Fluent Editor Helps Accountants See where Financial Reporting is Headed
If you want to get a peak at where financial reporting is headed, take a look at the Fluent Editor. You have to use your imagination a little, but if you play with that tool for a while it will likely change the way you think about XBRL.
Another important thing to remember is that Fluent is a general purpose tool rather than a specific use tool. That is important to understand because if you realize that, then you can understand that a tool specific to financial reporting can be an order of magnitude easier to use. This is because rather than handing the general needs of everyone, a special purpose tool is focused on financial reporting only.
 (Click image for larger view)
(Click image for larger view)
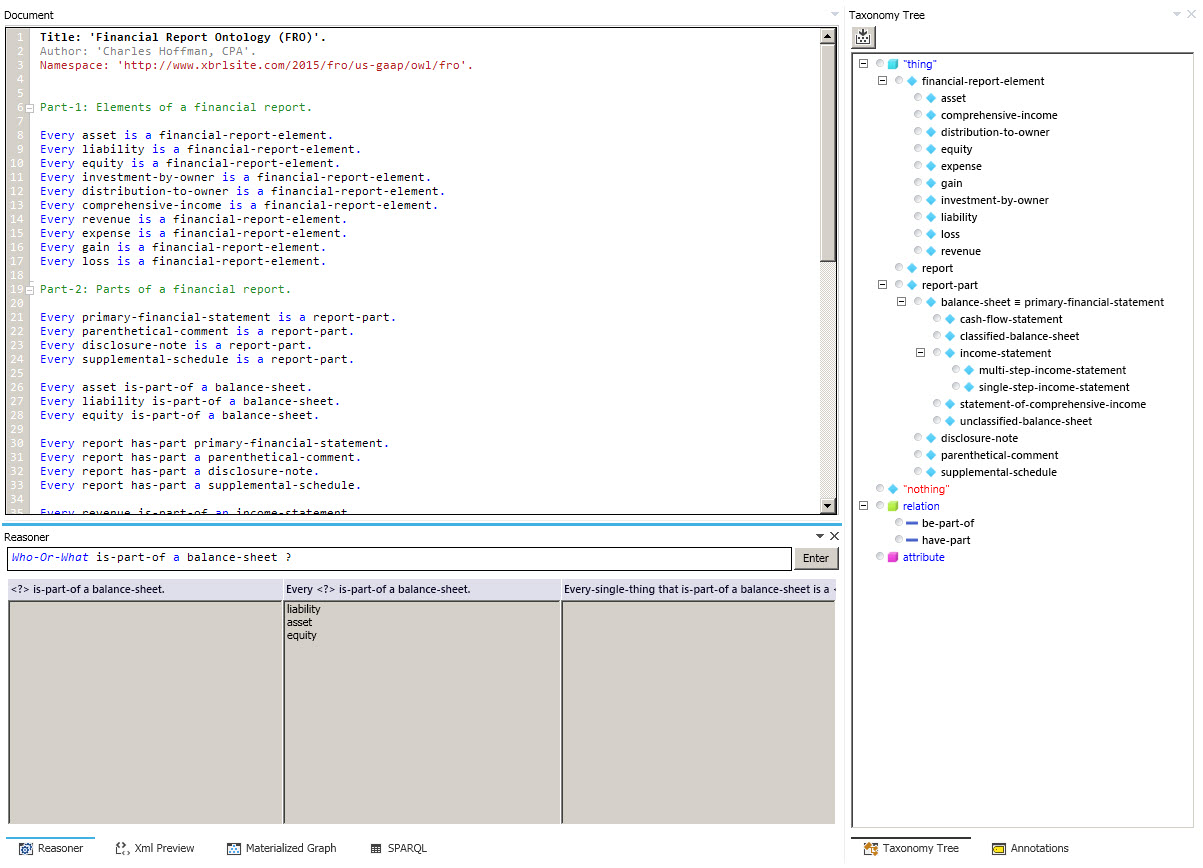
Fluent Editor is an ontology editor. In the XBRL world, they use the term "XBRL taxonomy". But don't be fooled by the terms. The interesting thing about Fluent is that rather than editing using the syntax of the language you are using, the user edits using controlled natural language.
This YouTube video shows the Fluent Editor in use.
A controlled natural language is a subset of natural language which uses restricted grammar and vocabulary in order to reduce (or eliminate) ambiguity and complexity. The user of the application works with what looks like English language sentences. I was able to do more in one day than I could in six months trying to figure out an OWL editor! Literally.
There is one thing that Fluent makes crystal clear for those who still don't grasp that syntax really does not matter. Take a look at the following:
- Fluent syntax: This is an HTML printout of what the application user works with. This is the actual syntax stored in the native format of the application.
- RDF/OWL syntax: This is the RDF/OWL that you get when you export or save the information to a global standard format.
- OWL/XML syntax: And here is the OWL/XML format.
All three of those files say EXACTLY the same thing. They are 100% interchangeable. Really.
Syntax does not matter.
What if you could edit XBRL taxonomies in that manner, using natural English sentences. But rather than using general sentences (i.e. OWL can be used to represent things in many, many different domains so the tool is very flexible), you used an even more restrictive syntax which applies ONLY to financial reporting?
What does that get you? Ease of use. The more flexibility and options that you have, the harder things are to use. Clearly you need the RIGHT flexibility and options.
So think of financial reports. In the past the financial reports have been unstructured text. Today, because of XBRL, financial reports are structured. That is the role that XBRL provides, the structure of the information so that the pieces of information can be read by a machine. But XBRL knows nothing about financial reporting. But what if you explained financial reporting in terms that a machine (such as a computer) can understand. That is what the Financial Report Semantics and Dynamics Theory does. What a machine needs to know are the "things" you are working with and the "relations between the things". You then convert that information (the things and the relations between the things) into a technical syntax, preferably a global-standard technical syntax, and then the computer can do useful things for us humans. The machines can automate tasks which had to be performed manually before because the information was unstructured (and unreadable by machines).
This document, From SHIQ and RDF to OWL: The Making of a Web Ontology Language, seems really technical but if you wade through it, it really is not that hard to understand the key ideas it is communicating. There are two primary points which that paper makes:
- Some really smart people are consciously working very hard and are very directed to solve a very specific problem: safe to use machine-readable semantics.
- OWL 2 DL + a safe subset of SWRL is that "base" set of machine-readable semantics.
All this is NOT to say that business professionals will be dealing directly with all these technical things. As the controlled natural language that I started with in this blog post shows, all this can be distilled down to easier to interact with human interfaces. Complexity will be beat into submission. Market competition will see to that.
XBRL will evolve and converge with the functionality of OWL 2 DL + a safe subset of SWRL. What I do not understand is how XBRL Dimensions and XBRL Formula fits into this equation. One important thing to understand is that OWL 2 DL does not do math. XBRL, however, does do math via XBRL calculations and XBRL Formula. XBRL Dimensions provides higher-level functionality that RDF/OWL needs. Proof of that is the effort of the Government Linked Data to build their Data Cube vocabulary. This is now a W3C recommendation. That makes it clear that (a) data cubes are desired and (b) OWL does not have that functionality "out of the box" (i.e. it has be be constructed). I don't understand how compatible XBRL Dimensions and the W3C RDF Data Cube are.
What does all this mean? Digital financial reporting is coming to the masses. Public companies filing to the SEC in the XBRL format are providing the important detailed information as to how to make digital financial reporting work correctly. We are not there yet. But things are improving and becoming easier.
Who will be the software vendor that provides the killer app which will make professional accountants to want to leverage structured information? Time will reveal the answer to that question.
That is all I will say right now. Stay tuned for more information!
 Charlie
in Digital Financial Reporting
|
Charlie
in Digital Financial Reporting
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments