BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from January 5, 2014 - January 11, 2014
XBRL's Sweet Spot: Aggreed Upon Fidelity
A while back I did a post where I mentioned XBRL's "sweet spot". I am trying to zero in on the unique characteristics offered by XBRL. This is an updated list of that sweet spot, where XBRL seems to excel when compared with other alternatives for exchanging business information:
- Internal or external information exchange. First and foremost, XBRL is a global standard. While there are very good ways of exchanging information internally; if you need to exchange information external to your organization where you don't have control of the other system you need some sort of standard to avoid building expensive point solutions. XBRL is a global standard.
- Machine readable and also readable by humans. XBRL offers information which is machine readable but also inherently readable by humans. The reason information is readable by humans and machines is because of the rich set of domain business rules which explains the information. Software applications can therefore be constructed which make the information readable by both humans and machines. This is not to say users of the information can get a pixel perfect representation exactly as they desire to render the information without adding additional metadata. This is more to say that a very usable rendering of the information is possible given only the business rules of the information because of patterns which software can leverage.
- Larger transactions which tend to change. For example, a 50 or 100 page regulatory report packed with perhaps thousands of facts exchanged. This is as contrast to a small transaction with a small number of data points.
- Low to zero tolerance for errors in the information. For example, everything must tick and tie in a financial report and if things don't add up then those using the information could make bad decisions.
- Information which needs to be reconfigured. For example, financial statements are not static forms, they are dynamic. This is contrast to say a tax form which is static and the form cannot be modified by the person who fills out the form.
- Business people changing the metadata, no IT involvement required. For example, business people create financial statements. If the business user needs to adjust the metadata, the business user reconfigures the information without the need to call the IT department for help.
- Agreed upon transaction fidelity. As was pointed out be a very good video about HL7 and in another blog post, "The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax, domain semantics, and domain workflow rules." For example, a CSV file (comma separated values) is low fidelity, you can exchange information but CSV offers no way to associate rules with the information. XML schema offers some ability to verify the fidelity of the information in terms of technical syntax, but not domain semantics. XBRL offers much, much more in terms of business rules to insure information fidelity, very high-fidelity information exchanges are achievable using XBRL.
- Table-type, tree-type or open graph-type information is supported. CSV files can only express table-type information. The same with a relational database. Table-type information is homogeneous. But there are other types of information. Tree-type and open graph-type information is more heterogeneous and therefore harder to store in tables. XBRL can be used for table-type, tree-type and open graph-type information.
- Strikes a good balance between power and ease of use. While XBRL is not yet easy enough to use for business users, it is significantly easier than the much more powerful RDF/OWL/SPARQL "stack" of technologies. Even for the average software developer, XBRL is easier than RDF/OWL/SPARQL. Also, RDF/OWL/SPARQL does not really offer the ability to write the business rules necessary for the needs of business users. Evidence of this is the SPIN and RIF specifications which are used to express business rules. The way that I would state it is that RDF/OWL/SPARQL offers almost infinite flexibility and that makes it harder to use. XBRL offers, or should offer really, flexibility where flexibility is needed.
When everything is condensed down to its essence, the XBRL global standard is about enabling one business user users to exchange information with another business user or users without the involvement of the information technology department. A key piece of this is what I called an "open taxonomy" type information exchange. It was pointed out to me, and I agree, that it is more about domains which require flexible taxonomies. You cannot really have "open". Open means a hole. There cannot be holes in information exchanges. That leads to ambiguity and information quality problems. Flexibility needs to be carefully controlled. Different implementations of XBRL are taking different approaches. I don't think anyone has figured out all the moving pieces quite yet.
So few people understand how to tame the XBRL beast today. Some are zeroing in on it though. It is my observation that most approaches used today either throw out XBRL's most important feature which is its extensibility or use an approach which leads to a dead end because they are focused on thee wrong problem elements. Few craftsman understand how to appropritaly employ XBRL as it was intended to be employed.
The best opportunity to understand all the moving pieces is the SEC XBRL financial filings which are all publically available. They offer many, many clues of what to do and what not to do.
Someone was trying to wrap their head around all this and they wrote a narrative which tried to explain the moving pieces as they needed to understand them. I modified that narrative and this is what I came up with which attempts to explain the problem XBRL is trying to solve:
Automating the exchange of information between two or more internal business systems has traditionally required an expensive manual integration process via tightly coupled custom interfaces and secure networks. Integration with business systems external to one's organization was extremely rare. Integrations were often expensive, fragile, and handled only small, rather unsophisticated payloads of data from transactions.
The creation of the public internet changed that dynamic. The internet expanded the need to exchange information because more business systems were now connected. The public internet lead to the need for publicly available standards such as XBRL.
Modern integration methods support looser coupling but require standards or negotiated syntax and standard protocols and workflow rules. As information becomes more sophisticated and rich, semantic rules can be used to increase the fidelity of the information exchanged between sending and receiving systems.
Standards offer preexisting technical syntax, domain semantic, and workflow rules which enable the exchange of information that is not only readable/understandable to human business users but also is machine readable.
These higher-fidelity information exchanges allow for entire supply chains to be integrated by business users themselves, removing the information technology department from the equation. This allows for business users to control business processes, adjust the processes as deemed necessary, and otherwise avoid expensive 'point solutions' in favor of much less expensive but just as reliable standard, loosely coupled, dynamic, high-fidelity integrations internally and external to an organization and therefore across entire supply chains.
This is a work in progress. If you care to comment to improve this description please send me an email.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Trouble with Text Blocks in SEC XBRL Financial Filings
An analysis of the US GAAP XBRL Taxonomy network related to disclosing leasespointed out some rather significant issues related to [Text Block]s in SEC XBRL financial filings and in the US GAAP XBRL Taxonomy. This is a summary of what I discovered:
- Mismatched [Text Block] and detailed disclosure sets: There are not matched sets of [Text Block] level disclosures and detailed disclosures. This is particularly true if you consider how SEC filers use the US GAAP XBRL Taxonomy to create their disclosures. Basically, there should be a [Text Block] level disclosure for every detailed disclosure.
- Note level [Text Block]s don't match and will never match SEC filer organization of disclosures into notes. The essence of this observation is that the US GAAP XBRL Taxonomy is supposed to be used to report disclosures, not how SEC filers organized those disclosures into their notes to the financial statements.
- US GAAP XBRL Taxonomy networks tend to be HUGE, SEC XBRL filer networks tend to be very small. The average size of an SEC XBRL financial filer's networks is approximately 10 concepts. The US GAAP XBRL taxonomy networks are significantly larger than this, they tend to be rather large. SEC filers tend to take the large networks of the US GAAP XBRL Taxonomy and break their disclosures into much, much smaller pieces. This helps the usability of SEC XBRL financial filings, but mainly because of the missing [Text Block]s, SEC filers create a lot of extensions related to [Text Block]s.
If you take a look a an SEC XBRL financial filing you can see what is going on. Consider this filing. If you go to note level disclosures you will see that this filer create the concept:
jack:LeasesOfLesseeAndLessorDisclosureTextBlock
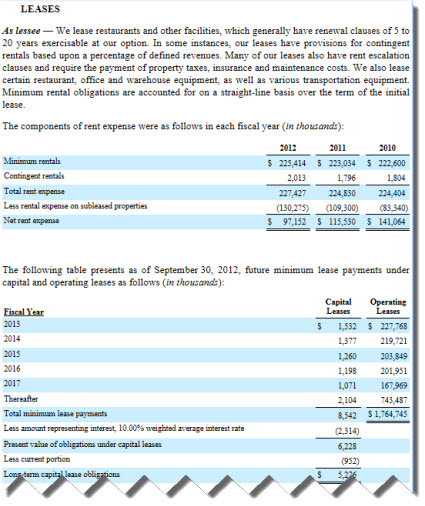
and used that for the [Text Block] which contains the entire note. And then for the [Text Block] which contains information for the specific disclosure of total minimum future rentals receivable, the filer used this concept:
jack:MinimumRentsReceivableExpectedToBeReceivedUnderTheseNonCancelableOperatingLeasesTableTextBlock
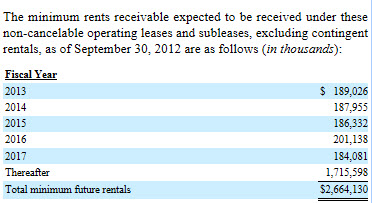
And then the detailed level no extension concepts where used because all of these are provided for in the US GAAP XBRL Taxonomy:
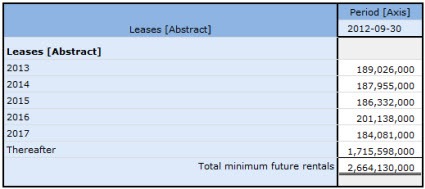
This is a common pattern which I saw for filers providing this disclosure.
You can go have a look for yourself here on this flat eash to scan rendering of the US GAAP XBRL Taxonomy. Or, go to the PDF above which has additional information.
Keep in mind that I am using the Leases network an example of a general problem with [Text Block]s. These same issues relate to pretty much every network.
Charlie
in Becoming an XBRL Master Craftsman, Creating Investor Friendly SEC XBRL Filings
|
Post a Comment
| Email
| Print

