Understanding Syntax
Syntax, or technical syntax, is the physical format of the information. There are presentation formats and there are representation formats. These are some of the more common file formats (which are technical syntaxes):
- CSV (Comma Separated Values): Example
- Fixed Width: Example
- DIF (Data Interchange Format): Example
- PRN (Printer Information): Example
- ASCII Text: Example
- Plain Text: Example
- Excel (Binary): Example
- Excel XML: Example
- Word (Binary): Example
- PDF: Example
- RTF (Rich Text Format): Example
- HTML: Example
- HTML (view text): Example
- XML (Traditional): Example
- XBRL: Example
- RDF/OWL (Draft, needs work): Example
- JSON: Example
Each of those examples expresses the same information in a different way, using a different file format or technical syntax. Another way of saying this is that each file format has a different syntax but the information expressed is identical. There are lots of other file formats (see http://www.fileinfo.com/filetypes/data). Imagine having to write software to parse and use these different data formats. That is why global standard file formats are popular.
Looking at CSV you can learn some things about syntax. CSV (comma-separated values) is a simple ASCII file format that is widely used by business and scientific applications to exchange tabular data.
First, CSV is not a formal global standard format. CSV can be called a best practice or an ad hoc or informal standard. However, CSV is widely used, widely supported, and there are even a number of informal specifications. Excel supports CSV import and export; that is a specification in that if it works, it is right and if it does not it is wrong. IETF (Internet Engineering Task Force) created a specification, RFC-4180. CSV-1203 is another. Super CSV is another. Some guy in New Jersey created another.
The CSV-1203 best practice standard describes the problem they are trying to solve as follows: (emphasis is mine)
By adopting this standard, you place a prudent limit on the otherwise countless variations that could be implemented by systems developers. Its benefits are clearest when a CSV file forms an information bridge between two companies. Typically you should expect this standard to help reduce the time it takes to establish a data processing connection between your company and your clients or your service providers.
Business people tend to be very practical. Easier is better than harder. But for something to be useful to business people it has to work reliably, predictably, repeatedly.
But CSV "has problems" or limitations. It is more like trying to put a square peg into a round hole.
First off, there are three primary types (schemes/models/representations) for formatting and processing structured information (semi-structured, highly-structured):
- Table-type (homogeneous, tabular, consistent): relational databases, CSV, spreadsheets, or tabular-type representations which allow only one level of hierarchy within each table; but hierarchies can be constructed by relating tables
- Tree-type(heterogeneous, arborescent): XML, some XBRL application profiles, JSON and other tree-hierarchy-type information which allow for the expression of one hierarchy
- Graph-type or Open-type (heterogeneous, arborescent): RDF, EAV , some XBRL application profiles, and other open schema-type or graph-type representations which are more graph-oriented and allow for dynamically creating virtually any number of hierarchies; very flexible
Basically, CSV was not designed to represent tree-type information, it was designed to represent table-type or tabular information. I am not going to go into explaining the differences between table, tree, and graph type data here, perhaps in another blog post.
Another limitation of the CSV syntax is that CSV does not define data types. By contrast, XML Schema defines data types (check out section 3 Built-in Data types) that can be used within some XML file. XML Schema data types are fast becoming the global standard data types, it seems.
Another limitation of the CSV syntax is that CSV does not really have much of a schema. Again, a relational database provides the ability to define a schema or the structure of and relations between tables in that relational database. XML Schema lets you define the structure that is allowed within an XML file.
Another limitation of the CSV syntax is that CSV was designed to transfer data. There is a difference between data, information, knowledge, and wisdom. This is one explanation of the difference:
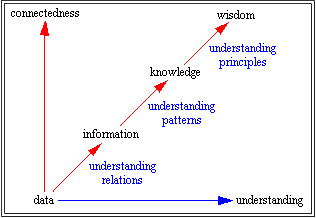 by Gene Bellinger, Durval Castro, Anthony Mills
by Gene Bellinger, Durval Castro, Anthony Mills
There is a subtle, but very significant, difference here. CSV stated that the objective is exchanging data between business and scientific applications. But the real goal is not the exchange of the data, but making use of the data: the real goal is business system interoperability.
So another way to cast this is that different technical syntaxes have differing powers of expressing semantics, or meaning, of the relations, patterns, and principles which are contained in the information. There are two reasons why you want to express this type of information: (1) verifying/validating that the information is expressed correctly, these are called business rules and (2) communicating to others as to the important relations, patterns, and principles represented within the information. The more business rules you have, the stronger the semantics. The stronger the semantics, the more you can do with the information.
Another point which can be made using CSV is the difference between a "presentation format" and a "representation format". CSV actually performs both presentation and representation functions well. It is easy for humans to read because it is tabular, but it is also easy for machines to consume because it is tabular. This is a good explanation of the difference between representation and presentation:
Presentation is just showing. Representation is showing with another meaning behind it. Representation is indicating something below the surface of what you’re presenting.
That is not the greatest explanation of the difference between presentation and representation, it will act as a placeholder for now.
I don't have this exactly where I want this but I am going to call this good and tune it up later.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments