BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from May 4, 2014 - May 10, 2014
SECXBRL.info Opens Up New Dimensions for Testing SEC Financial Filings
I have been severely limited in terms of the testing (poking and prodding) of SEC XBRL financial filings that I have been able to do in the past because of three things.
- I had to write my own tools
- My limited programming skills
- To make things easier, I focused on one period at a time
- Information was stored correctly, but in individual files so querying was slow
Those limits no longer apply. SECXBRL.info changes all of that. Why?
#1: Easy queries
First off, the information is stored in a properly organized database which makes two things happen: (a) query execution is fast, (b) queries are easy to write. Consider this summary of all SEC XBRL financial filings:
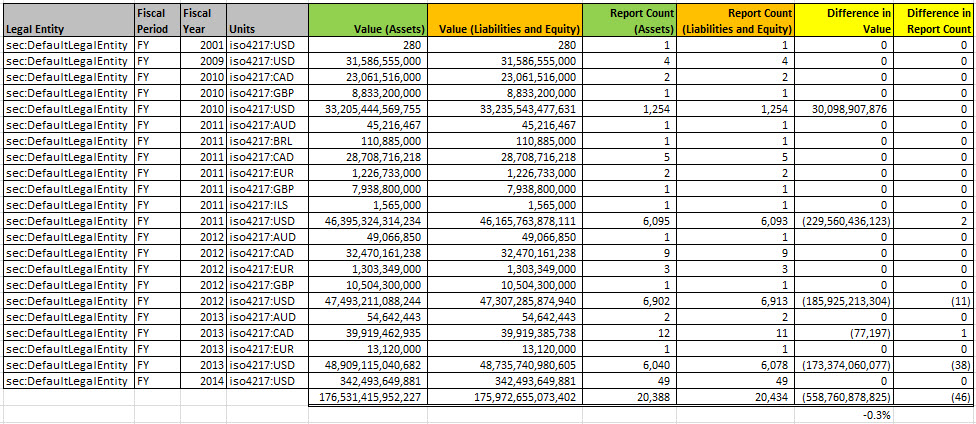 (Click image for larger view)
(Click image for larger view)
That is the result of two queries (links are provided for the queries), one for the value of assets and another for the value of liabilities and equity. Those queries take into consideration amended filings. They take into consideration that filers use different concepts to report liabilities and equity. They take into consideration something that I had totally missed, that not all filers report in US dollars.
So the SECXBRL.info API does a lot of stuff for you behind the scenes, so you don't have to deal with it. I know how to use a REST API, it is not that hard. I can program in Microsoft Excel and/or Microsoft Access using VBA. I used to have to deal with a lot of stuff in my code that I no longer need to deal with.
Take a look at that image above again. Click on it for a larger view. Accountants understand the accounting equation: Assets = Liabilities and equity. So it seems to me that it is logical to expect a query of "Asset" and a query of "Liabilities and equity" across all the filings to return the same values. Right? You might also expect that the number of filings count would be the same. But they are not. Why? Well, either the filings are wrong or the software doing the query is wrong.
Saying this another way, doesn't it seem reasonable that the SEC EDGAR system have a "dashboard" of some sort to make sure all the information in the system is correct? Seems to me that would help one manage the system, help keep the quality high, errors out of the system.
#2: Information for all periods
So the second thing I can do is query across many periods because of #1 (easy queries) and all the information exists in the database, not just one period. Here is something new that I can do. Consider this graph of the first quarter of SEC XBRL financial filings, this is information for the DOW 30, Q1, 2010:
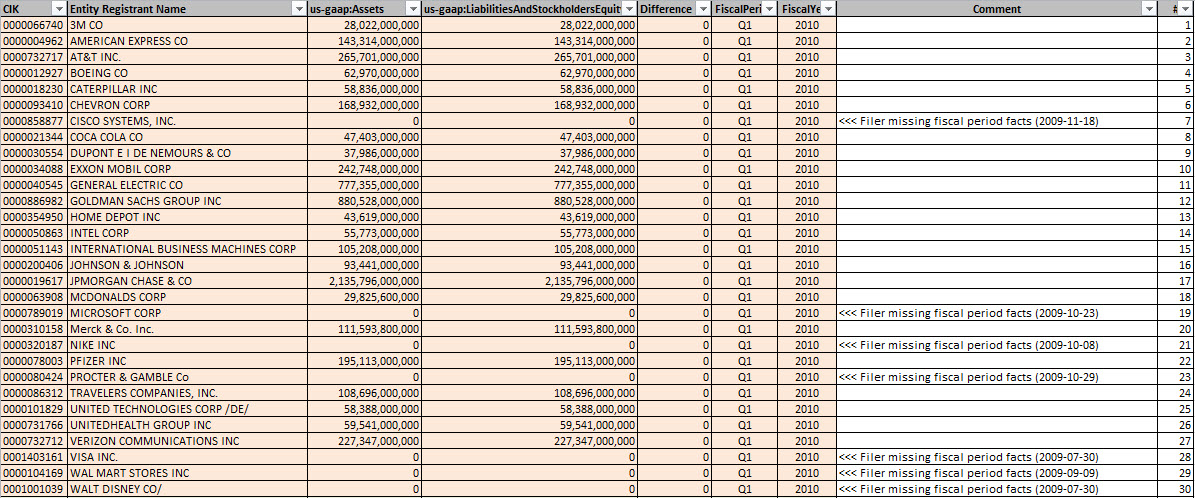 (Click image for larger view)
(Click image for larger view)
What you see is that for seven of the 30 DOW companies, they did not provide the fiscal period focus or fiscal year focus information in their filing. Therefore, you cannot tell with fiscal period the information relates to. Contrast the image above to the same information for the DOW 30 for fiscal year 2013:
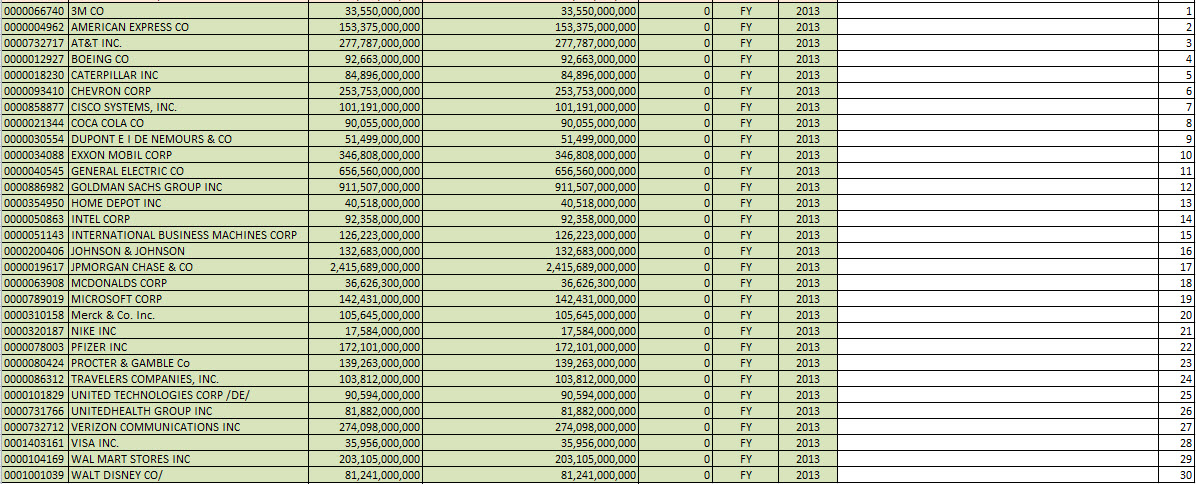 (Click image for larger view)
(Click image for larger view)
Quite a contrast, EVERY reporting entity in the DOW 30 now provides that fiscal period focus and fiscal year focus information. What does that mean? Reported information is improving and better queries are therefore possible.
Now, I am showing the DOW 30 because of the strong contrast between the 2010 filings and the 2013 filings in terms of providing the fiscal period and fiscal year focus information. This does not explain why the balance sheets do not balance for all financial reports within the SEC EDGAR database of SEC XBRL financial filings. In fact, it shows the opposite; it shows that they SHOULD balance because all of these balance for the DOW 30.
Here is why the overall dashboard does not balance:
 (Click image for larger view)
(Click image for larger view)
If you click on that image you see that Chrysler used the extension concept which they created, "chlr:LiabilitiesAndMembersDeficitInterest", to report liabilities and equity. Therefore, the software could not find the reported value. And so there is a value for assets and no value for liabilities and equity and therefore (a) this balance sheet does not balance and (b) it is impossible for all the balance sheets to balance and total assets of all SEC filings to equal total liabilities and equity of all SEC filings.
This analysis shows (this graphic specifically, test BS2) that assets and liabilities and equity was detectable for 99.6% or all but 29 SEC XBRL financial filings. It also shows that balance sheets balance for 6593 of 6622 SEC XBRL financial filings. As such, it would be quite hard for a filer to justify not having a detectable concept for assets or liabilities and equity and that those to values be the same within the same context. Very hard to justify.
If you download this ZIP file which contains an Excel spreadsheet you will find information related to the DOW 30, the Fortune 100, and the S&P 500. The information shows whether the balance sheet balances, whether the root economic entity could be found at all, and information about the fiscal period focus and the fiscal year focus.
All that information was obtained from the SECXBRL.info API using this very easy to use query. Looking at the parts of the query:
- Base query: http://secxbrl.xbrl.io/v1/_queries/public/api/facts.jq?
- Technical stuff:_method=POST&format=xml
- Concept: &concept=us-gaap:Assets
- Another concept: &concept=us-gaap:LiabilitiesAndStockholdersEquity
- CIK number: &cik=0000066740
- Fiscal period: &fiscalPeriod=FY
- Fiscal year: &fiscalYear=2013
You can fiddle with that by reading the API documentation, these example basic query examples which I created, or use this Excel application example to see how to write code.
# 3: Query hierarchical information
Most Excel users limit themselves unnecessarily. Excel is one tool, it is not the only tool. Microsoft sells another tool called Microsoft Access. It is a relational database. Excel is not a relational database. You can make Excel mimic what a relational database does to a degree using VLOOKUP or HLOOKUP functions. They get the job done in many cases, sort of. But if you understand how to use a relational database, such as Microsoft Access, you can do WAY, WAY, WAY more and doing it is substantially easier. Why? Because that is what relational databases do, they are really good at relating data.
Now, the same deal goes with Microsoft Access. It is one tool. While you can query hierarchical information using a relational database such as Access, it is harder to do that then using a tool which was built to do hierarchical queries.
So, the information within SECXBRL.info is laid out in terms of the meaning of the information. That information is represented in a lot of cases hierarchically. A relational query is not the best tool for doing a hierarchical query. You can do it, but it is not the best tool. You can pound a nail in with a crescent wrench, but a hammer works better.
The SECXBRL.info platform can do relational type queries, no problem. But they can also to queries across a hierarchy. The global standard XQuery is used for that. In fact, SECXBRL.info went two steps better. First, they use a third party extension of the global standard XQuery called JSONiq. That allows you to do lots of additional stuff such as use the JSON syntax if you prefer that over XML. Second, it has built in stuff to enhance query performance. I don't really understand that, multi-threading, load balancing, things like that. Personally, I don't care how it happens, I just enjoy the performance.
What this means is that you can write incredibly powerful queries which are beyond what most people today would even thing to query. I will write more on this later, but experience if for yourself by fiddling around with the "Compare & Search" functionality. I am not providing links because they are going to make some improvements to the GUI and so the links might change. Check back later, I will provide more information on querying hierarchies.
Bottom line
The bottom line here is that I can do way, way more poking and proding. Further, many others can also start poking and proding all those SEC XBRL financial filings. With the quantity and quality of tools increasing, it is going to be harder and hard for public companies, filing agents, software vendors, or others to get away with the poor quality filings that they have gotten away with in the past.
The quantity and quality of digital financial reporting tools will continue to increase. In fact, I believe that the pace of the increase will speed up.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Mitigating XBRL Report Element Misuse and Extension
An analysis of SEC XBRL financial filings contributed to identifying a set of seven minimum criteria which are necessary to make use of information reported in those filings. The notion of controlled flexibility was explained. Trying to connect that information with things that I am noticing in terms of report element misuse and inappropriate extension report elements from being created is my next step. I have identified the following five things which could mitigate misuse and inappropriate extension:
- Identify domain base classes, assign each taxonomy element to a base class: Categorize every report element into one business domain base category or class. The fundamental accounting concepts which I have created are a subset of the complete set of base classes. For example, a report element cannot be "assets" and be used as "equity". That makes no sense.
- Prohibit using report element defined in one base class as if it were some other class: Every report element must only be used to express something which relates to the intended base class. Said another way, report elements defined to be in one base class can never be used is if it were of some other class. Again, the concept "assets" cannot be used to express something which is "equity".
- Filer must identify base class of all extensions created: When a filer creates some extension report element, that report element must be associated with some base class or with some existing report element of the base taxonomy (which has been associated with some base class).
- Identify, articulate, and enforce computation relations between base classes: Unchangable computation relations exist between some base categories. Domain level business rules should enforce these computation relations. Again, the relations between the fundamental accounting concepts are an example of this. For example, why would it ever be the case that assets does not equal current assets plus noncurrent assets? (This is not about whether a filer actually reports noncurrent assets or if a filer uses an unclassified balance sheet, these are different situations which are handled by different rules.)
- Identify, articulate, and enforce allowed extension points: Some areas of an XBRL taxonomy are extensible. Other areas are not extensible. Where a taxonomy can and cannot be extended is up to the system which makes use of the taxonomy. This information must be clearly communicated.
So that is my first cut at trying to explain this. Most assuredly this needs more refinement, testing, and some examples to more crisply explain. It is trivial to include this information within an XBRL taxonomy using the power of XBRL definition relations to express this information.
I am not saying that my five points are suffecient to solve the problems of report element misuse or inappropriate extension. However, seems to me that they are necessary constraints in order to have quality reported information for use by analysts.
Any thoughts you might have would be greatly appreciated.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Understanding XBRL Definition Relations
This blog post summarizes information which is helpful in understanding one of the more powerful but under utilized features of XBRL: XBRL definition relations.
First, it is important to understand a few important things.
An important thing to realize is that information can be exchanged to the extent that the information is clear and usable by the computer which is making use of the information. This blog post about attaining high semantic clarity explains that statement in detail. A part of that semantic clarity is to provide some sort of classification system. Classification systems differ in the amount or level of information they provide.
Here is a summary of different types of classification systems in order to show the differences between the many types of classification systems:
- List: A list is just that, a simple list of things. A dictionary is an example of a list. All it does is provide a list of the "things" you are working with.
- Taxonomy: A taxonomy provides a list of the "things" you are working with just like a list, but it also provides "relations between the things". A taxonomy provides one or more sets of these relations generically in the form of some sort of hierarchy which articulates relations.
- Ontology: An ontology is similar to a taxonomy in that it provides a list of "things" and the "relations between the things". Ontologies tend to be more formal, more comprehensive. Ontologies provide representations of entities, ideas, and events, along with their properties and relations, according to a formal system of categories.
In essence, the difference between a list, a taxonomy, and an ontology is the thoroughness to which it expresses information about some domain which the list, taxonomy, or ontology describes.
There are all sorts of ways that lists, taxonomies, or ontologies can be created. There are four important factors to consider when you try and express the "things" and "relations between the things" in a domain.
- Expressiveness: First, the expressiveness of the scheme you are using. How capable is the method you want to use to express the things, the properties of the things, the interrelationships, the properties of the interrelationships.
- Standardness: Second, is the scheme you are using a global standard approach or is the approach proprietary.
- Human readability: The scheme you use to express information needs to be readable by the domain experts who can tell you if the things and the relations of things are accurate and by technical people who have to build software to interact with your representation. Human readablity is important when the information is initially created and also for maintenance of the information.
- Machine readability: Last but not least, the things and relations between things you express needs to be readable by computers who will make use of the information.
Many people who build formal, rich expressions of the information for a domain use OWL (Web Ontology Language) or RDFS (RDF Schema), both of which are global standards. One of the major problems with expressing business information using OWL or RDFS is that many times the business information is numeric and the relations between business information is computation related in nature and neither OWL nor RDFS handle the expression of that computation related information particularly well. To address that issue, the W3C created RIF (Rule Interchange Format) and a third-party created SPIN (SPARQL Interface Notation).
Most people don't realize that XBRL can also be used to create rich ontologies which express the things and relations between the things within a business domain. While most people understand how to express "the things" in the form of an XBRL taxonomy schema, general relations between the things using XBRL presentation relations, basic roll up computations using XBRL calculations, and to a lesser extent more complex computation and other types of relations using XBRL Formula; fewer people understand XBRL's power for expressing other sorts of relations.
Both a great example of what can be done with XBRL definition relations and additional semantics expressed by XBRL definition relations is the XBRL Dimensions specification. The XBRL Dimensions specification uses the power of XBRL definition relations to achieve its objective. One approach to learning about the power of XBRL definition relations is to reverse engineer the XBRL Dimensions schema. Check out the schema and check out XBRL definition relations provided in SEC XBRL financial filings and you can see how to wire things together.
Another way to learn about XBRL definition relations is to build something. This explains what I built.
The first thing you will want to do to express information using XBRL definition relations is to define the types of relations you will be expressing. This is done by defining an arcrole. Arcroles work like the predicate in an RDF-type subject-predicate-object relation. Defining an arcrole (predicate) is straightforward enough. Here are two examples which I defined: (both of these are prototypes)
- RDF-type relations and whole-part type relations: These are some RDF-type relations such as "class-subclass" and a set of different types of whole-part relations which I defined.
- Financial disclosure specific relations: These are some financial reporting specific types of relations which I created. I don't want to spend time explaining these relations right now, just consider these examples.
So again, defining the arcroles themselves are pretty straight forward. Understanding WHAT arcroles you need to create is harder.
A very important aspect of arcroles to understand is the XBRL Link Role Registry (LRR). Rather than have a bunch of different groups define arcroles which mean the same thing, there is a way to get your arcroles included in the global standard. These are existing arcroles which are in the global standard. The advantage of making your arcroles part of the global standard is that software support would likely be better and more consistent.
You can further describe information needed by your arcroles by putting properties on the definitionArcs. This is an XBRL taxonomy schema which I created with some made up properties.
Finally, I created relations between things and expressed those relations using an XBRL definition linkbase. The first definitionArc has the properties which I defined.
Now, XBRL definition relations work similar to the RDF-type subject-predicate-object scheme. In XBRL definition relations rather than using subject-predicate-object you use XLink (XML Linking Language) style syntax using from-arcrole-to. So by using XBRL definition relations and arcroles you define, you could basically redefine anything OWL or RDFS defines using XBRL.
If you want some additional examples, check out the financial report ontology. That contains plenty of examples.
A very good question would be WHY would you do this? Why would you define using XBRL what you could define using RDFS or OWL. Well, there are four primary reasons why I am doing this:
- RDFS and OWL are insufficient: RDFS and OWL are insufficient for expressing all the semantics which need to be expressed for the domain I am personally interested in which is financial reporting. I need to make use of XBRL calculations, XBRL Formula. So basically, my goal is to implement everything that I need and all that is necessary for what I need to achieve using XBRL syntax.
- Easier: I personally find this easier. The syntax is easier, the tools are easier to use. I have struggled, and struggled, and struggles trying to get the RDFS and OWL correct and I have not been able to achieve that goal.
- Flexibility: Syntax really does not matter. What is important is to get the semantics correct. If the semantics are correct, then the syntax which is used to express those semantics can be converted to any other syntax. Basically this boils down to flexibility. I would suspect that people who know RDF syntax can take the XBRL-based information and then convert that information into RDFS, OWL, or whatever format they might desire really.
- Standard: I want to avoid proprietary formats. There really is no point to reinventing some proprietary format if a global format works. I already have most of my information in a relational database already, moving to XBRL or RDF syntax, or any other syntax for that matter is a snap.
All this is like the wild, wild west currently. Who knows what syntax will be used in the future. Smart people are realizing the power of high semantic clarity in making machines serve humans, in attaining the quality level necessary, etc.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

