BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from February 1, 2014 - February 28, 2014
Minimum Criteria for Evaluating SEC XBRL Financial Filings
Prudence dictates that using financial information in SEC XBRL financial filings should not be a guessing game. Safe, reliable, predictable, automated reuse of reported financial information seems preferable.
So, how is safe, reliable, predictable, automated reuse of reported financial information achieved?
SEC EDGAR Filer Manual (EFM) rules are only the beginning of what is necessary for investors, analysts, and others to use this information. EFM rules are necessary, but they are not sufficient.
For a number of years I have been poking and prodding SEC XBRL financial filings to understand how to construct XBRL taxonomies within systems that allow extensibility. A byproduct of that poking and prodding is an understanding of what causes information contained in SEC XBRL financial filings to be ambiguous, to not be decipherable by automated computer processes, to yield "red flags" which indicate the information may not be trustworthy to automated computer processes; basically what causes reported information to be unusable by automated processes.
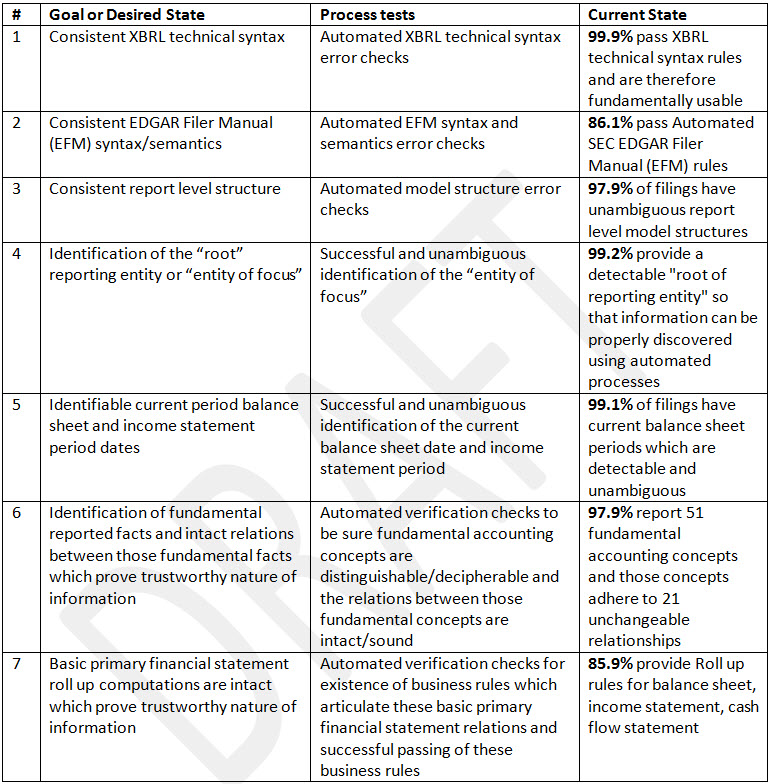
Or stating this another way: there is a set of minimum criteria which are necessary for making use of information contained in SEC XBRL financial filings. This is that set of seven criteria. These criteria state the goal or desired/necessary state, a process which can be used to test that goal, and the current state of SEC XBRL financial filings toward satisfying that goal or desired state:
 Click image to view larger version
Click image to view larger version
To be clear, meeting these seven criteria does not mean that all information in an SEC XBRL financial filing would be usable. These seven criteria are necessaryfor safe, reliable, predictable automated reuse of any information at all. But meeting these seven criteria is not sufficient for making use of all information reported in an SEC XBRL financial filing.
An interesting thing about these criteria is the current state of SEC XBRL financial filings in meeting the criteria. Today, SEC XBRL financial filings satisfy between the low of 85.9% for criteria #7 to a high of 99.9% for criteria #1.
And so, this is my set of minimum criteria which I will be using to evaluate the set of 10-K financial filings submitted to the SEC for 2013. My analysis of 7,160 SEC XBRL financial filings for last year helped me arrive at these seven criteria.
Are these criteria fair? I believe they are fair. What do you think? None of these criteria are subjective, all are objective. All are automatable. There has not been one accountant that I have talked to who has articulated specific objection to the criteria.
The proof is in the pudding as is said. No one that I am aware of has shown successful use of basic financial information within SEC XBRL financial filings. And I mean 100% automated reuse without the need for manually adjusting information or writing special algorithms to handle special situations. I mean 100% automated reuse.
And I am not even saying that all my rules are 100% correct. You can see the results that I get, note the current state percentages. Don't think my rules/criteria are correct? I will take any suggestions which result in improved success rates. Again, this is not subjective and this should not be a guessing game. There are exactly three moving pieces here:
- The SEC XBRL financial filings.
- The rules or criteria.
- The software algorithm for making use of information.
The goal is simple: 100% success for each criteria. Change the filing, change the rules, or change the software algorithm. Pretty straight forward. The goal is system equilibrium.
So far there are approximately 1,000 SEC XBRL financial filings, or about 20% of total filings which pass all seven criteria. Most SEC XBRL filers pass the vast majority but they don't pass all. For all those that do not pass, the exact reason they do not pass can be seen in their SEC XBRL financial filing. Whether the filing should be changed, whether the rule/criteria should be changed, or whether the software algorithm should be changed can be somewhat subjective. Let me remind you:
Prudence dictates that using financial information in SEC XBRL financial filings should not be a guessing game. Safe, reliable, predictable, automated reuse of reported financial information seems preferable.
I am going to update all my information shortly after February 28th, the end of the 10-K season for most filers for fiscal year 2013.
If you have objective information which proves or disproves these criteria or if you have a better way of evaluating SEC XBRL financial filings or a more successful way of reusing reported financial information it would be great to hear your comments.
 Charlie
in Becoming an XBRL Master Craftsman, Creating SEC XBRL Financial Filings
|
Charlie
in Becoming an XBRL Master Craftsman, Creating SEC XBRL Financial Filings
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Wired: Can an Algorithm Write a Better News Story Than a Human Reporter?
A Wired article, Can an Algorithm Write a Better News Story Than a Human Reporter?, provides some interesting insight related to computer generated news stories and financial information such as earnings releases.
A great use of this technology might be by the SEC to send out comment letters to filers.
Interestingly, someone seems to be doing this already to some degree with XBRL.
Charlie
in General Information
|
Post a Comment
| Email
| Print
Financial Disclosure Algorithms
When an external financial report is created a disclosure checklist is many times used by external reporting managers, auditors, and other accountants involved as a memory jogger to make sure the financial report is created correctly. For example, here is a disclosure checklist provided by EY for reporting under International Financial Reporting Standards (IFRS).
Disclosure checklists are generally used after a financial report has been created.
But what if something different was done. What if software for creating external financial reports could read these disclosure requirements and then guide accountants through the process of creating a financial report? Seem odd?
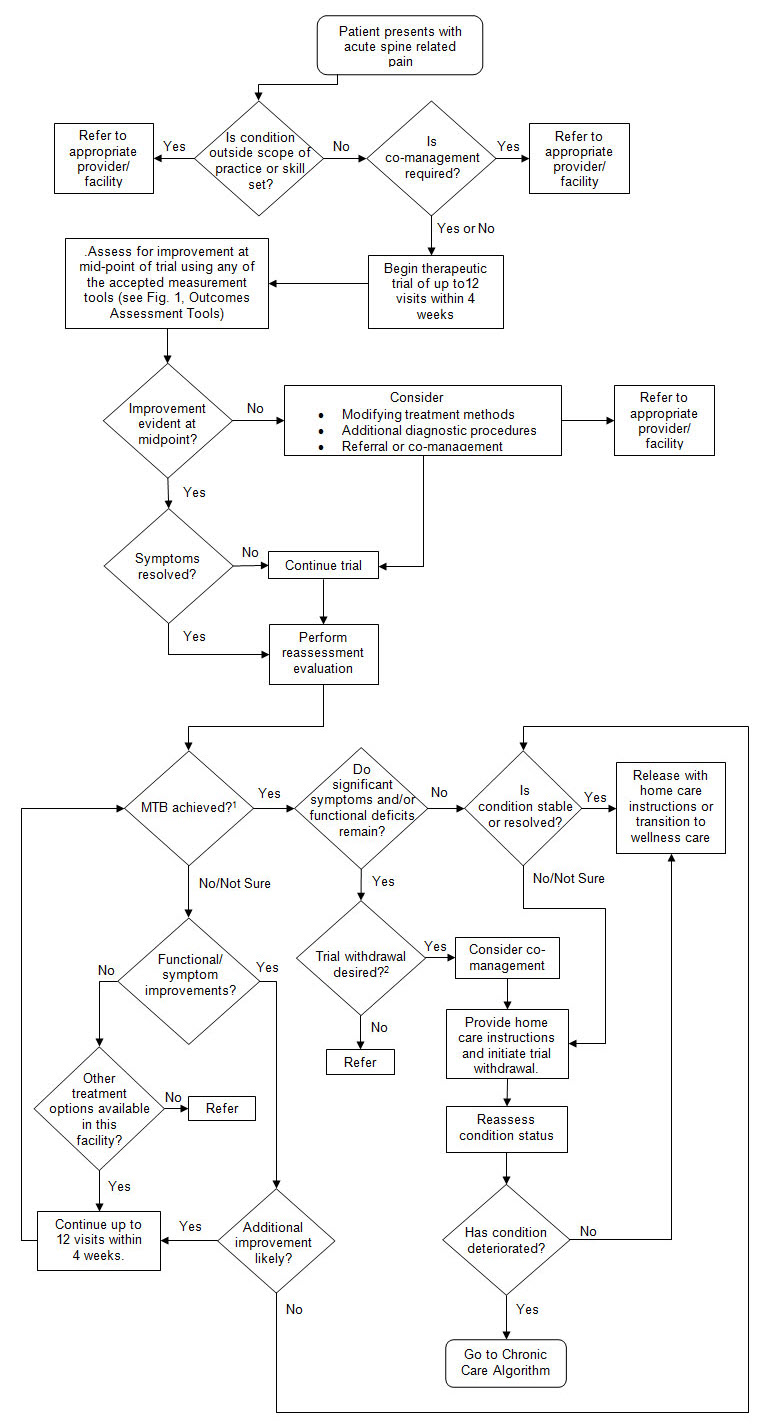
Consider this acute care algorithm used by chiropractors which was created by the Council on Chiropractic Guidelines and Practice Parameters (CCGPP):
 Click for Larger Image
Click for Larger Image
What is similar sorts of algorithms existed for financial disclosures? What if these algorithms were not only readable by humans like the diagrams above, what if they were readable by computer software? What if software could guide an accountant through the process of creating the disclosures of a financial report similar to the way TurboTax guides someone through the process of creating a tax return.
It is my prediction that this is where not only financial reporting is going but where reporting in many other domains is likewise going.
Perhaps accountants and others in other domains are not used to this sort of an approach and perhaps the advantages of such an approach are not understood by the masses yet. But the advantages will be understood when business users can compare this sort of an approach with current approaches.
The challenge here is that a boatload of metadata needs to be created in order to properly drive software applications. This is why I have been creating things like my list of financial reporting topics and financial report disclosures for a number of years. Testing, tuning, prototyping. The financial report ontology ties all these things together.
Why can what I am talking about work? How would it work? The video How XBRL Works explains how and why this can be achieved now and also why it was harder to achieve this sort of functionally in the past. The bottom line is that financial reports of the past were big "chunks" organized by presentation structure.
Now because of XBRL, financial reports can be digital. Rather than a few big chunks of things organized for presentation; a digital financial report, such as an SEC XBRL financial filing, is thousands and thousands of little pieces which are individually identifiable by a computer software application which are organized by meaning. The first level of meaning is information about the report itself. That report level meaning is shared across business reporting domains.
The next level, such as these high-level concepts, is the information within the domain itself.
The financial disclosure algorithms are things like "IF...THEN" statements such as "IF the line item property, plant and equipment exists on the balance sheet, THEN the estimated useful lives of each class of property, plant, and equipment MUST be disclosed."
This idea can be hard to grasp because the tool of choice for creating financial reports today, Microsoft Word, knows nothing about creating financial reports. Disclosure management software will change this.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Great Video about Issues with Spreadsheets
Charlie
in General Information
|
Post a Comment
| Email
| Print
Improved Information About Model Structure
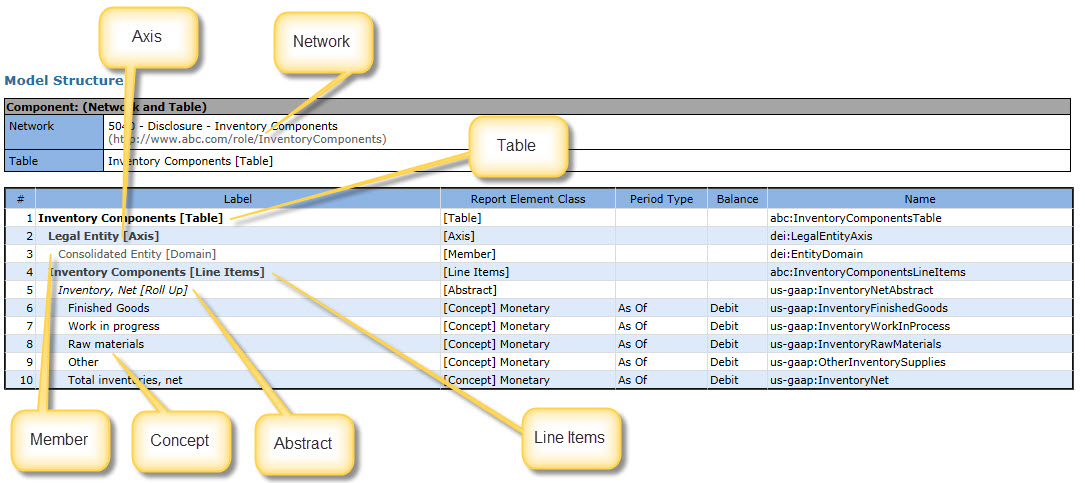
I posted information about the different categories of report element which make up an SEC XBRL financial filing (network, table, axis, member, line items, concept, abstract). This page elaborates on that a little further and shows examples of these different categories of report elements.
I also added a graphic which shows these different report elements:
 Click to view larger image
Click to view larger image
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

