Public Company Quality Improves Yet Again, Three Generators Reach 80%
The quality of public company XBRL-based digital financial reports increased yet again. This month 3 generators (software vendors, filing agents) reached the point where 80% or more of their filings where consistent with a set of fundamental accounting concept relations.
A few data points are worth pointing out. First, the sum of errors in all filings related to these fundamental accounting concept relations is about to drop below 3,000. Right now, the sum of all errors is 3,001. Contrast that to the 12,259 total inconsistencies for the 2013 10-Ks and and 4,463 total inconsistencies for the 2014 10-Ks.
Second, if you look at the graphic on the very bottom you can see that consistency with each test is now above 95% for every test except for one which is at 94.98%. Next month, every test will likely be above 95%.
Here is a comparison across time which shows total reports as the blue bar and total number of 100% consistent public company XBRL-based financial reports which is the red line:
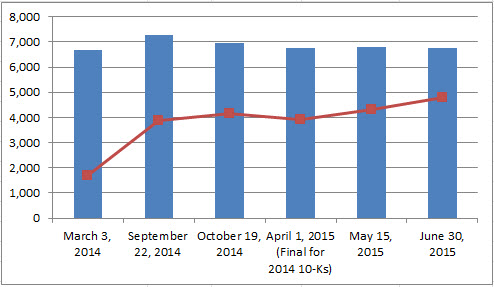 (Click image for larger view)
(Click image for larger view)
Here are the results summarized by generator:
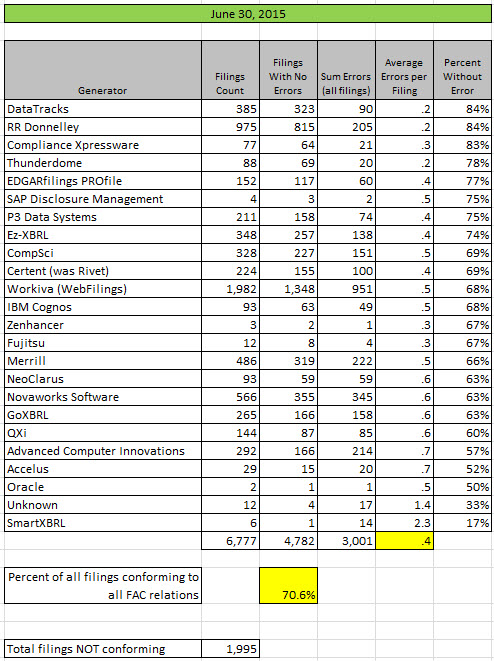 (Click image for larger view)
(Click image for larger view)
Here are the results summarized for the individual tests:
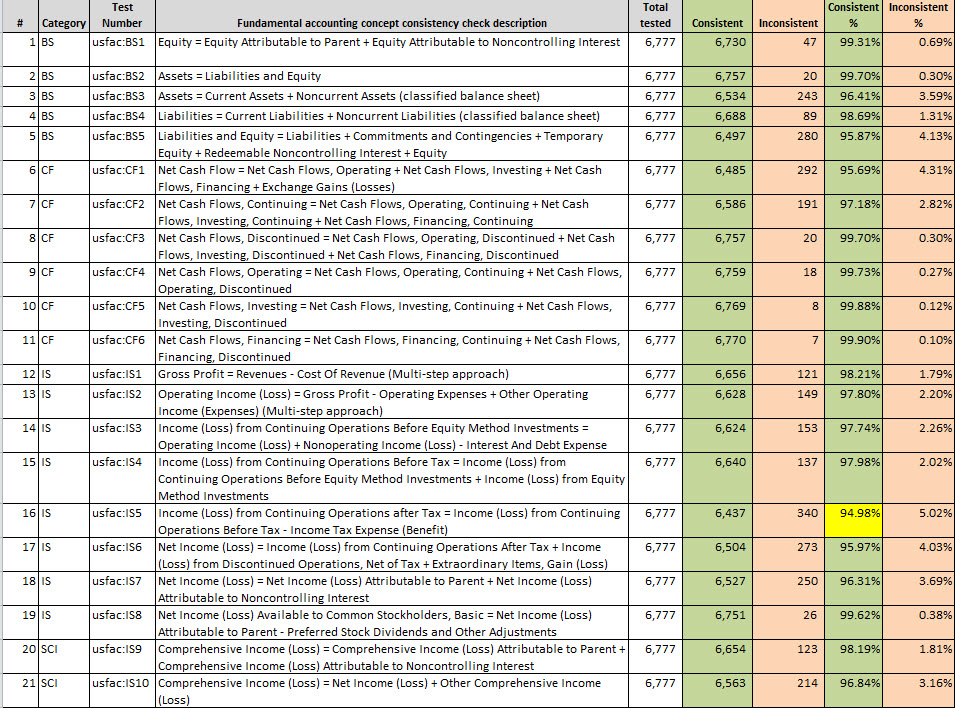 (Click image for larger view which includes test description)
(Click image for larger view which includes test description)
You can find the human-readable and machine-readable versions of of the consistency checks used to test these fundamental accounting concept relations here.
I am changing the way I evaluate consistency with these fundamental accounting concept relations tests slightly going forward. In the past, I have combined the consistency checks with the machine-readability checks. My rational is as follows. In the past I have had the mantra,
"Prudence dictates that using financial information from a digital financial report not be a guessing game."
There are two parts related to achieving machine-readability of the financial information reported by public companies. The first is the consistency of the fundamental accounting concept relations which are expected. The second is providing adequate information for a machine to be able to decipher the information.
The first, consistency with expected relations, is a US GAAP accounting issue. Basically, using the wrong concepts or mathematical errors are accounting consistency issues.
The second, the ability of a machine to be able to correctly decipher information is not a US GAAP accounting issue. There are plenty of perfectly legal US GAAP ways to report information that my rather unsophisticated algorithms for reading reported information cannot read. If the software algorithms were more sophisticated, I could read the information. Basically, public companies don't have to report so that simple algorithms can read their reported information. In my personal opinion it would be better if algorithms were easy to create, that minimizes the guessing game and increases the probability of software vendors creating software get algorithms right.
And so, I have found a way to distinguish these two different things. I will explain this next month when I roll this new approach out. Also, because the number of inconsistencies is getting so low, I am able to summarize every inconsistency category. This will help understand inconsistencies and tune the US GAAP XBRL Taxonomy. Stay tuned.
 Charlie
in Creating Investor Friendly SEC XBRL Filings
|
Charlie
in Creating Investor Friendly SEC XBRL Filings
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments