BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from December 1, 2014 - December 31, 2014
Christmas Present from SECXBRL.info
SECXBRL.info provided a nice little Christmas present. Three actually.
The first is that they now support human readable renderings of report components rather than simply the machine readable information. Here is a basic example. Here is a list of the components of an entire filing, click on any link in the "Spreadsheet" column.
The second is an HTML format for pretty much every query. So, rather than viewing things in their interface you can view them as HTML pages. Here is a list of the DOW 30. Here is a list of the Fortune 100. Here is a list of the S&P 500. Here is a list of the Russell 1000.
The third present is a token which provides access to their API until January 15, 2015. Here is a link to their API which has the token embedded. (I don't know what sort of limitations they have on the token.)
Digital financial reporting is coming along nicely! Merry Christmas to all!!!
 Charlie
in Demonstrations of Using XBRL
|
Charlie
in Demonstrations of Using XBRL
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Disclosure Error Rate Consistent with Primary Financial Statements Error Rate
I have spent a good amount of time studying the primary financial statement information from XBRL-based digital financial reports submitted by public companies to the SEC. I have examined the relations between the fundamental accounting concepts on the primary financial statements. I have examined the fundamental ability to read any reported information, what I call the minimum criteria.
But what about the disclosures? Well, I have been looking at those also. Not in as much detail as the primary financial statements at this point, but now that I have a really good handle on the primary financial statements, I will dig into the disclosures more.
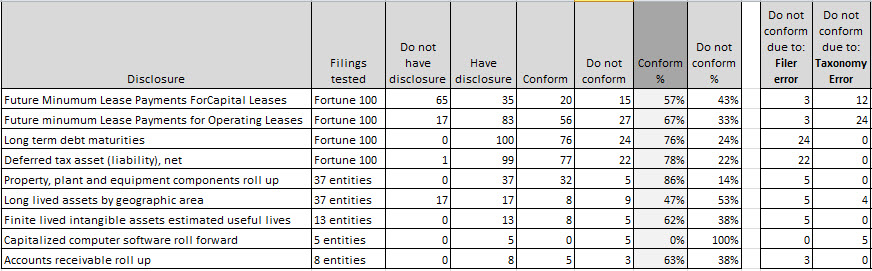
This is a summary of what I see right now. Below are summaries of the analysis of 9 fairly basic disclosures. I provide the name, a link to the analysis summary, and a percentage of SEC XBRL financial filings which conform to what I would expect the disclosure to look like:
- Future miniumum lease payments for capital leases: 57%
- Future minimum lease payments for operating leases: 67%
- Long term debt maturities: 76%
- Deferred tax asset (liability), Net: 78%
- Property, plant and equipment components roll up: 86%
- Long lived assets by geographic area: 47%
- Finite lived intangible assets estimated useful lives: 62%
- Capitalized computer software roll forward: 0%
- Accounts receivable roll up: 63%
Here is a table of this information:
 (Click image for larger view)
(Click image for larger view)
Clearly this is not conforming to formal scientific protocol, but I do think that it provides a reasonably good assessment of how well disclosures are being created. What I see is that the quality of at least these basic disclosures is fairly consistent with the quality of the primary financial statements. While the above 9 are samples of the total population, the primary financial statements analysis was of the entire population.
Conformance to the fundamental accounting concepts is about 60% for the entire population of SEC filers (excluding funds, trusts, and inactive filers). Conformance to the minimum criteria is about 57% for that same entire population. From what I can see in the conformance percentages above, it looks like disclosures are in the ball park of the fundamental accounting concepts and minimum criteria, let us just say 50 to 60% or so.
The most interesting thing though is that the testing "rig" that I used to test the fundamental accounting concepts works on the disclosures also.
If you look through the links in the list above you see a lot of PDFs which were manually created piece-by-piece by looking at individual SEC XBRL financial filings. But then you see this. Basically, I learned from creating and perfecting the PDFs. I applied what I learned and created far, far more automated process for analyzing the disclosures.
If you follow my blog you will likely recall my mantra:
The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
What I am realizing from doing all this work analyzing public company XBRL-based filings to the SEC is the low probability that the FASB or SEC or anyone else would be able to come up with all those rules proactively, in advance of having thousands of filings to look at using machine based processes. Who would have known all of the rules which would have been needed? While I thought I did, I realize now that I only had a partial set of understanding.
What will reveal the complete set is automated testing of digital financial reports which need to be created are the inconsistencies observed in SEC filings. This is actually consistent with what happened back in 2004. What happened then was the creation of the XBRL 2.1 conformance suite. Before the conformance suite was created, software had an interoperability problem. During and after the creation of the conformance suite most of the interoperability issues went away. For example, if you go look at #1 Technical syntax readable in the minimum criteria, you see that there is only 1 error in about 7000 filings. That is the "technical syntax rules" in my mantra above being satisfied.
All these tests like the fundamental accounting concepts and relations between concepts and the disclosure rules which are basically more detailed fundamental concepts and relations-type information. Rules. Here is the summary of the results. What drives that? Well, here are the mapping rules. Here are the impute rules.
Basically, imagine a battery of domain semantic tests (second part of the mantra):
- Minimum criteria type rules
- Fundamental accounting concepts and relations between concepts type rules
- Rules for defining the classes or categories into which every taxonomy concept fits
- Rules for defining the relations between classes or categories and the members of those classes
- Applying all of the above to the set of possible disclosures (this is a prototype of this information for about 226 disclosures, this is another prototype with about 500 disclosures, this is a vetted prototype of the complete list of disclosures organized within topics)
This is some of the basic knowledge of financial reporting. This is all mechanical type stuff. No judgment involved here. All this information will eventually be in machine readable for so software can use it to help get these mechanical pieces of digital financial reports correct.
This set of slides, Machine Readable Knowledge Representation Using XBRL for Digital Financial Reporting, summarizes all this as best as I can right now.
Digital financial reporting is just around the corner.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Public Company Digital Financial Reporting All Stars Triple
Back in 2010 I did some rudimentary but comprehensive testing on public company XBRL-based financial reports and was able to find 92 (about 1% of the total) which I dubbed "All Stars" who were getting a certain specific set of information in XBRL-based financial reports correct.
In March 2014, for fiscal year 2013 public company filings, I discovered a set of minimum criteria for reliably reading any information within a public company XBRL-based financial report. This document helps you understand those criteria, and this document shows how public company XBRL-based financial filings stacked up against those criteria. Testing revealed 1,281 All Stars (19% of total filers) back in March.
Yesterday I did my first testing run using commercially available software against those minimum criteria and I can proclaim that the number of public company digital financial reporting All Stars has grown to 3,936 which is 56.7% of the total 6,953 SEC filers.
So over half of the public companies get 100% of these minimum criteria correct which makes their XBRL-based financial filings fundamentally useable and reliable. This is NOT to say that all of the information in the digital financial report is correct. The information is only reliable and meaningful to the extent that it can be tested and proven to be reliable and therefore meaningful and usable. Remember this truth:
The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
If you don't understand why the statement above is true, go back and watch this HL7 video. Given that truth, here is the logic which shows why the minimum criteria are necessary:
- Technical syntax is readable: Software works with some technical syntax, XBRL in the case of SEC XBRL-based financial filings. Software reads the syntax and therefore has access to the information expressed. No problem here what-so-ever. In my test set, only 1 filing had an XBRL technical syntax error. That filer is excluded as the information is unreliable because the technical syntax is unreliable.
- Edgar Filer Manual (EFM) automatable rules are conformed with: While not all EFM rules relate to the fundamental usability of the information, some do. Breaking these out is not that useful because so many filers pass all of these tests anyway. The specific EFM rules that are fundamental to reading the information are addressed below. And so, the 137 reports which do not pass automatable EFM rules are not considered trustworthy.
- Business report level model structure is conformed with: An XBRL-based financial filing is structured information and structured information, well, has a correct structure. This "model structure" is the relations between the different structural component categories: Network, Table, Axis, Member, LineItems, Concept, Abstract. (These rules are documented in the US GAAP XBRL Taxonomy Architecture. This blog post explains model structure in detail.) If you put an [Axis] within a [LineItems], what exactly do you mean? As such, the information in digital financial reports which does not follow the model structure rules is at a minimum ambiguous, at worst unreliable. And so, the 167 reports which don't follow these rules are not considered trustworthy.
- Root accounting entity discovered: If you can read all the information correctly thus far, you then need to discover the accounting entity or economic entity or the entity of focus of the report. That is all that this minimum criteria tests, that "root entity". Other related legal entities, business segments, geographic areas, and other such information breakdowns might be provided, but that is not what I am testing. Just the basics, the accounting entity of the report. The EFM has rules for articulating this entity of focus. This is easily discoverable for all public companies, except for 52. Because the accounting entity is ambiguous, the information in these 52 reports is unreliable.
- Current balance sheet date and year-to-date income statement period are discovered: Once you understand the accounting entity you need to work with, you need to understand the period within the report that you need to work with. Again, the EFM rules provide guidance on expressing this information, and all but 110 reporting entities follow that guidance so their current balance sheet date and the year-to-date income statement period is discovered. Again, clearly you will want to work with other periods, but that is NOT what I am testing, only the current period. And, if the current balance sheet date is not discovered and the year-to-date income statement is not discovered, the report is ambiguous.
- Reporting units discovered: (MISSING MINIMUM CRITERIA) So I made a mistake in my minimum criteria. The SEC also made a mistake and does not require a filer to indicate the monetary reporting units starting point. This is not a big deal because the vast majority of public companies report in US Dollars. However, not all do. This is a flaw in the minimum criteria, I don't know the extent that it impacts reported information, but it is low. As such, some entities that you might see are NOT in US Dollars. My bad, I will fix this. SEC might need to fix this also.
- Fundamental relations are intact: The fundamental trustworthiness of the information is checked using fundamental relations between reported facts. For example, "Assets = Liabilities and equity"; "Net income (loss) attributable to parent + Net income (loss) attributable to noncontrolling interest = Net income (loss)". For a comprehensive list of these fundamental relations see here. Now, that list needs to be tuned for the different ways entities report and for different accounting activities reported. For example, a bank reports differently than a retailer. As such, the fundamental relations are adjusted for this reality using what I call report frames. Here is a list of such report frames. This document helps you better understand report frames. If all of these expected relations are intact, that is evidence that the meaning of the financial report is being interpreted correctly. But if the relations are not correct, that means software cannot fundamentally interpret this information because of an error in representing the information or because of some ambiguity.
- Basic primary financial statement roll ups exist and are correct: There are four basic roll ups which must exist: on the balance sheet (assets, liabilities and equity); on the income statement (net income (loss)); and on the cash flow statement (net cash flow). If those exist and if they roll up correctly, you can be confident that the primary financial statement information for the root accounting entity and for the current balance sheet date and year-to-date income statement date (which both the income statement and cash flow statement use). But if the roll ups are not articulated or they are articulated and they don't actually roll up, then you cannot trust the information.
And that is the minimum criteria. It is not a lot, but it is necessary. I am not even saying that it is sufficient. What I am saying is that it is necessary. It is a foundation which can then be built upon. It is something that can be measured to determine how public companies are doing right now. It is something which can be used to manage additional improvements in XBRL-based financial filings of public companies.
And now half of the public companies are getting this correct. This is awesome. But what is more awesome is that you can see the 43.3% who are getting these minimum criteria wrong so that they can be corrected.
Charlie
in Becoming an XBRL Master Craftsman, Digital Financial Reporting
|
Post a Comment
| Email
| Print
Example of Expressing Semantics Using XBRL Definition Relations
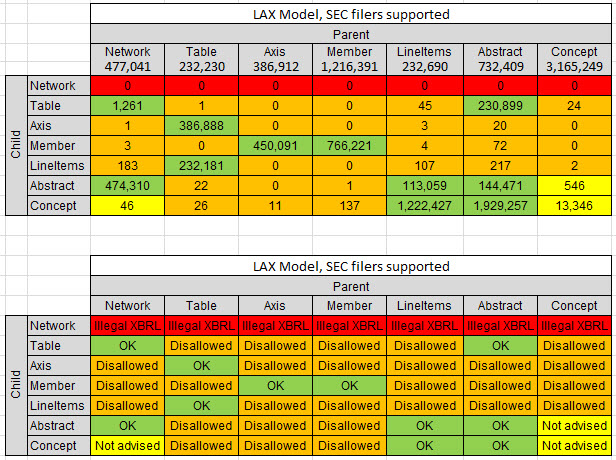
Here is an example of expressing semantics using XBRL definition relations. Consider the graphic below which shows two things. First, there is a matrix of the categories of the items that make up the structure of a financial report: Network, Table, Axis, Member, LineItems, Abstract, and Concept. In the columns is the parentstructural items. In the rows are the child structural items. In the TOP part of the graphic, the cell with the intersection of the parent and the child shows the number of times that relation exists in an SEC XBRL financial filing. The BOTTOM part of the graphic, the cell with the intersection of the parent and the child show whether that relation is OK or if it is DISALLOWED and I also included NOT ADVISED: (Click on the image for a larger view)
 (Click image for larger view)
(Click image for larger view)
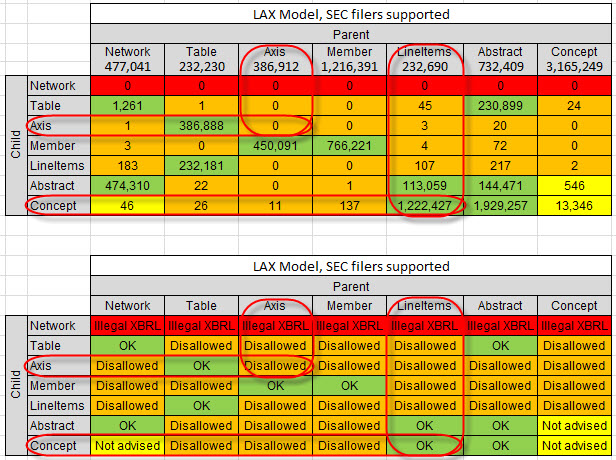
So here is the same graphic again with some things that help you read the information. If you look at the "Axis", from the parent you can see that there were 386,912 Axis used as a parent in a relation to some other concept. There were 0 occasions where an Axis was the child of a parent Axis. Basically, an Axis should never the child of an Axis; an Axis is the child of a Table. Note that there were 386,888 such occasions in SEC XBRL financial filings.
Same deal for the LineItems. There were 232,690 LineItems parents, and those parents had a Concept as a Child 1,222,427 times. The bottom part shows OK relations and DISALLOWED relations.
 (Click image for larger view)
(Click image for larger view)
Now, that information is pretty easy to understand if you are a human. How would you put this into computer readable terms using XBRL? Well, here you go. That is an XBRL definition linkbase. Hard for a human to read, but if you load the information into an XBRL tool, it would look like the following:
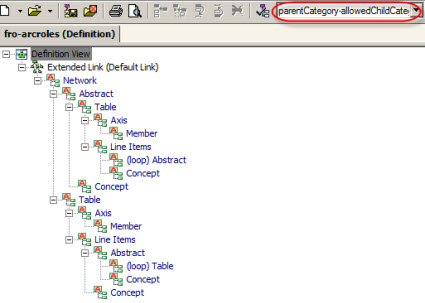
I don't have this represented perfectly yet, but it is close. The information in that hierarchy of relations is the exact same information that exists in the colored graphic above. I defined arcroles, using XBRL, to articulate the relations in the XBRL definition linkbase.
Imagine software being able to verify that you are not creating inappropriate or inadvisable relations. Imagine doing the same sorts of things for other relations. Pretty useful! What do you think?
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding XBRL's Role in Knowledge Representation
My mantra relating to digital financial reporting has been:
The only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax rules, domain semantics rules, and workflow/process rules.
This is not something that I made up; it is something that information technology professionals understand. I first learned about this from an HL7 video which explained this.
The technical syntax rules part I understand. Things like the XBRL International XBRL 2.1 Conformance Suite help achieve technical syntax interoperability.
The workflow/process rules part I intuitively understand, it makes sense, but I have not done much digging into this yet.
The domain semantics rules part has been confusing to me in the past, but this is becoming clearer. I never could quite figure out the relation between something like RDFS/OWL to XBRL. How do you leverage what RDFS/OWL provides because these features seem necessary in XBRL also. Certainly the lack of appropriate semantic interoperability in XBRL-based financial filings provided ample evidence of this. Some experimentation and some discussions on the Semantic XBRL LinkedIn group yielded very helpful information.
One of the first extremely helpful things that I ran across was a comparison of the capabilities of OWL and UML to represent knowledge in the form of this document: Extending the UML Language for Ontology Development. The document explains two things. First the different "world views" of people with a UML background and a semantics web type background. Second, it explained all the different terms which people use. This document, Knowledge Representation/Translation in RDF+OWL, N3, KIF, UML and the WebKB-2 languages, is a little more complicated but it also has some very useful information.
What I obtained from the Semantic XBRL discussions, the documents above, and some other things I ran across I synthesized into an additional mantra:
First-order logic can be used to express a theory which fully and categorically describe structures of a finite domain (problem domain). No first-order theory has the strength to describe an infinite domain. There are two key parts of first-order logic. First, the syntax which determines which collections of symbols that are legal expressions in first-order logic. Second, the semantics which determines the meaning behind these expressions.
Someone made the statement "systems have boundaries" which is essentially the same thing that the paragraph above says. Machines such as computers don't do "infinite" very well, they need to deal with finite things.
OWL is a global standard knowledge representation language and is based some say on description logic and other say on first-order logic. Knowledge representation can mean both:
- knowledge description constraints and
- knowledge entering constraints.
Description constraints and entering constraints (data entry constraints) seem to be two sides of the same coin.
The term knowledge base seems to be where you store representations of some set of knowledge. Knowledge management is the process of managing knowledge.
And so how does XBRL fit into all of this?
XBRL needs to be seen as a knowledge representation languagerather than simply an information exchange format. What does XBRL need in order to be a knowledge representation language? Well, it needs all the same "stuff" that OWL provides.
This document which I put together, Knowledge Representation Terms Reconciled to XBRL Semantics, reconciles the features of RDFS/OWL/SKOS and UML to XBRL. Note two things in the document. First, there are a lot of things that RDFS/OWL/SKOS and UML provides that the XBRL global standard does not currently provide. Most of these things fit into the category of expressing relations between concepts such as what class a concept belongs to, "partOf" type relations "hasPart" type relations, and so forth.
But you can also note that XBRL provides a lot of things that RDFS/OWL/SKOS and UML do not provide in terms of expressing domain semantics:
- the notion of a "fact"
- a "units" registry
- the ability to express different types of numeric relations such as "roll up" and "roll foward" and "adjustment"
- the notion of a "hypercube"
Those are just a few. Now, the things that XBRL provide are higher level than RDF/OWL/SKOS and UML. On the Semantic XBRL discussion list someone described RDF/OWL/SKOS as a lower-level language. They are very flexible and you can really do a lot with them. But, because they are such low-level they are extremely hard to make use of.
I see XBRL as a practical knowledge representation "sweet spot" for business reporting. It provides additional "layers" which are needed for business reporting. Could you recreate what XBRL offers using RDF/OWL/SKOS? Absolutely you could.
So, could you duplicate what RDF/OWL/SKOS offers using XBRL? I think so. One of the things that I have already done is express different types of whole-part relations, class-subclass, and class-equivalentClass type relations using XBRL. Here is that taxonomy schema. I used standard mechanisms offered by XBRL to articulate this information: XBRL definition relations and the ability to define custom arcroles.
Are my arcroles a global standard? No. But, if they got promoted to the XBRL International Link Role Registry (LRR) the would be.
Why is all this important? See the graphic below: (click the image for a larger view)
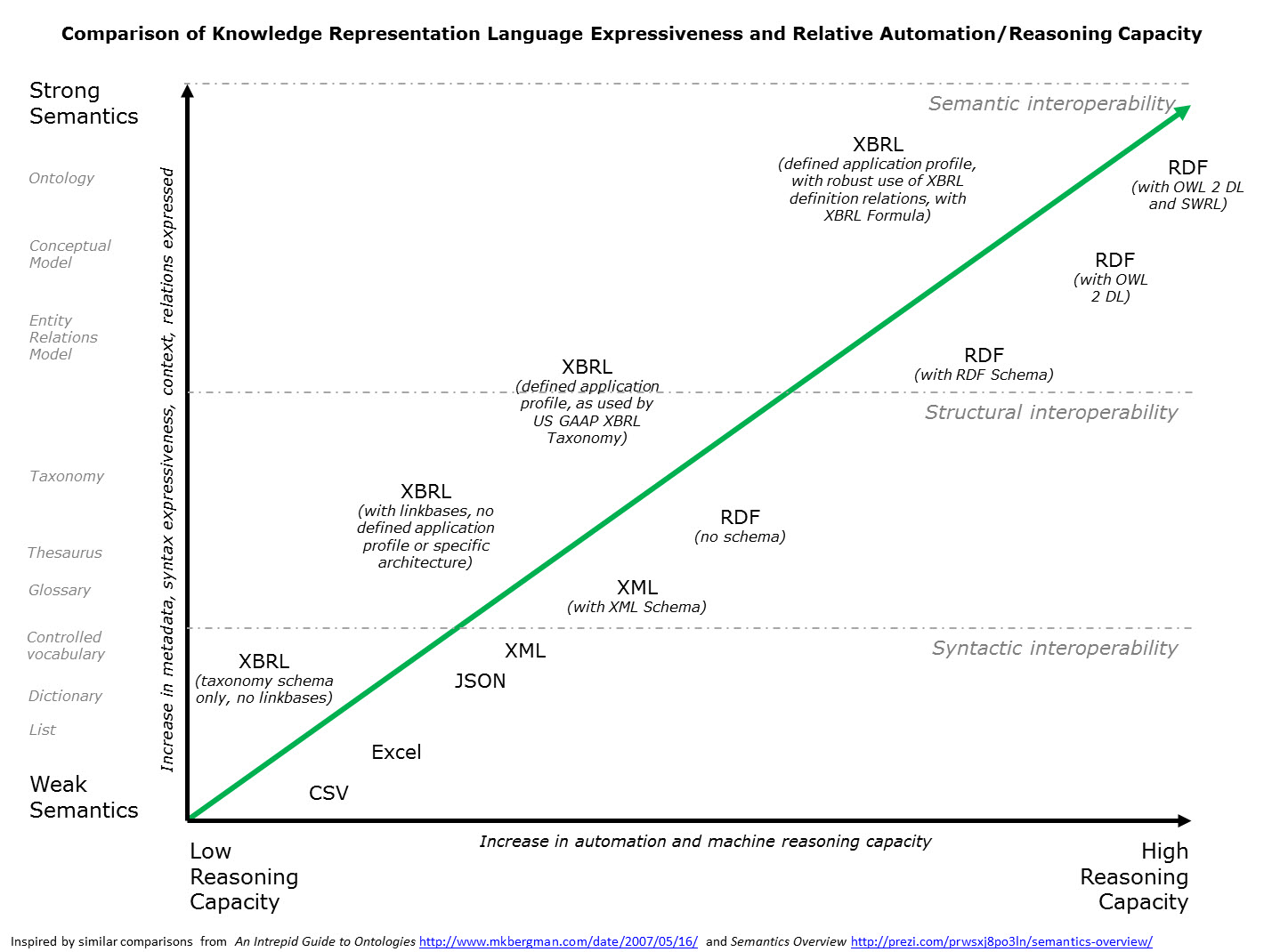 (Click image for larger view)
(Click image for larger view)
The point here is to enable a machine such as a computer to perform useful work for us humans. The stronger semantics that are expressed, the higher reasoning capacity a computer can have and therefore the more that can be automated.
Am I saying that business professionals are going to need to understand all this underlying technology? Not at all. The point is that the better this stuff is organized the easier it is for technical people to build higher-level layers that the business users interact with. The ugly technical stuff, which no business person will ever understand, will be buried in sophisticated software which makes all this useful functionality look like magic.
XML Schema-based approaches are too restrictive and inflexible. RDFS/OWL is too low-level and ultra-flexible making it useful for nearly anything, but far too complicated for business users to make use of. XBRL, with higher-level structures strikes a good balance between XML Schema and RDFS/OWL.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

