Dow Jones Industrial Average: Prototype Information Extraction
In order to test the extraction of information from SEC XBRL financial filings and to provide an example of such extraction I created this prototype. The code used to achieve this aggregation of the Dow Jones Industrials 30 stocks is provided, not as an example of good code, but rather as example of how to extract information directly from an XBRL instance.
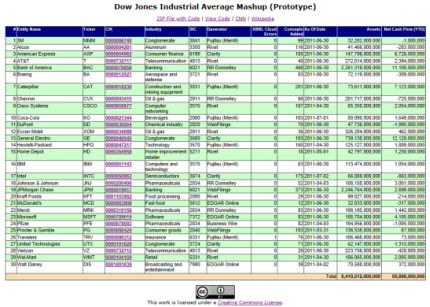 Dow Jones Industrial Average Mashup (Prototype)
Dow Jones Industrial Average Mashup (Prototype)
No XBRL processor is used to grab information from the 30 SEC XBRL financial filings. I am not promoting this technique, I just want to provide a broadly usable example. While as you can see data can be grabbed using this approach (i.e. this works), building a robust, scalable, reliable, repeatable, and accurate system will definitely take more that what I have shown.
I checked each of the assets and net cash flows numbers against the actual filings to be sure that I got this correct. As far as I can see, the information is accurate.
Think about what this means. How long would it take you to get just these two pieces of information manually? It takes the prototype application about 5 minutes or so. The biggest constraint is the file download time. Imagine running this routine (or a more reliable one) against every SEC XBRL finacial filing and be able to get the total assets and net cash flows of all public companies. That is actually my next step in testing this code.
Don't have time at the moment, but in another post I will describe issues involved with grabbing these two data points and how to overcome them. For example, getting a list of the files containing the information, having to go file to file rather than getting the information from a database, different period end dates and fiscal periods, and other such idiosyncrasiesof the information. Because of the nature of the information, the SEC XBRL financial filings is a tough dataset to use. The modeling of filings is a separate issue, that can be easily adjusted. Adjusting financial filing rules is a totally different matter all together.
 Charlie
in Demonstrations of Using XBRL
|
Charlie
in Demonstrations of Using XBRL
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments