BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from July 26, 2015 - August 1, 2015
Public Company Quality Continues to Improve, 5 Generators Over 80%
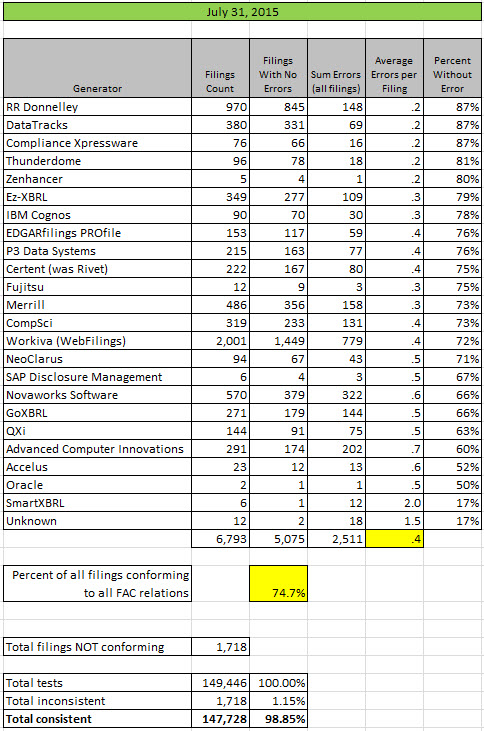
Quality of public company XBRL-based financial filings to the SEC improved yet again as measured against a set of 21 fundamental accounting concept relations.
Last month (June 30) there were 3 software vendors/filing agents who had 80% or more of their filings consistent with all fundamental accounting concept relations. As of July 31, than number has grown to 5. We are closing in on the point where 75% of all public companies are consistent with all the fundamental accounting concept relations, standing at 74.7% currently. We are also closing in on 99% consistency on a per test basis.
Per generator (software vendor or filing agent) results:
 (Click to view larger image)
(Click to view larger image)
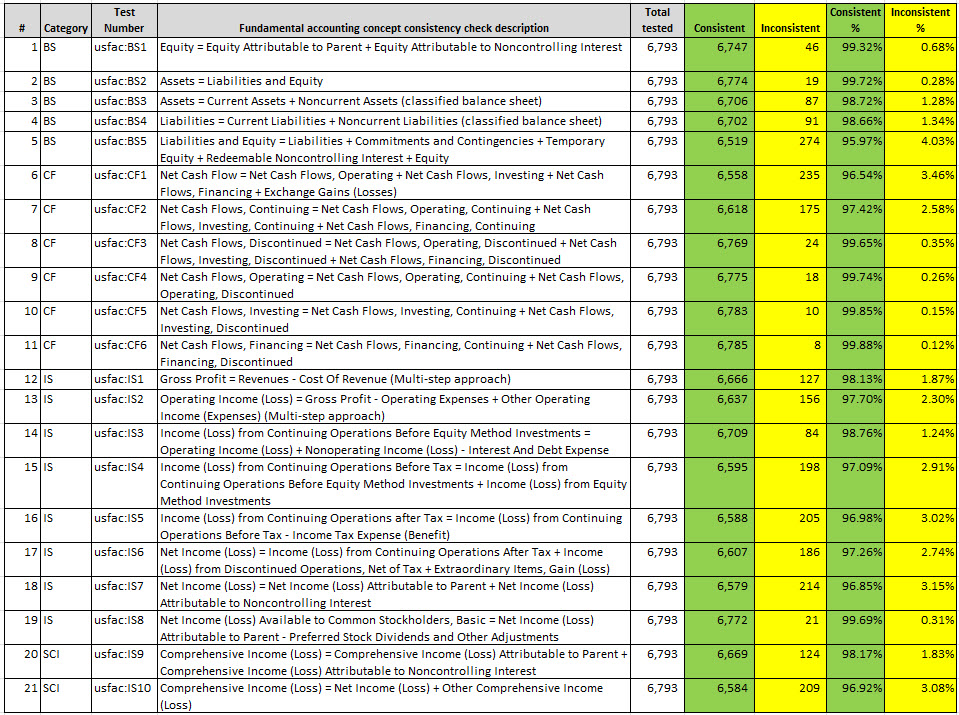
Per consistency test results: (note that on a per-test basis, all test are now at least 95% consistent or higher)
 (Click for larger image which has test labels)
(Click for larger image which has test labels)
Results for: June 30, 2015; May 29, 2015; April 1, 2015; November 29, 2014.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Understanding the Utility of a Reasoner or Inference Engine
A reasoner is software that is able to infer logical consequences from a set of asserted facts. Every reasoner uses some sort of logic. For example, first-order predicate logic is a type of logic. Every reasoner works with some set of axioms. An axiom describes some logical fact. The capabilities of a reasoner depend on the expressiveness of the kind of logic that the reasoner uses and the axioms provided for the reasoner and logic to work against.
Reasoners are sometimes referred to as inference engines because while, as stated above, reasoners work with asserted facts; reasoners can also use the rule of logic to deduce theorems. Theorems are indirectly deduced facts. Theorems are deductions which can be proven by constructing a chain of reasoning by applying axioms. Basically, a reasoner and an inference engine is the same thing.
A rules engine is also a reasoner. Another name for a reasoner or inference engine or rules engine is semantic reasoner.
An XBRL Formula Processor is basically a reasoner. Did you realize that? I will get back to that in a moment.
Clearly a human's capacity to apply logic is greater than a computer's capacity to apply logic. In fact, computers are machines and really can't think or apply logic. All that a computer can do is mimic or simulate or emulate a human's ability to think. Some computer programs that mimic human thought or perform some task for humans are called expert systems. Every expert system uses a reasoner to figure out what that system needs to do for the human and how to do it.
I pointed out that care has to be taken in order to express facts in a form that is safe, reliable, predictable, and repeatable. There are four catastrophic problems that a computer can run up against;
- Undecidability (i.e. must be decidable)
- Infinite loops (i.e. must eliminate possibility of cycles)
- Unbounded structures or pieces (i.e. must have known set of structures)
- Unspecific or imprecise logic (i.e. things like fuzzy logic is not allowed in this type of system)
Correctly balancing the expressiveness of a logic and the safety, reliability and predictably of a piece of software to return useful information takes conscious, skillful effort and execution. Years of experimentation in the area of expert systems and artificial intelligence has yielded invaluable information in achieving this balance.
First-order predicate logic is a formal way of expressing logic in a manner that is machine-readable.
While first-order predicate logic is expressive and powerful in performing work, it is not decidable and other problems can occur.
PROLOG is an attempt to address issues with first-order logic. In creating PROLOG, the problem of decidability and cycles was partially addressed by limiting which first-order predicate logic statements can be used to a Horn clause. But even PROLOG had issues and so further restrictions were made to first-order logic expressed using Horn clauses and Datalog was created.
DATALOG is a restricted subset of PROLOG. DATALOG is described as a query language based on logic. People are combining relational databases and DATALOG and creating what they call "deductive databases". Datomic is one such database. It seems that DATALOG is a de-facto standard deductive query language. (Here is more information on DATALOG.)
The semantic web folks seem to have had a similar evolution. They started with OWL FULL or older versions of OWL and then created limitations to deal with the problem of decidability. State-of-the-art semantic web technologies such as OWL 2 DL have been limited to solve the problem of decidability by limiting the logic to SROIQ description logic which is decidable.
OWL 2 DL has a boatload of reasoners. What I don't understand is the relative expressive power of an OWL 2 reasoner and something like DATALOG.
However, SROIQ description logic does not support expressing mathematical relations. The reason is, some math is not decidable. Eventually they will fix that most likely.
Back to XBRL Formula Processors. An XBRL Formula Processor is generally seen as something that validates XBRL instance facts. Says so right here in the XBRL Formula 1.0 Specification, see the Abstract section. But it is becoming pretty clear to me that what an XBRL Formula processor really is, is a business report reasoning engine. Or rather, that is what it SHOULD be in my opinion.
XBRL Formula has some distinct advantages over something like OWL 2 DL. The first advantage is that XBRL Formula does math. The second thing is that XBRL Formula has an understanding of XBRL Dimensions. That means that not only can XBRL Formula do math, it also supports a dimensional model.
However, there are several deficiencies in XBRL Formula processors:
- XBRL Formula processors do not support process chaining. Supporting chaining was discussed but they decided not to do it. PROLOG and DATALOG support chaining. Not sure is OWL 2 DL supports chaining.
- XBRL Formula processors do not understand and use the "general-special" or "alias-essense" standard XBRL arcroles. Basically, XBRL Formula processors don't understand class relations.
- XBRL Formula processors are focused on XBRL instances, they don't provide much functionality for working with XBRL taxonomy information.
My personal opinion is that the world would be a better place if something that had the combined functionality of something like DATALOG and an XBRL Formula Processor; if that combined piece of software struck the correct balance between expressive power and safety/reliability/predictability (i.e. it avoided those four logical catastrophes); and if there was a layer build that helped business professionals work with all this stuff effectively and successfully.
Per the law of conservation of complexity and the idea of irreducible complexity; not until this business report reasoner exists can XBRL ever really be usable by the average business professional. But imagine if such software did exist. Any business professional could build their own little or even big expert system inexpensively.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Vision of a Semantic Spreadsheet Getting Clearer
This is the definition of a spreadsheet provided by Wikipedia:
A spreadsheet is an interactive computer application program for organization, analysis and storage of data in tabular form. Spreadsheets developed as computerized simulations of paper accounting worksheets. The program operates on data represented as cells of an array, organized in rows and columns. Each cell of the array is a model–view–controller element that may contain either numeric or text data, or the results of formulas that automatically calculate and display a value based on the contents of other cells.
A spreadsheet is essentially a domain-specific programming language. What? A spreadsheet is a programming language??? There are essentially two fundamental pieces to a spreadsheet: (a) the model and the spreadsheet language and maybe (b) macro language that can be used to relate one cell with another cell. The model is expressed via a modeling language which expresses the rules that outline the structure of a spreadsheet. The language states things like a workbook is made up of spreadsheets, a spreadsheet is made up of rows and columns which intersect to form cells. The macro language used for expressing relations between cells and manipulating the values of cells or even the structure of the spreadsheets, columns, rows and cells of a workbook or even set of workbooks.
There are three key things about spreadsheets that one should be aware of:
- Note the statement "data in tabular form" in the Wikipedia definition of a spreadsheet.
- Note that "workbook" and "spreadsheet" and "column" and "row" and "cell" are presentation oriented terms and structures.
- Note that the programming language or macro language specifically understands what a workbook is, what a spreadsheet is, what a column is, what a row is, and what a cell is. The programming language also has general features such as "if...then" statements, "case" statements, and other such common programming functionality.
This is my definition of a semantic spreadsheet:
A semantic spreadsheet is an interactive computer application program for organization, analysis and storage of multi-dimensional information. Semantic spreadsheets developed as computerized simulations of set of paper accounting worksheets. The program operates on information represented as cells of an array, which can be visualized in rows and columns of something similar to a dynamic pivot table. Each cell of the array is a model–view–controller element that may contain either numeric or text information.
Unlike a spreadsheet which is connected presentational via the rows, columns, and cells of a sheet which don't have names but rather labels such as "Row 1" or "Column B"; semantic spreadsheets are connected together via the meaning and logic of the information itself.
Unlike a spreadsheet whose cells are manipulated by a programming paradigm that is generally procedural in nature; a semantic spreadsheet is described and verified to be represented correctly against that description using a logic-based programming language. PROLOG is an example of one such logic based language. Procedural and other types of programming paradigms can still be used to manipulate a semantic spreadsheet; but rather than interacting with the row numbers and column letters of the spreadsheet programs interact with the meaning of the information.
The best semantic spreadsheets support the import and export from/to global-standard information exchange formats such as XBRL or OWL 2 DL. Support for global-standard formats enables the exchange of information between different semantic spreadsheet implementations.
Semantic spreadsheets allow for the use of OLAP-based information but do not require the use of OLAP. Semantic spreadsheets overcome many of the problems of OLAP and problems of presentation-oriented electronic spreadsheets.
While semantic spreadsheets are very powerful and in the class of software deemed to be expert systems; they semantic spreadsheets are also very easy to use for three specific reasons:
- Semantic spreadsheets are business domain specific tools rather then general purpose tools.
- Business users making the use of semantic spreadsheets interact using business domain terms familiar to their business domain.
- Semantic spreadsheets strike an optimal balance between expressive power, reasoning capacity, and the reliability/predictability demanded for many business use cases.
Functionality is achieved by burying most knowledge engineering principles deep within software platforms and software applications used by business professionals (see the law of conservation of complexity). What business professionals loose in terms of the flexibility to solve any problem using general purpose tools; they gain in ease of use by both the absorbing of complexity within software and generous doses of the 80/20 rule.
Enterprise-class software extends the sound base established by global-standard semantic spreadsheets enabling business use cases that have additional needs to both leverage the solid foundation, but also extended that foundation to meet additional needs.
A digital financial report is a specific type of semantic spreadsheet and follow their same architecture however metadata is specific to the financial reporting scheme used by the economic entity creating the financial report.
The first semantic spreadsheet tool was created by _____(insert company here)_____ .
Charlie
in Digital Financial Reporting, General Information
|
Post a Comment
| Email
| Print

