Insuring your SEC XBRL Financial Filing is Correct Effectiently and Effectively
Many accountants and auditors find the process of verifying that SEC XBRL financial filings are correct rather challenging. I certainly understand this being a CPA and ex-auditor and having struggled for years trying to make sure the XBRL I was creating was correct with either no software or early XBRL software tools which were quite technical in nature and rather hard to use.
While software applications for enabling such verification of SEC XBRL financial filings is still rather immature, the software is in fact maturing and verification processes and techniques used in the past are less appropriate today.
A big part of the challenge of making sure your SEC XBRL financial filings is correct is your fundamental philosophy. First off, what exactly does "correct" mean? I define correct as:
- HTML and XBRL convey the same message
- Integrity: each piece is correct and all the pieces fit together
- Clear and appropriate business meaning/semantics
- Consistency with peers
- Consistency between current and prior periods
- Justifiable extension concepts
- Appropriate rendering
- Usable by analysts
The second challenge is to understand how do you know that everything is correct? Everything which should be there is there, nothing which should not be there is included, and everything which is stated is accurate?
The first tip, forget about the XBRL technical syntax.
Forget about XBRL Technical Syntax
Should the XBRL technical syntax of your filing be correct? Absolutely. If your software application cannot do this for you so you don't have to worry about it then you likely need better software.
Should your ampersands within an XBRL footnote be double escaped? Of course you ask, "What is this guy talking about?" That is precisely my point. The Edgar Filing Manual (EFM) says that you need to double escape your ampersands. Are you going to check for that? Of course not. Software should not let you NOT comply with that rule. Verifying these sorts of things can be 100% automated within software, business users need not deal with this. Besides, the SEC will not accept incorrect XBRL technical syntax, their submission validation process makes sure this is the case.
Another reason you should forget about XBRL technical syntax is this: Can you actually read XBRL technical syntax? Should you be able to? Some people can. More people think they can but really cannot. Here you go, give it a try:
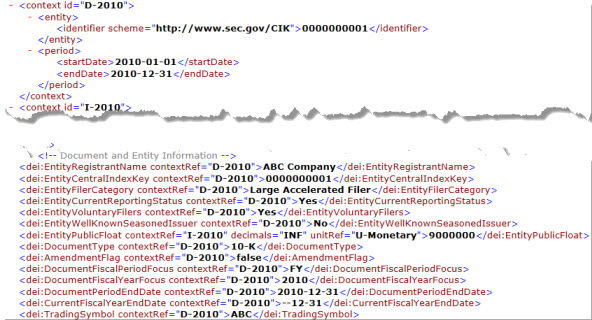
Here is exactly the same information rendered as an Excel spreadsheet, I call this a fact table:
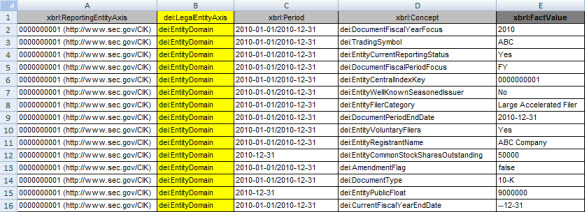
A fact table shows all the facts and all the characteristics of each reported fact. Did I change the meaning of the information by moving it from the XBRL syntax to the Excel syntax? Certainly not. Which is easier to read, the XBRL or the Excel? Notice that there is no syntax information at all in the Excel such as the context ID. Clearly you need additional information such as the units and decimal information for numeric values, but the point here is that it is the semantics which are important, not the syntax.
Taking this one step further, here is exactly the same information which was shown in the Excel fact table shown again, this time rendered within an XBRL viewer (in this case XBRL Cloud's XBRL viewer application):
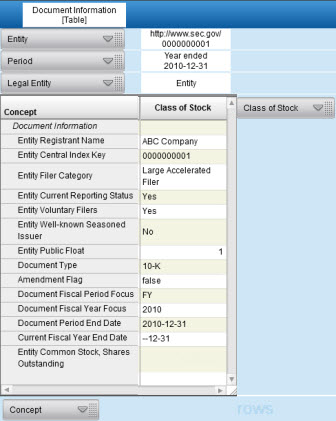
"What do you mean, same information?", you ask. Yes, it is the same information. The information from the Excel table, the fact table, contains the business semantics, the characteristics of the facts being communicated by the SEC XBRl financial filing. All the rendering application does is the same thing that an Excel pivot table does, it renderings the information into a form which is consumable by business users.
If you look at the business meaning of information contained in an XBRL instance, it might look like the Excel fact table shown above or it might look like the more human friendly rendering. In fact you could and should have both views. Both the fact table and the rendering communicate the same information, but the different forms help you achieve different things. Does how the information is rendered change the business meaning of the information? Certainly not.
I think that while you would probably acknowledge that some software applications are better than others at helping the user to see the business meaning, it is not the case that whether information is rendered in the form of a fact table or in a more human readable form; rendering the information does not change the business meaning.
Reasons Why Syntax Doesn't Matter
I think it would be easy to agree that taking information which is in the XBRL format and putting that information into some other syntax such as Excel spreadsheet, a database, some other form of XML does NOT change the meaning of the information. In fact, it certainly should not because that is a fundamental characteristic of XBRL; the ability to exchange the information between different business systems.
So while the syntax changes when the information contained in an XBRL instance and taxonomy moves from the form of an XBRL instance, into Excel and/or into the form of a database application or some other format; the meaning of the information (the semantics of the information) does not change.
Further, there are different ways to express exactly the same business meaning using the XBRL syntax.
Consider, for example, that the SEC has rules relating to expressing, which reported information relates to the legal entity "consolidated entity". In essence, the EFM states that unless you state otherwise, the legal entity is assumed to be the "consolidated entity". The EFM states something to the affect that by creating an [Axis] and a [Member] for that [Axis], the information expressed in an XBRL instance and its XBRL taxonomy relates to the "consolidated entity". You use the [Axis] "dei:LegalEntityAxis" and the [Member] "dei:EntityDomain". Or, you could also NOT physically provide any legal entity [Axis] nor the [Member] (i.e. you do not create a [Table]). Therefore, no legal entity [Axis] is provided and therefore the legal entity is assumed to be or implied to be the consolidated entity.
In essence, you can either explicitly state the legal entity or you can imply the legal entity per the SEC EFM rules.
Does your choice of which approach you use, using or not using the XBRL syntax of a [Table], impact the meaning of the information? I think that you would agree that it clearly does NOT impact the meaning of your information. Here is an example of what I am talking about, Dow Chemical Company does NOT use a [Table] and Apple DOES use a [Table] to express exactly the same information:
- Dow Chemical Company: SEC Viewer | Taxonomy
- Apple: SEC Viewer | Taxonomy
But wait, there is more! You can take the explicit versus implicit representation of the legal entity one step further.
In the XBRL syntax, or more accurately the XBRL Dimensions syntax, there is the notion of a "dimension default". If the dimension default is indicated in an XBRL taxonomy; that dimension would physically not exist within the context for that fact within an XBRL instance. So, does the business semantics of the information change between the options you choose to use the "dimension default" or not use the "dimension default"? Clearly not.
Now, under SEC reporting rules, you are always required to use a dimension default. However, if you do use the dimension default that dimension and the default value of that dimension (a [Domain] or a [Member]) do not physically exist within the context of the XBRL instance. Does the fact that the syntax rules of XBRL which states that the [Axis] and [Member] in our case the legal entity axis and the value "consolidated entity" expressed using "dei:LegalEntityAxis" and "dei:EntityDomain", but in this case not physically there because of the technical rules of the XBRL syntax; does this change the business meaning of the information? Clearly not.
Focus on Business Semantics
When you review an SEC XBRL financial filing, do you care that any of the following core financial semantics (meaning) is appropriately articulated:
- Balance sheet reports assets
- Balance sheet reports liabilities and equity
- Balance sheet reports equity
- Balance sheet balances
- Balance sheet foots
- Cash flow statement reports net cash flow
- Net cash flow foots
- Income statement reports net income (loss)
- Income statement foots
- If a classified balance sheet is presented, the balance sheet reports current assets and current liabilities
Now we are talking! This is both understandable to an accountant and/or auditor who is checking to be sure the information is properly articulated and it is also part of the characteristics of a quality SEC XBRL financial filing. And this is just the tip of the iceberg. Every aspect of an SEC XBRL financial filing can be evaluated in the same way: does it exist, does it foot, does it cross cast, is it the correct concept, are all the pieces correct, do the pieces tie together properly, etc.
Bottom Line
Clearly it is important for the XBRL technical syntax to be correct. Software applications can automatically check to be sure that your escaped XHTML has property double escaped those ampersands. And your software should not bother you with these details, of which there are thousands and thousands.
Accountants and auditors need not consider the XBRL technical syntax when trying to determine if an SEC XBRL financial filing is correct for two primary reasons:
- You don't understand the XBRL technical syntax, you likely never will understand the XBRL technical syntax, and you never really needed to understand the XBRL technical syntax in the first place. You will likely always be using the information contained within an XBRL instance and XBRL taxonomy from within some software application built for business users. The software will put the information into a form which allows you to be sure the information is articulated correctly.
- It is far more effective and efficient to review information in a form which is easy for you to use and understand. It is the business semantics which you care about, not the XBRL technical syntax. Focusing on the XBRL technical syntax is a waste of time and money.
If your software does not both properly hide the unimportant XBRL technical syntax from you and expose the imporant business meaning of information to you in a form what is useful to you, then start looking for better software.
 Charlie
in Creating SEC XBRL Financial Filings
|
Charlie
in Creating SEC XBRL Financial Filings
|
 Post a Comment
|
Post a Comment
|
 1 Reference
1 Reference
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to FriendReferences (1)
-
 Response: chemical company in india
Response: chemical company in india

Reader Comments