BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from August 30, 2015 - September 5, 2015
Understanding the Importance of Z Notation
Z Notation is a formal model-based language for describing the behavior of a system precisely. Z Notation is an ISO/IEC standard. (International Organization for Standardization; International Electrotechnical Commission). The University of Oxford published this Z Notation Reference Manual.
I found this YouTube video which provides a brief overview describing Z Notation.
Z Notation is based on the rules of mathematics and uses first-order predicate logic. Z Notation is not a programming language, it is not machine-readable. It may seem odd, if you look at Z Notation but it is intended to be read and understood by humans.
The ISO/IEC standard Z Notation specification includes the following examples of the kinds of systems that have been described using Z Notation:
- safety critical systems, such as railway signalling, medical devices, and nuclear power systems;
- security systems, such as transaction processing systems, and communications; and
- general systems, such as programming languages and floating point processors.
If things are described in a written document, different people reading that document can interpret that document from their perspective. That perspective might be different that the perspective of another person. That leads to the problem of ambiguity in how a system actually works.
That is the problem a formal language such as Z Notation is intended to solve: reducing ambiguity, making descriptions more precise. Formal specifications are precise, concise and unambiguous. Because first-order logic is used a proof can be created which follows the rules of formal logic. Proofs and logic are used in science but the same principles of logic work in business also or any system really.
Deming says: A system must have a goal and everyone needs to understand that goal.
Financial reporting is a system. Financial reporting rules are described in documents. As a result, ambiguity and other things can creep into the system making the system less precise. Articulating the financial reporting rules using something like Z Notation would reduce unintended ambiguity, making financial reporting more precise.
In a blog post that I did a while back I mentioned a paper, An analysis of fundamental concepts in the conceptual framework using ontology technologies; written by Marthinus Cornelius Gerber, Aurona Jacoba Gerber, Alta van der Merwe; which points out ambiguities in financial reporting standards and how those ambiguities can be reduced using formal ontologies.
The folks that wrote that paper used OWL as the syntax for expressing the rules they were looking at. But OWL has a problem. OWL is expressive, but OWL is not expressive enough. For example, mathematical relations cannot be expressed using OWL. Other types of relations cannot be expressed. The easiest way to see this is to look at commercial products such as the Fluent Editor. The Fluent Editor augments the expressive power of OWL (specifically OWL 2 DL) by using SWRL, the Semantic Web Rules Language.
More precisely, Fluent uses what they call "safe SWRL". The fact that Fluent uses only a portion of SWRL which they refer to as "safe SWRL" points out a problem with Z Notation.
Notice that I specifically pointed out that Fluent uses OWL 2 DL. Recall from above that I said that Z Notation is based on first-order predicate logic. First-order predicate logic has some issues in that you can express things that cause computer software to get confused, get lost, or get caught in some sort of infinite loop from which it cannot escape. I discussed these issues in this blog post about Description Logic and in this blog post about "logical catastrophes" or catastrophic failure points.
And so OWL was partitioned into profiles which enable systems to be constructed which avoid specific catastrophic failures. That resulted in one OWL profile called OWL 2 DL which is based on SROIQ Description Logic. That profile is "decidable", as described in the blog post above.
But OWL 2 DL has two other issues. The first issue is that as mentioned, OWL 2 DL does not support expressing mathematical relations. The reason for this is that some mathematics are not "decidable". The second problem is that OWL 2 DL is really hard for business professionals (i.e. virtually impossible) to understand and therefore verify that rules that are articulated are correct.
Am I saying that Z Notation is easy for business professionals to understand? No. The vast majority of business professionals will not take the time to understand that notation. So that is a problem with Z Notation. Another problem with Z Notation is that it is likewise potentially not decidable and you could run into those logical catastrophes. A third issue with Z Notation is that it is not machine-readable.
So what is the right answer when it comes to precisely describing how financial reporting works or how a financial report works? We need that precise description to build software what works as needed and is interoperable with other software which has been created. We need the XBRL-based stuctured information to be understood the same way by all software vendors creating software.
This is what I think:
- Z Notation is important because it offers the ability to completely and precisely describe a system because Z Notation is based on first-order logic.
- However, not all first-order logic should be allowed; limit what is allowed, just as OWL 2 DL imposed limitations, in order to eliminate the possibility of logical catastrophes.
- Don't expose business users to the low-level Z Notation; rather, expose them to the results of what the Z Notation is describing. What I mean is to follow the ideas of this document and leverage patterns and compound/composite objects, let the business professionals interact with higher-level objects as I mentioned in this document, Understanding Blocks, Slots, Templates and Exemplars
- Teach business professionals enough about knowledge engineering (i.e. Knowledge Engineering Basics for Accounting Professionals)
- Syntax does not matter really. XBRL is being used, others prefer RDF/OWL. Which syntax prevales long term is really not relevant, technology changes. Lots of people prefer JSON these days.
- But the logic needs to be right, the logic needs to be understood, the logic must be exactly the same regardless of the syntax.
Why go through all this effort? The reason is, if digital financial reporting (or structured digital reporting, whatever you want to call it) is ambiguous and imprecise it simply will never work. If the details are not worked out correctly then digital financial reports can never be correctly created by business professionals. If business professionals have to rely on information technology professionals to create digital financial reports correctly, digital financial reporting can never really rise to the level that it needs to rise to.
The US SEC and FASB are doing a pretty good job of making XBRL-based public company financial reports to the SEC work. While far from perfect, things are beginning to work, which will make it easy to see why other things do not work, and allows one to see that it is all about the business rules.
It really is pretty basic as I have pointed out before: The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, business domain semantic rules, and workflow rules.
Z Notation helps in this process. While something like the Financial Report Semantics and Dynamics Theory should be expressed in Z Notation; accounting professionals and other business professionals would interact with digital financial reports and the information they contain in ways that they understand and are familiar with.
This is the only way digital financial reporting benefits can be realized. It is the only way expert systems can be constructed that work. This is all about business professionals understanding business rules. Precise rules eliminate ambiguity. Z Notation contributes to people agreeing on the rules.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Understanding that Syntax Doesn't Matter
People get distracted by syntax. This is particularly true of XML syntax, it seems to me, because XML is fairly readable by humans. Technical people seem to really enjoy funky looking syntax. Personally, I don't like messing around with cryptic looking technical looking stuff.
Which do you prefer. This nice looking table:
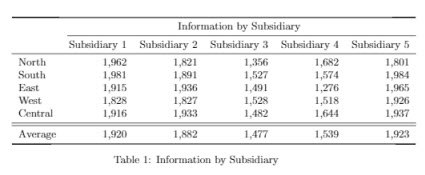 (Click to view PDF, might need to scroll down to see table)
(Click to view PDF, might need to scroll down to see table)
Or this syntax which was used to generate the table:
\documentclass{article}\usepackage{booktabs}\begin{document}\begin{table}\centering\begin{tabular}{l r r r r r}\toprule& \multicolumn{5}{c}{Information by Subsidiary} \\\cmidrule(l){2-6}& Subsidiary 1 & Subsidiary 2 & Subsidiary 3 & Subsidiary 4 & Subsidiary 5\\\midruleNorth & 1,962 & 1,821 & 1,356 & 1,682 & 1,801\\South & 1,981 & 1,891 & 1,527 & 1,574 & 1,984\\East & 1,915 & 1,936 & 1,491 & 1,276 & 1,965\\West & 1,828 & 1,827 & 1,528 & 1,518 & 1,926\\Central & 1,916 & 1,933 & 1,482 & 1,644 & 1,937\\\midrule % In-table horizontal line\midrule % In-table horizontal lineAverage & 1,920 & 1,882 & 1,477 & 1,539 & 1,923\\\bottomrule\end{tabular}\caption{Information by Subsidiary}\end{table}\end{document}
Pretty ugly. But a lot of people actually use that syntax for various reasons. That syntax, many times, has advantages. The syntax is LaTex. Click hereand you can see the syntax and the resulting rendering in a LaTex editing tool.
What is good about these different technical syntax is that you can generate any of them fairly easily. I have been doing experimentation of converting XBRL to PDF using XSLT, XSL-FO, and a thing called a FOP or Formatting Objects Processor. Here is the XSLT which is used to convert XBRL instance into XSL-FO which is sent to a FOP to generate PDF.
Which is better: LaTex or XSL-FO? I don't know that it really matters. You could convert from XBRL to PDF, HTML, Word, Excel, or many other formats.
What matters is that the information is structured, or digital, so that you can get at the information and then work with it precisely. The meaning of the information really matters a lot. But the syntax, not so much. If the representation of the meaning is precise and consistently understood, software tools can be made to do amazing things.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Public Company Quality Continues to Improve, First Generator at 90%
Quality of public company XBRL-based financial filings to the SEC continued to improve as measured against a set of 21 fundamental accounting concept relations. In May, the first generator reached 80% consistency for all their filings. In June, three generators reached the 80% mark. In July, 5 generators reached 80%.
In August, four very noteworthy things happened:
- The first generator reached the 90% quality level as measured by these fundamental accounting concept relations. Congradulation DataTracks!
- There are now 7 generators that have exceeded the 80% quality level (that means that 80% of all the public company filings created using that generator pass every one of the 21 consistency checks)
- Merrill moved from 12th place in terms of quality by this measure into 2nd place. Merrill's quality level went from 73% to 88%.
- The percentage of XBRL-based public company financial filings which were consistent with all of the fundamental accounting concept relations rose to 75.5%.
Here are the details:
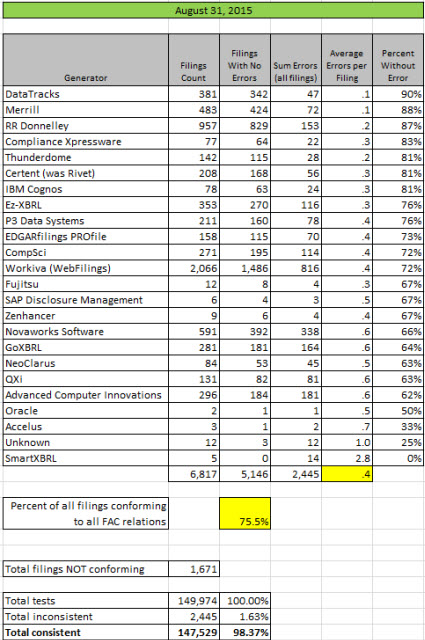
This graphic below (click for a larger, readable image) shows a comparison for June, July, and August 2015 and shows Merrill's big jump:
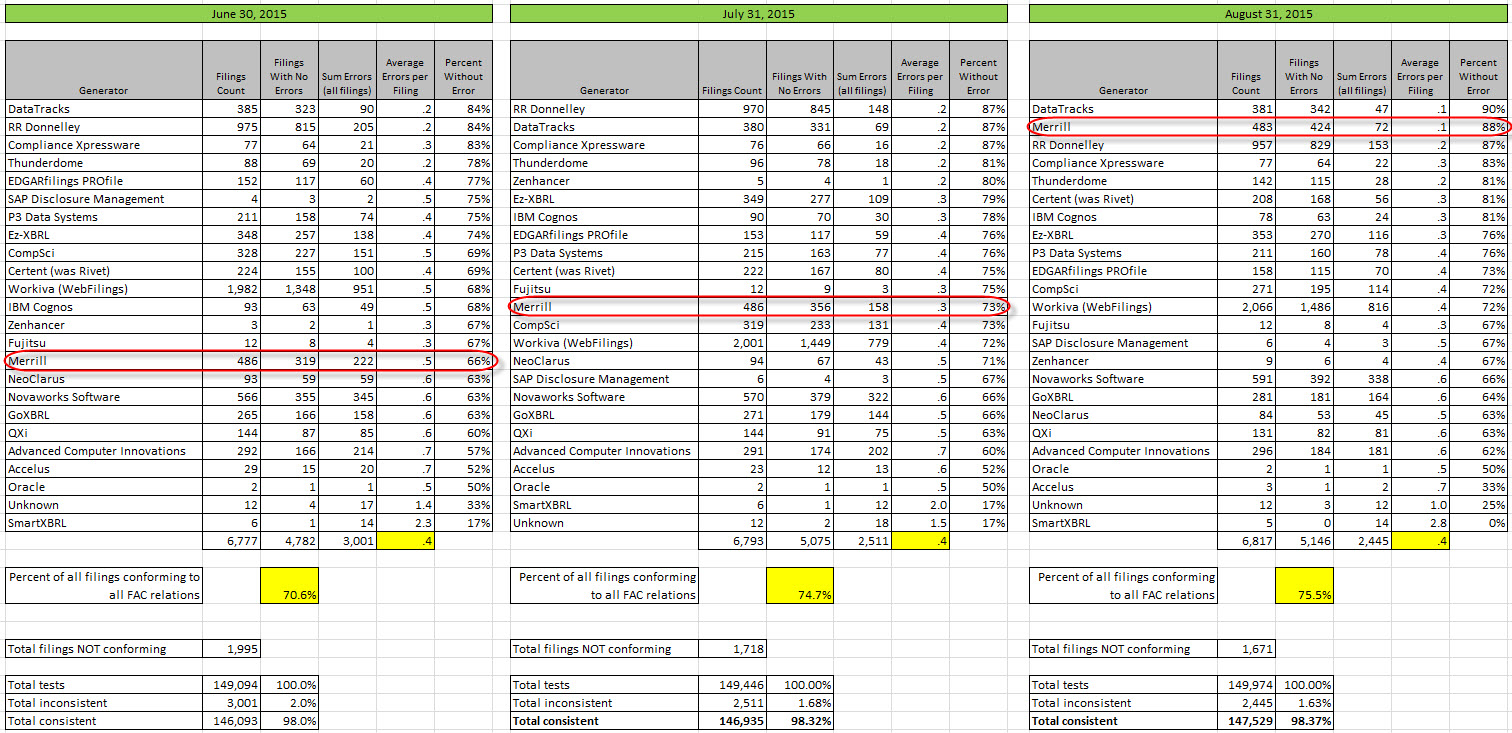 (Click image for larger view)
(Click image for larger view)
This graphic shows a comparison of prior measurements. The blue bar is the number of XBRL-based public company financial filings measured and the red line shows the number that are consistent with all of the fundamental accounting concept relations:
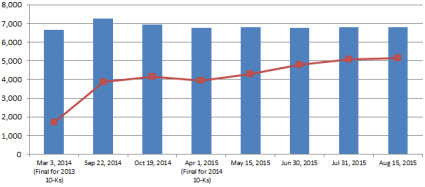
Thank you to all the software vendors and filing agents who feel they have an obligation to act and are taking the quality of XBRL-based public company financial reports seriously. I would point out that these progressive software vendors and generators who are pushing their quality higher are doing so without much direct pressure from the SEC or other authorities. They are doing so because it is the right thing to do.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Information about XBRL-based Public Company Financial Reports
The following is a summary of information about XBRL-based digital financial reports which may, or may not, be apparent to you. All this was not apparent to me until I observed very deeply many, many XBRL-based public company digital financial reports. This information is not laid out well in either the US GAAP XBRL Taxonomy nor in the SEC Edgar Filer Manual.
Notion of "Section" or "Report Fragment" or "Component"
While it does not have an official name in the EFM, section 6.7.12implies the notion of a "section" or what the US GAAP XBRL Taxonomy architecture calls a "report fragment" or what I call a "component":
6.7.12 A link:roleType element must contain a link:definition child element whose content will communicate the title of the section, the level of facts in the instance that a presentation relationship in the base set of that role would display, and sort alphanumerically into the order that sections appear in the official HTML/ASCII document.
The link:roleType link:definition text must match the following pattern:
{SortCode} - {Type} - {Title}
The {Type} must be one of the words ‘Disclosure’, ‘Document’, ‘Schedule’ or ‘Statement’.
I gave this idea a name, the "SEC Disclosure Type", and represented this information in the Financial Report Ontology:
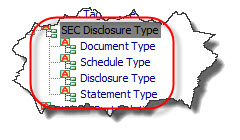
Notion of "Level"
Later on in that same section 6.7.12, the EFM discusses the notion of "level" and explains the ordering of the sections (described above) relative to one another. That section states, in part:
1. Each Statement must appear in at least one base set, in the order the statement appeared in the official HTML/ASCII document.
2. If the presentation relationships of more than one base set contains the facts of a Statement(to achieve a layout effect, such as a set of rows, followed by a table with a dimension axis on the vertical, followed by another set of rows) then the {SortCode} of that base set must sort in the order that the rows of the Statement will be displayed.
3. A Statement that contains parenthetical disclosures on one or more rows must have a base set immediately following that of the Statement, where all facts in its parenthetical disclosures appear in presentation relationships.
4. All base sets containing the contents of Footnotes must appear after base sets containing the contents of Statements.
5. A Text Block for each Footnote must appear in at least one presentation relationship in a base set.
6. Each base set for a “Footnote as a Text Block” presentation link must contain one presentation relationship whose target is a Text Block.
7. Base sets with presentation relationships for a Footnote tagged at level 2 must appear after all base sets tagged at level 1.
8. A base set with presentation relationships for a Footnote tagged at level 3 must appear after all base sets tagged at level 2.
9. A base set with presentation relationships for a Footnote tagged at level 4 must appear after all base sets tagged at level 3.
A couple of things. The EFM the term "base set" when they actually mean "Network" or "Network of relations" I believe. Regardless, what they are referring to is the sections or fragments or components that make up a full report which are represented by the "base set" or "Network" or "Network of relations".
I captured the notion of "level" in the Financial Report Ontology as follows:
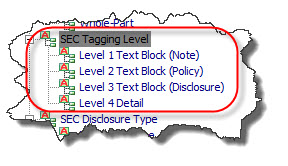
Notion of Report Element Categories
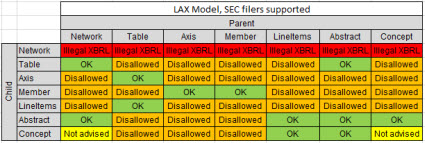
Both the EFM and the US GAAP XBRL Taxonomy Architecture imply the notion of report element categories.

Further, there are allowed and disallowed relations between these report element categories which I have summarized graphically as follows:
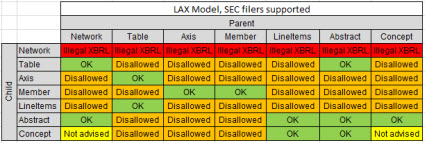 (Click image for larger view and more information)
(Click image for larger view and more information)
Notion of the Concept Arrangement Pattern
Concepts (and Abstracts which is a form of a concept) are arranged in patterns. The US GAAP XBRL Taxonomy explicitly mentions the "Roll Forward" pattern (Beginning balance + Changes = Ending Balance). But there are other patterns. These are summarized in the Financial Report Ontology as follows:
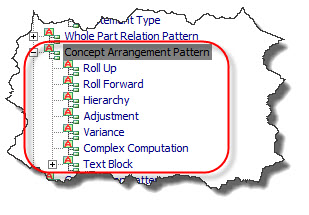
Notion of the Member Arrangement Pattern
Just like how concepts have arrangement patterns; the [Member]s within an [Axis] likewise have patterns. While not as fully developed (yet), there are two specific types of patterns which are articulated in the Financial Report Ontology:

A "Whole-Part" relation is where something is composed exactly of their parts and nothing else or more where the parts add up to the whole. A "Part-Of" relation simply describes the parts, but the parts do not add up.
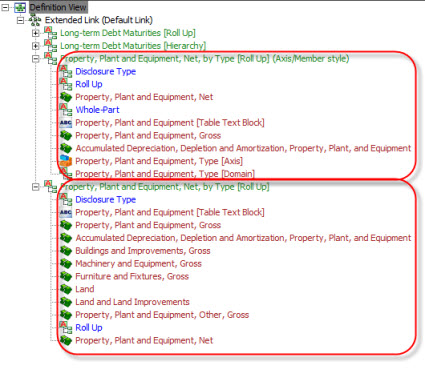
Relation Between Level 3 Text Block and Level 4 Detailed Disclosure
If you read the EFM or observe XBRL-based public company financial filings, you understand that there is a relationship between the Level 3 Text Block disclosure and the Level 4 Detailed disclosure of information. Here are two specific comparisons:
If you look at those two documents and you consider the other information above (and other information which I have not gone over), you see lots of patterns. To provide a basic example, consider those two disclosures above. These can be found represented in XBRL-based public company financial filings in at least the following four ways:
- Property, plant, and equipment by Type [Roll Up]
- Property, plant, and equipment by Type [Roll Up] (using Axis/Member)
- Long-term debt maturities [Roll Up]
- Long-term debt maturities [Hierarchy]
Notion of Disclosure Business Rules
You take all the information above and you can articulate knowledge in machine-readable form. Here is an example of four such disclosure business rules:
Those machine-readable rules (which you can grab here) can be used to generate the human-readable business rules needed by business professionals.
Business rules for every disclosure
Similar to the fundamental accounting concept relations business rules, imagine business rules for every possible disclosure. That is what is on deck for XBRL-based public company financial reports! Just like the fundamental accounting concept relations consistency can be measured, consistency of disclosures to the disclosure rules can likewise be measured.
A financial report is really many report fragments which work together to represent the entire report. The report fragments need to be internally consistent and consistent with other reoprt fragments. Why is this important? These rules are used to both describe and keep digital financial reports consistent with that description.
For more information, please read chapters 1 through 10 of Digital Financial Reporting.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding that Business Professionals Can Understand Business Rules
Article 9 of the Business Rules Manifesto states:
Article 9. Of, By, and For Business People, Not IT People
9.1. Rules should arise from knowledgeable business people.
9.2. Business people should have tools available to help them formulate, validate, and manage rules.
9.3. Business people should have tools available to help them verify business rules against each other for consistency.
Business rules can relate to data quality logic and business logic. Both are important to business professionals. Business rules are used to both describe a domain and to verify that information expressed is consistent with that description.
Take a basic data quality example: the allowed relations between the categories of pieces that make up a digital financial report. I call this the model structure relations. The categories of pieces include: Network, Table, Axis, Member, Line Items, Abstract, and Concept.
The US GAAP XBRL Taxonomy Architecture Section 4.5 describes the relations between those categories, sort of. You can go read the document and sort out the allowed relations.
This set of machine-readable XBRL definition relations likewise describes allowed/disallowed relations between the categories of the pieces. While that information is machine readable, it is hard for a human to understand that those XBRL definition relations are saying. It is almost impossible for a business professional to understand them.
Why does a business professional need to understand the relations? First, to determine if the relations are correct. Second, when working with a digital financial report, they need transparency into why something is wrong: which rule is being violated.
This is another way to express business rules:
 (Click image to go to rules)
(Click image to go to rules)
That graphical view above allows a business professional to better understand the machine-readable rules. The tabular view below does the same thing.
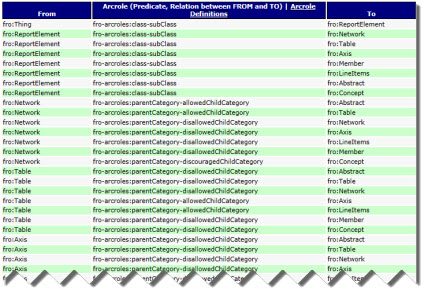 (Click image to view)
(Click image to view)
Business professionals don't know how to read Python code. Why would the XBRL US Data Quality Committee provide business rules in the Python format? First, business professionals cannot read them. Second, if you don't use the Python language to create your software you need to convert the Python into the format that you need.
A neutral format such as the XBRL global standard is a much better medium for expressing business rules. Software can read the rule and convert it into whatever format they might desire.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

