Business Professionals: What does "SEC XBRL Financial Filings Works" look like?
There is a very interesting convergence occurring. The moving pieces are the US GAAP XBRL Taxonomy, SEC XBRL financial filings, software tools available in the marketplace, and a growth in the amount of experience people have with SEC XBRL financial filings and XBRL in general.
What this means, I believe, is that business professionals are starting to have an increasing amount of visibility into what is going on with XBRL. The reason this is important is because it helps business professionals understand their options for making use of XBRL better.
So rather than having someone throw something at you and you then have to live with what they devised, business professionals can start communicating how they desire XBRL to serve them. Business professionals can determine for themselves which option they prefer.
Let me ask you this question to show you what I mean: What does "SEC XBRL financial filings works" look like? When can you call SEC XBRL financial filings a success? Here are the options or possibilities I can come up with:
- XBRL financial filings will never work: XBRL will NEVER work because XBRL CANNOT possibly work. This SEC XBRL experiment needs to be abandoned. (There are people who believe that is the only possibility.)
- Parsing of financial information is easier than it was in the past: SEC XBRL financial filings can be said to "work" when advantages are gained and the old process of trying to "parse" HTML filings is made easier by being able to read some significant amount of information from the filings, leveraging the structured nature of the information. Substantial human intervention is required to perform complex mappings, etc.
- Automated reuse of financial information: SEC XBRL financial filings can be said to work when financial information can be read from those financial filings using safe, reliable, predictable, repeatable processes and that information is fed to down-stream processes and effectively used without the need for human intervention to rekey information.
Which of those three definitions of "XBRL works" do you subscribe to? Are there other possible options or possibilities which can be used to define "success", some other point where victory can be declared?
So where are we today? Take a look at a process that I have been gradually perfecting. I tried to grab information about fundamental accounting concepts from 10-K filings submitted to the SEC using the XBRL format. I did that about a year ago. I wrote my own Excel application to grab the information.
Well, now there are a number of APIs (application programming interfaces) which provide that information:
- SECXBRL.info (Commercial product)
- XBRL Cloud (Commercial product)
- Prolifis SEC Viewer (Commercial product)
- XBRLAnalyst (Commercial product)
- My Excel application (noncommercial)
You would expect that if I were to query each of these software applications that each would return the same results and their results would match the results obtained by my application. Right? Seams reasonable.
Do they?
Well, yes...they actually do. See here:
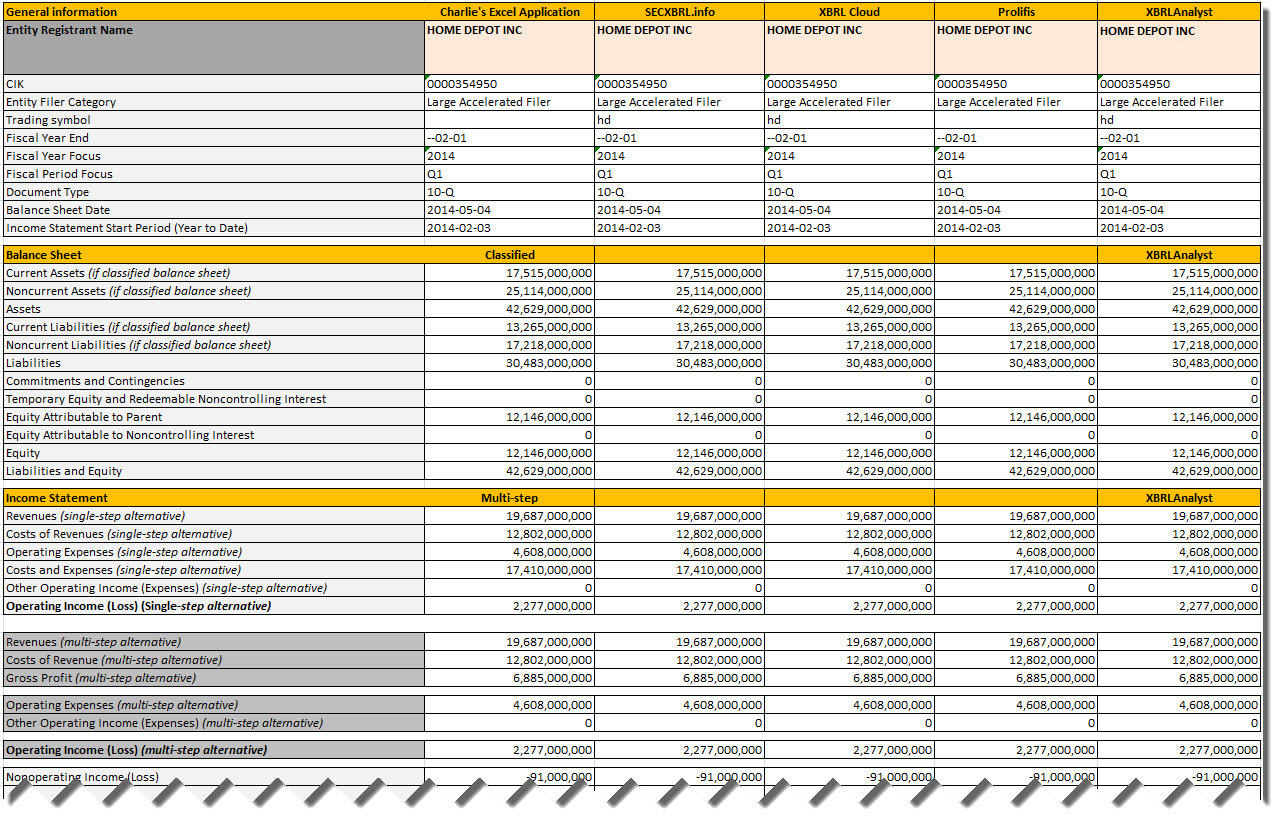 (Click image for larger view)
(Click image for larger view)
The fact is, each of the APIs returns the exact same results for each of the values for each of the fundamental accounting concepts for each of the DOW 30 companies. That is how far I have gotten thus far in my testing, but I suspect that the comparability will be very good for the Fortune 100, S&P 500, and for the remainder of the SEC XBRL financial filings (I exclude trusts and investment funds).
How do I know that? Well, because I am TRYING to achieve exactly that: comparability between all of these different APIs from different software vendors. I provided metadata to software vendors, the software vendors built software, I helped them debug and test their software.
This is the metadata that I provided, what you need to do to make use of the basic financial information contained in SEC XBRL financial filings:
- Standard list of concepts that I want to grab expressed in human readable form and in machine readable form (XBRL). This is necessary because of the two points below.
- Standard set of mappings between these concepts and the US GAAP XBRL Taxonomy concepts expressed in human readable form and in machine readable form (XBRL). This is necessary because there are many times different taxonomy elements used to express the same reported fact.
- Standard set of impute rules when you cannot find value in pretty readable human terms and machine readable form. This is necessary because reporting entities report facts inconsistently, for example not all filers report "Operating Income (Loss)" or a total for "Nonoperating Income (Expenses)".
That is all that it takes to extract information from SEC XBRL financial filings. Do you consider this hard? Easy? Can it be made easier? Is this what people intended?
Well, all this is not bad, but we are not meeting the success criteria which I subscribe to, #3 above: 100% automatable processing. Also, realize that while I am working with concepts from the primary financial statements, the process is exactly the same for many of the disclosures. That is a lot of work.
The information returned has quality issues so I cannot say I have achieved "success". Why is success not being achieved? There are specific reasons. Every time you cannot get a piece of information or the information is not correct, one of these specific reasons is the culprit. Here are the specific reasons:
- Extraction algorithm errors: The extraction algorithm I am using is too simplistic. Why? Well, because I am not a programmer. My algorithm is a prototype. While the fundamental accounting concepts seem pretty straight forward in most areas, the reality of SEC financial filings is that there is more variety than the fundamental accounting concepts allows for at this point. Balance sheet variability, statement of comprehensive income variability, cash flow statement variability is dealt with for the most part. But the income statement variability needs work. So, I figure there is not one set of fundamental accounting concept relations, the evidence I have seen suggests that there are somewhere between 15 and 20 permutations/combinations which need to be created.
- US GAAP XBRL Taxonomy inconsistencies, ambiguity, and errors: So actually, the taxonomy itself is very good in this regard. But, what is not so good is the communication as to how the US GAAP XBRL Taxonomy should be used. Case in point. Filers change the meaning of a concept by using the concept differently than how the US GAAP XBRL Taxonomy seems to say is should be used. The biggest problem is the part about "seems to say". Basically, the rules as to how the taxonomy should be used are poor in a few important areas. More on this in a moment.
- SEC XBRL financial filing errors due to lack of inbound SEC validation rules: There are obvious errors in SEC XBRL financial filings. These are easy to catch, clearly errors. Balance sheets balance (Assets = Liabilities and equity) is pretty straight forward. Other relations are straight forward. But there are situations which are not so clear. That means what the filer is reporting may, or may NOT, be errors. Remember the "seems to say" part mentioned above? That is part of the issue, who knows how things are supposed to work. Basically, if the SEC XBRL financial filings went through the same set of business rules, there would be both clarity as to HOW things are supposed to work and rigor and consistency in the quality of the filings. The best thing that we have today is what XBRL Cloud is doing with their Edgar Dashboard and the XBRL US Consistency Suite. However, filers are not REQUIRED to comply with those rules. Some take the time to fix their filings, some do not. So, SEC XBRL financial filings have errors.
- Impossible to use automated processes to figure out information within filings (i.e. human intervention is necessary): There are exactly three things which contribute to this situation in SEC XBRL financial filings today, (a) values which are not reported and they are NOT REQUIRED to be reported, (b) filers moving concepts from one category and using them as if they were something else, and (c) filers creating extension concepts and there are no machine readable processes to determine what category an extension concept fits into. Here are three specific examples
- Filer does not report "us-gaap:OperatingExpenses": If a filer does not report an important concept such as Operating Expenses, software still has to figure out the value of that important concept. Things like "Noncurrent assets" are very easy to impute because "Assets" is always reported, "Current assets" is always reported, and you know that "Noncurrent assets = Assets - Current assets". No problem. Figuring out the income statement line items is more complicated. Why not just explicitly report the concept? Well, it is not the law, filers don't have to. Can you ask them to? Sure. Using their filing would certainly be safer. Some will make the change and report Operating Expenses. But some will not. Get the SEC to make them? Could work, but that is a change in the law.
- Filer moves "us-gaap:InterestAndDebtExpense" to be part of "us-gaap:NonoperatingIncomeExpense": This is really problematic because when someone starts grabbing facts and using the facts without comparing them to other facts to be sure the relations make sense, bad information can result. This is actually rather easy to fix by just establishing a rule "don't change the meaning of a concept by using it in unintended ways." Now, if key concepts are required to be reported (bullet point above), this is actually less of a problem.
- Filer creates the extension concept "my:InterestExpense": If a filer created a concept and named it something which a human can totally figure out what it means, that does not mean that a machine such as a computer can understand that was meant by the concept. This is also easy to fix. All a filer needs to do is associate extension concepts with some other US GAAP XBRL Taxonomy concept. XBRL has a mechanism to do this, the XBRL Definition relations. Easy solution. But until this or something else is done, you would be able to reliably automated processes. Again, if you require key concepts to be reported, this problem is minimized.
Now, there are ways to overcome each of these issues. There are even ways to make the mappings and the impute rules for figuring out the fact values much, much easier. All you need to do is implement this process, you will see the areas where improvements can be made.
What is the bottom line here? Business professionals who employ XBRL to enable the automation of processes have choices. They can make the choices consciously or unconsciously. The way the US GAAP XBRL Taxonomy is constructed, the rules which are communicated or not communicated, the business rules which the SEC does or does not provide, and so forth all impact how the system works. Business professionals can start to question choices made to try and make things work better.
At this point it still takes some effort to understand, but understanding things only takes a little intellectual curriousity and a little of that effort. Tools are available to help business professionals understand. As tools mature, the ability to understand will improve even more.
So, what does "works" look like for you?
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments