Understanding the Financial Report Disclosure Processor/Engine
In my view, this is an appropriate high-level architecture to build the underlying "engines" or "processors" which make digital business reporting and digital financial reporting work as business users need it to work:
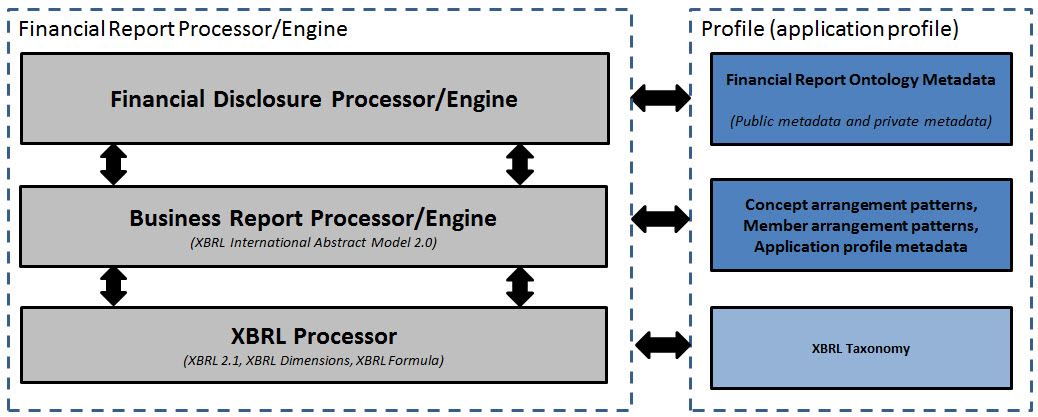 (Click image for larger view)
(Click image for larger view)
So let me explain why I think this and what the pieces are. First, if you follow Grady Booch's five common characteristics to all complex systems, you break the complex pieces into smaller less complex pieces. Second, you expose business users to things business users understand.
Working from bottom to top, this explains the pieces: (Note that you can load the code examples into Microsoft Visual Studio and then use the Object Browser to view the class model. Here is what you can see because I am documenting the code using XML comments.)
- XBRL Processor: Most software vendors who support XBRL understand what this is and are very comfortable with this level. This is the "techie level". You read the XBRL Technical Specification, you test against the XBRL Conformance Suite, and you are off to the races.
- Business Report Processor/Engine: The next level is a generalized version of a business report. This is defined by the XBRL Abstract Model 2.0. I would go one step further and define a more constrained application profile or even better a handful of application profiles. Here is one example general business reporting application profile which is based on the US GAAP Taxonomy Architecture. Basically, this profile does not allow tuples and the other stuff the US GAAP Taxonomy Architecture prohibits, but is more restrictive and safer to use because it forces better consistency. A proof by the Financial Report Semantics and Dynamics Theory shows that 99.9% of SEC XBRL financial filings follow these semantics and fit into this representation.
- Financial Report Disclosure Processor/Engine: Building on top of the business report processor is another processor which is unique to financial reporting. There may be a desire to split this out even further to US GAAP, IFRS, and maybe even SEC specific financial reporting. That is to be determined and the answer will unfold as the classes are built out.
There are WAY, WAY more pieces than what I am showing in the graphic above: import/export, rendering, validation, workflow management, content management, query. But I left those pieces out to better focus on the differentiation of these specific pieces.
Most software does not break these out correctly. That causes reduced software flexibility and harder to use software. It also causes error prone SEC XBRL financial filings. What if software did not allow you to create mismatched Level 3 text blocks and Level 4 detailed disclosures such as the ones documented on this page? Or better yet, what if the financial report disclosure processor had an intimate understanding of these digital financial report principles so you could never make these sorts of mistakes? That is the entire point of having the disclosure processor/engine.
Can anyone point me to a better architecture that actually works correctly? I would recommend that you may want to go back to the blog post Data and Reality before you tell me that this cannot work.
Something else that provides clues as to what a financial report disclosue processor does is the metadata the processor leverages.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments