Choice for Financial Reporting Supply Chain: Guessing Game or Not?
People will ultimately recognize that most of the data quality issues of SEC XBRL financial filings are just lack of adequate verification software or sloppiness on the part of those creating the digital financial reports.
Most.
There are other issues which truly do need to be addressed by the financial reporting supply chain. I want to point out one of these issues.
First I want to articulate a key premise which is important to have in mind as one looks at this issue. This is the premise (from here):
Prudence dictates that using financial information in SEC XBRL financial filings should not be a guessing game.
Imagine if you had 100 different software applications which used 100 different software algorithms to unravel an income statement of a financial report. Why would software need to "unravel an income statement"? Well, because the US GAAP XBRL Taxonomy and/or SEC Edgar Filer Manual (EFM) don't force the information into a state where the information doesn't need to be unraveled; and because public companies which file with the SEC don't take it upon themselves to make their information straight-forward and easy for a machine to interpret.
That is the key: easy for a machine to interpret.
Humans are smart, machines such as computers are dumb. Computers only seem smart because humans meticulously constructed stuff to make the computers appear smart.
Humans can figure anything out. The question is, do you want to do what is necessary for a machine to figure out a financial statement so that you can leverage what the machine can provide you if the machine can figure out what you want it to figure out.
This is about a choice. How to achieve the result is a slam dunk. The question is, do you want to do what is necessary to make things work reliably, predictably, repeatedly, consistently, effectively. Again, "Prudence dictates that using financial information in SEC XBRL financial filings should not be a guessing game." If using the information is a guessing game, the information will certainly not be reliable. Full stop.
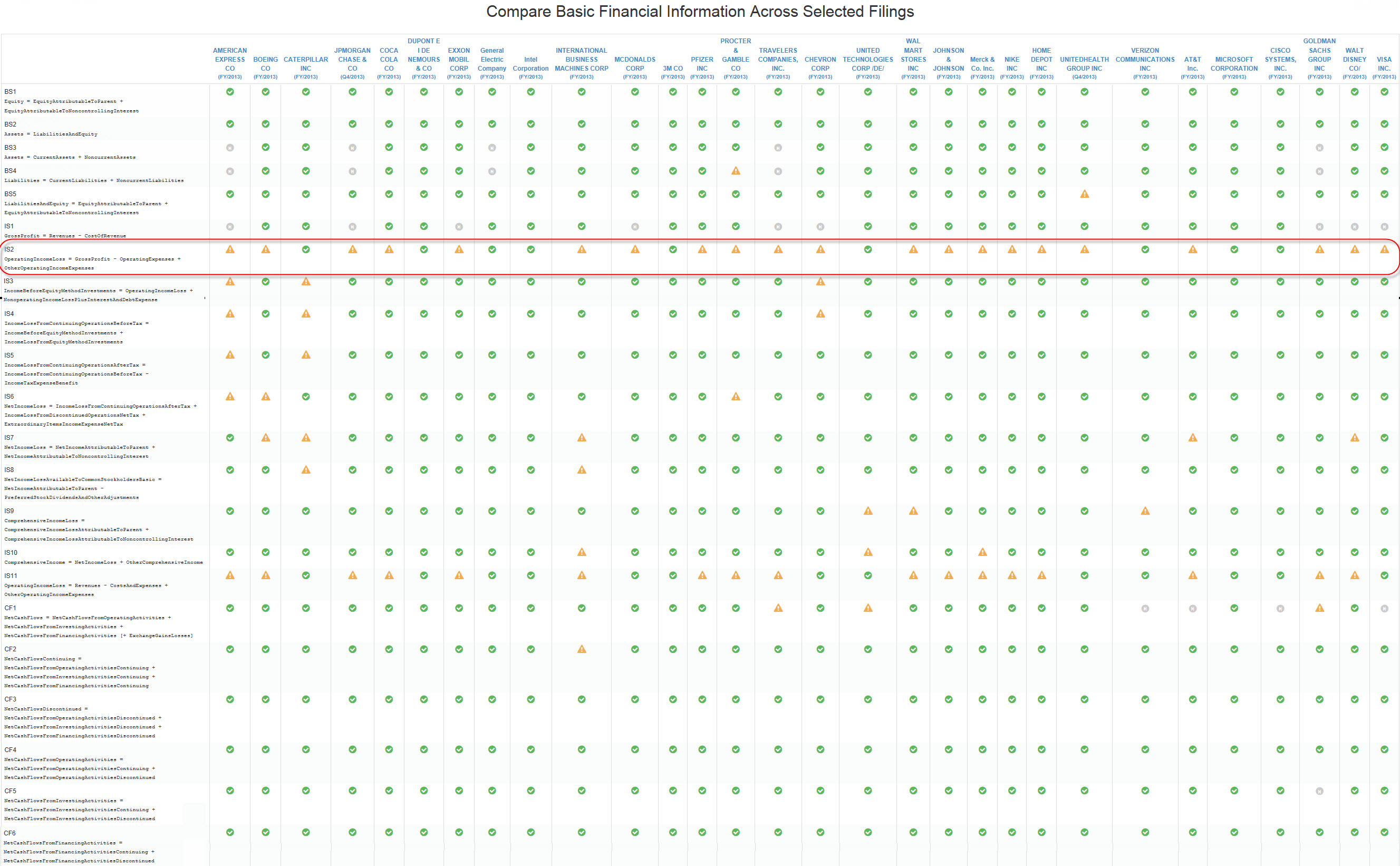
So, after all the obvious data quality issues are addressed, which they will be, you are still left with questions which are not about information quality. Take this specific example which can be seen by leveraging the fundamental accounting concepts validation provided by SECXBRL.info. You can look at the actual data or you can go to a JPEG which I created which highlights the information I want you to focus on:
 (Click on image for larger view)
(Click on image for larger view)
If you look at the JPEG image of the fundamental accounting concepts verification of the DOW 30 companies, you notice that there is mostly GREEN checks which show that the information is as expected by the SECXBRL.info software algorithms. For example, the second test from the top BS2 "Assets = Liabilities and equity". Balance sheets balance. The accounting equation. You would suspect that the accountants of the DOW 30 companies can get their balance sheets to balance. And they do. All of them.
Same for many other fundamental accounting concept tests. Most of the DOW 30 pass most tests. In fact, most reporting entities pass most tests. There are even 1281 SEC filers who pass ALL TESTS.
But why don't ALL SEC filers pass ALL of these fundamental tests? Well, they should. The primary reason an SEC filer does not pass one or more tests is that they have errors in their filings.
HOWEVER, there is another situation which is not an error.
Look at test IS2 on the JPEG. Operating Income (Loss) = Gross Profit - Operating Expenses + Other Operating Income.
It is not that the relationships is not valid or that an SEC filer does not follow that relationship that many of the DOW 30 don't pass that verification test. The reason so many SEC filers don't pass that test is because they don't provide the information to unambiguously sort out what is "Operating expenses" or what is "Other operating income".
Basically, this distills down to totals which unambiguously indicate what "Operating expenses" are and what "Other operating income" are not being provided in the SEC XBRL financial filing.
Now, it is not a requirement for these totals to be provided. The filers provide the details and any human could get their calculators out, add the information out, and unambiguously sort this information out. But a computer cannot sort this out.
And now some software vendor is going to say, "Well, sure we can...We can write algorithms which figure this out...", and so on. And the software vendor would be right, they could. However, the following is also true:
- It is expensive. To create the algorityms is more costly than not having to create them. It is also time consuming.
- It is brittle. As filers come up with new circumstances which cause new things to be reported, the algorithms will be broken, and then need to be adjusted. More expense, less reliability.
- It must be maintained. The expense and brittleness will be ongoing.
- Different software vendors will create different algorithms which will lead to different "correct" answers. Many of the difference will be caused by undiscovered errors, bugs in the algorithms.
Now, this is an option. But is it the best option? It is the desired option?
Reporting entities could choose to provide things such as the totals which lead to unambiguous interpretation of the financial information by machines. There is no requirement for the FASB to fix their US GAAP XBRL Taxonomy or the SEC to write new rules. SEC filers could solve this problem. Many actually are.
Financial analysts and investors can ask for this, to request that an SEC filer always report "us-gaap:Revenue" or some equivalent total so the guessing game does not need to happen for their filing.
XBRL does not cause the guessing game. How XBRL is employed causes the guessing game. Don't want the guessing game? Employ XBRL differently for digital financial reporting.
What I have pointed out is one straight-forward and easy to articulate example for what is making the financial information articulated in SEC XBRL financial filings harder to use. Every situation where the information is ambiguous can likewise be pointed out. Some situations are hard to explain than others, such as the exact situations where extensions cause issues. But like this situation which I point out, each of the other situations has options for solving the problems which are encountered.
Some situations will involve choices by the financial reporting supply chain. Others will not; it will simply be plugging a hole which everyone would agree needs to be plugged.
All this can be distilled down into a very straight forward set of bullet points:
- Get rid of errors: The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
- Manage entropy: Order is created from disorder. Minimize unnecessary options, meaning what is left is necessary options. Everything is consistent, unless there is a specific identifiable reason to be inconsistent.
- Write software to overcome what is left: Write software to overcome the balance of the inconsistencies.
- Feedback loop: Periodically reevaluate and adjust the system.
And then the guessing game is minimized.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments