry where he explains the benefits of ontologies and ontology-like things to industry.
Ushold points out that there is a plethora of 'ontology-like things'. I like the term "ontology-like things". That is what the ontology spectrum tries to point out. Essentially, there are many different ways to express meaning, an ontology is just one of those ways.
The presentation is organized to answer three questions:
- What is the difference between an Ontology and a:
- When people say things like "Ontologies have unambiguous semantics", what do you think they mean; do you believe them; and why or why not.
- How are ontologies and semantics relevant to industry today?
Ontology is defined in the textbook Ontology Engineering by Elisa Kendall and Deborah McGuinness as follows:
Ontology - a model that specifies a rich description of the
- terminology, concepts, nomenclature;
- relationships among and between concepts and individuals; and
- sentences distinguishing concepts, refining definitions and relationships (constraints, restrictions, regular expressions)
relevant to a particular domain or area of interest.
I reconcile that definition above to the common components of an ontology that I summarize in the document demystifying ontologies as follows:
- Terms
- Simple terms (primitive, atomic)
- Functional component terms (complex functional terms)
- Properties (qualities, traits)
- Relations
- Type relations (class/type relations, "type-of" or "is-a" or "class-subclass" or "general-special")
- Functional relations (structural relations, "has-a" or "part-of" or "has-part" or "whole-part")
- Property attribution (has property)
- Assertions
- Restrictions (constraints, limitations)
- Axioms
- Rules (theorems)
- Individuals
- Instance (facts)
This forms a formal, logical system that is:
- Consistent (no theorems of the system contridict one another)
- Valid (no false inference from a true premise is possible)
- Complete (if an assertion is true, then it can be proven; i.e. all theorem exists in the system)
- Sound (if any assertion is a theorem of the system; then the theorem is true)
- Fully expressed (if an important term exists in the real world; then the term can be represented within the system)
Fundamentally, Uschold points out, an ontology is "A way for a community to agree on common terms for capturing meaning or representing knowledge in some domain." The ontology spectrum helps you understand to what extent you are actually agreeing. (Logic; Formal System)
And so, the reason for creating an "ontology-like thing" is to make the meaning of a set of terms, relations, and assertions explicit, so that both humans and machines can have a common understanding of what those terms, relations, and assertions mean. "Instances" or "sets of facts" (a.k.a. individuals) can be evaluated as being consistent with or inconsistent with some defined ontology-like thing created by some community. The level of accuracy, precision, fidelity, and resolution expressively encoded within some ontology-like thing depends on the application or applications being created that leverage that ontology-like thing.
An ontological commitment is an agreement by a community to use some ontology-like thing in a manner that is consistent with the theory of how some domain operates, represented by the ontology-like thing. The commitment is made in order to achieve some goal established by the community sharing the ontology-like thing.
Ontology-like things for accounting, reporting, auditing, and analysis require high-quality and therefore they require highly expressive ontology-like things.
As Kendall and McGuinness point out, "The foundation for the machine-interpretable aspects of knowledge representation lies in a combination of set theory and formal logic."
Put these pieces together correctly and you can get software applications to perform magic! That is what curated metadata is all about. You need to use the right tool for the job. Financial reports will lead the way.
Might be time to increase your digital maturity.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Most Powerful Women in Accounting
CPA Practice Advisor published the 2019 list of the most powerful women in accounting.

Nice work ladies!
Use the Right Artificial Intelligence Approach for the Job
It is a dangerous time for CPAs right now. The term "AI" is now a buzz word. Everyone and their brother is now trying to sell you AI. Don't be duped by the snake oil salesmen. Get educated.
As I explain in the document Computer Empathy (which would be a really good thing for CPAs to read); there are two major techniques for implementing artificial intelligence:
- Logic and rules-based approach (expert systems): Representing processes or systems using logical rules. Uses deductive reasoning.
- Machine learning (pattern-based approach): Algorithms find patterns in data and infer rules on their own. Uses inductive reasoning; probability.
You can combined both approaches and create a third approach which is a hybrid of both approaches: (larger image)
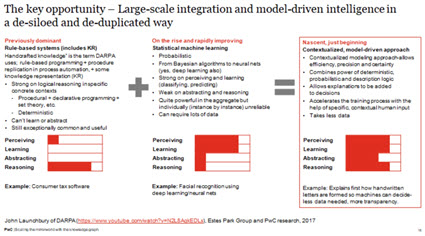
Implementing a "good old fashion expert system" is a lot of work. A logic and rules-based approach is based on what amounts to an ontology which can be hard to get right but once you have this high-quality curated information; it can literally supercharge AI and make it do wonderful and useful things. This is proven technology, it works, but it is expensive and time consuming to get right.
Many computer scientists would have you believe that machine learning or "deep learning" (they are the same thing) will help you get around all the hard work and expense of a logic and rules-based approach to implementing AI. But current machine learning type systems are being characterize as doing basically "cheap parlor tricks" and they are a fragile house of cards rather than a solid foundation.
Machine learning or deep learning systems work best if the system you are using them to model has a high tolerance to error. These types of systems work best for:
- capturing associations or discovering regularities within a set of patterns;
- where the volume, number of variables or diversity of the data is very great;
- relationships between variables are vaguely understood; or,
- relationships are difficult to describe adequately with conventional approaches.
Machine learning basically uses probability and statistics, correlations. This is not to say that machine learning is a bad thing. It is not, it is a tool. Any craftsman knows that you need to use the right tool for the job. Using the wrong tool will leave you unsatisfied.
There are no short cuts. No one disputes the need for a "thick layer of metadata" to get a computer to perform work. What is disputed is the best way to get that thick layer of metadata. Machine learning works best if you already have a thick layer of metadata, that is the training data that machine learning needs to work.
What is needed first is a theory and framework. You use that theory and framework to build a machine readable ontology. Here are my theories for financial reports and business reports. And here is my ontology prototype for US GAAP. Folks, this is hard work.
Are you aware of the AICPA's Dynamic Audit Solution Initiative? Is that initiative going down the right path? How do you know? Can those creating this new approach to auditing prove that it will work? Can they provide you with testing results that help you understand and evaluate if it will work? What are the requiements of this new approach? Do CPAs even have enough background understanding of artificial intelligence to ask good questions?
Again, there are no short cuts.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Prototype
This is information for a prototype:
- Documentation
- XBRL Cloud Evidence Package
- XBRL instance
- Taxonomy
- Business Rules
- Fundamental Accounting Concept Relations Cross Checks
- ZIP file with all XBRL files
More to come...
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Dynamic Audit Solution Initiative
The AICPA and others are working on what they call a dynamic audit solution. For more information see here. I will find out more. Here is more information:

