Understanding XBRL's Role in Knowledge Representation
My mantra relating to digital financial reporting has been:
The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
This is not something that I made up; it is something that information technology professionals understand. I first learned about this from an HL7 video which explained this.
The technical syntax rules part I understand. Things like the XBRL International XBRL 2.1 Conformance Suite help achieve technical syntax interoperability.
The workflow/process rules part I intuitively understand, it makes sense, but I have not done much digging into this yet.
The domain semantics rules part has been confusing to me in the past, but this is becoming clearer. I never could quite figure out the relation between something like RDFS/OWL to XBRL. How do you leverage what RDFS/OWL provides because these features seem necessary in XBRL also. Certainly the lack of appropriate semantic interoperability in XBRL-based financial filings provided ample evidence of this. Some experimentation and some discussions on the Semantic XBRL LinkedIn group yielded very helpful information.
One of the first extremely helpful things that I ran across was a comparison of the capabilities of OWL and UML to represent knowledge in the form of this document: Extending the UML Language for Ontology Development. The document explains two things. First the different "world views" of people with a UML background and a semantics web type background. Second, it explained all the different terms which people use. This document, Knowledge Representation/Translation in RDF+OWL, N3, KIF, UML and the WebKB-2 languages, is a little more complicated but it also has some very useful information.
What I obtained from the Semantic XBRL discussions, the documents above, and some other things I ran across I synthesized into an additional mantra:
First-order logic can be used to express a theory which fully and categorically describe structures of a finite domain (problem domain). No first-order theory has the strength to describe an infinite domain. There are two key parts of first-order logic. First, the syntax which determines which collections of symbols that are legal expressions in first-order logic. Second, the semantics which determines the meaning behind these expressions.
Someone made the statement "systems have boundaries" which is essentially the same thing that the paragraph above says. Machines such as computers don't do "infinite" very well, they need to deal with finite things.
OWL is a global standard knowledge representation language and is based some say on description logic and other say on first-order logic. Knowledge representation can mean both:
- knowledge description constraints and
- knowledge entering constraints.
Description constraints and entering constraints (data entry constraints) seem to be two sides of the same coin.
The term knowledge base seems to be where you store representations of some set of knowledge. Knowledge management is the process of managing knowledge.
And so how does XBRL fit into all of this?
XBRL needs to be seen as a knowledge representation languagerather than simply an information exchange format. What does XBRL need in order to be a knowledge representation language? Well, it needs all the same "stuff" that OWL provides.
This document which I put together, Knowledge Representation Terms Reconciled to XBRL Semantics, reconciles the features of RDFS/OWL/SKOS and UML to XBRL. Note two things in the document. First, there are a lot of things that RDFS/OWL/SKOS and UML provides that the XBRL global standard does not currently provide. Most of these things fit into the category of expressing relations between concepts such as what class a concept belongs to, "partOf" type relations "hasPart" type relations, and so forth.
But you can also note that XBRL provides a lot of things that RDFS/OWL/SKOS and UML do not provide in terms of expressing domain semantics:
- the notion of a "fact"
- a "units" registry
- the ability to express different types of numeric relations such as "roll up" and "roll foward" and "adjustment"
- the notion of a "hypercube"
Those are just a few. Now, the things that XBRL provide are higher level than RDF/OWL/SKOS and UML. On the Semantic XBRL discussion list someone described RDF/OWL/SKOS as a lower-level language. They are very flexible and you can really do a lot with them. But, because they are such low-level they are extremely hard to make use of.
I see XBRL as a practical knowledge representation "sweet spot" for business reporting. It provides additional "layers" which are needed for business reporting. Could you recreate what XBRL offers using RDF/OWL/SKOS? Absolutely you could.
So, could you duplicate what RDF/OWL/SKOS offers using XBRL? I think so. One of the things that I have already done is express different types of whole-part relations, class-subclass, and class-equivalentClass type relations using XBRL. Here is that taxonomy schema. I used standard mechanisms offered by XBRL to articulate this information: XBRL definition relations and the ability to define custom arcroles.
Are my arcroles a global standard? No. But, if they got promoted to the XBRL International Link Role Registry (LRR) the would be.
Why is all this important? See the graphic below: (click the image for a larger view)
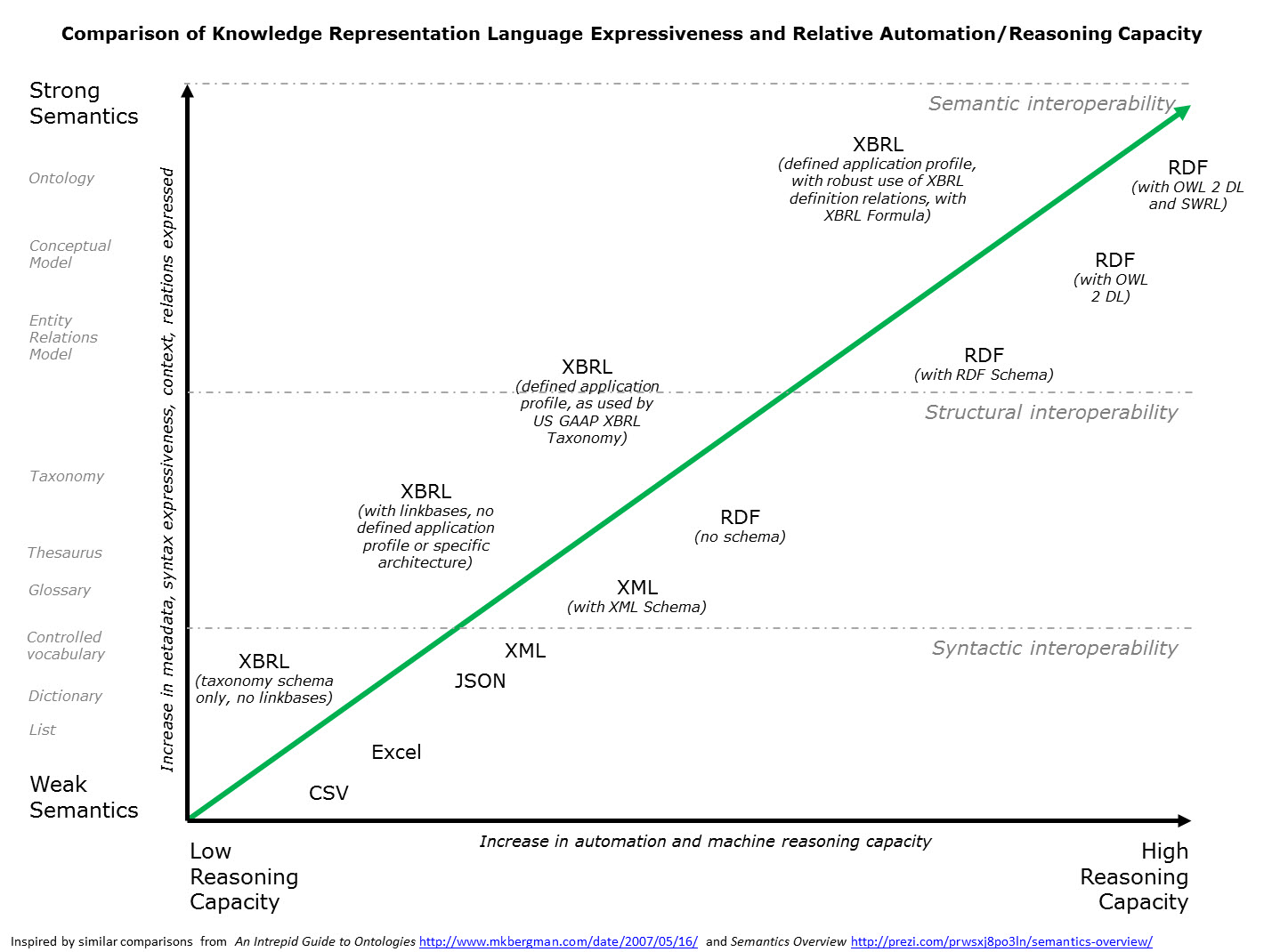 (Click image for larger view)
(Click image for larger view)
The point here is to enable a machine such as a computer to perform useful work for us humans. The stronger semantics that are expressed, the higher reasoning capacity a computer can have and therefore the more that can be automated.
Am I saying that business professionals are going to need to understand all this underlying technology? Not at all. The point is that the better this stuff is organized the easier it is for technical people to build higher-level layers that the business users interact with. The ugly technical stuff, which no business person will ever understand, will be buried in sophisticated software which makes all this useful functionality look like magic.
XML Schema-based approaches are too restrictive and inflexible. RDFS/OWL is too low-level and ultra-flexible making it useful for nearly anything, but far too complicated for business users to make use of. XBRL, with higher-level structures strikes a good balance between XML Schema and RDFS/OWL.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments