BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from February 1, 2015 - February 28, 2015
Please Help if you Can: Convert XBRL into RDF/OWL 2 DL
I have spent literally hours trying to convert an XBRL-based digital financial report into RDF/OWL 2 DL with limited success. If you know how to do this, any help would be greatly appreciated.
This will walk you through the XBRL-based report, to the XML Infoset of the semantics of the information, to what I have been able to create thus far:
- Reference Implementation: I created what I call a reference implementation of an XBRL-based digital financial report. You can see the XBRL instance which is the entry point of the report. Load that document and the supporting taxonomy will be loaded. If you want to see a human readable rendering of that report, use this evidence package provided by XBRL Cloud.
- Fact Table Infoset: You DO NOT want to convert the XBRL syntax to RDF/OWL 2 DL. What you want to convert is the meaning of the information. The Fact Table Infoset is generated from the XBRL instance. THAT is what needs to be converted to RDF/OWL 2 DL. The hard part is converting the XBRL into the XML Infoset format.
- Model Structure Infoset: The Model Structure Infoset is likewise pre-converted from XBRL to an Infoset which represents the XBRL taxonomy structure. There are some pieces missing for a complete conversion, but this provides enough to create a useful conversion.
- OWL 2 DL Ontology: This is where I have gotten so far in terms of creating an ontology which is used to express the relations in the report.
- RDF for Fact Table: This is the RDF for the Fact Table Infoset information. Basically, this RDF and the Fact Table Infoset should be equivalent in terms of meaning.
- RDF for Model Structure: This is in the worst shape. This is the RDF for the Model Structure Infoset. I am trying something that I saw, it is probably not a good idea; and it may not even be allowed. I am trying to nest the rdf:Descriptions. I have seen that done by others, but again; not sure if this is legal or a good idea. Anyway, this is in pretty bad shape.
- Business rules: (EXTRA CREDIT)If you are REALLY agressive and want extra credit points; these are business rules for the XBRL instance which likewise need to be converted into RDF or OWL or SWRL or something. I am not even sure this is possible. Again, this is EXTRA CREDIT. The Fact Table Infoset is the first priority, then the Model Structure Infoset.
The goal is to convert an entire XBRL-based digital financial report into an RDF + OWL 2 DL + SAFE SWRL-based digital financial report. The reason is to see the pros and cons of each format.
What I am seeing thus far is that RDF is brutal to work with. There are a zillion different formats. There is no nesting within the RDF which (a) makes the information incredibly flexible (which is a good thing) but it makes the RDF harder to read in software if you are not very good at writing software (like me).
Something that I have learned already in this process is that many software developers don't really get RDF. This document, Why RDF is More than XML, walks you through some issues. Basically, XML tools don't work very well with RDF because RDF is looks flat. What is really going on is that RDF is flexible and makes querying easier. While I would agree that there are situations when you work with XML and you need the hierarchy if you are a human working with the XML. But, computers can work with RDF just fine. There might be somewhat of a compromise, a simplified syntax for RDF or more of a shorthand.
The bottom line on all of this is that syntax does not matter. One should be able to convert from XBRL to RDF + OWL 2 DL. What I am trying to figure out is what you get from off-the-shelf OWL validators or reasoners.
My intuition tells me that neither off-the-shelf XBRL tools nor off-the-shelf OWL tools will serve the needs of business professionals appropriately, particularly accounting professionals. Hybrid combination tools and digital financial reporting specific tools are what is necessary.
 Charlie
in Becoming an XBRL Master Craftsman, Demonstrations of Using XBRL
|
Charlie
in Becoming an XBRL Master Craftsman, Demonstrations of Using XBRL
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
US GAAP XBRL Taxonomy Missing Approximately 50% of Level 3 Text Blocks
The US GAAP XBRL Taxonomy provides 454 Level 3 Text Blocks. In the taxonomy these are called [Table Text Block]s. These Text Blocks are used to provide human readable HTML for a specific disclosure. You can find a list of these Level 3 Text Blocks in the Comprehensive Text Block List in the US GAAP XBRL Taxonomy.
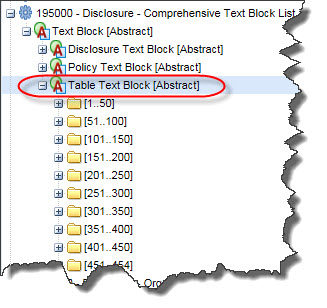 (Click on image to go to US GAAP XBRL Taxonomy)
(Click on image to go to US GAAP XBRL Taxonomy)
The US GAAP XBRL Taxonomy and SEC EFM use inconsistent terminology, so it is worth making sure we are on the same page here. What the US GAAP XBRL Taxonomy calls a "Disclosure Text Block", the SEC calls a "Level 1 Text Block" or a "Footnote as a Text Block". Level 2 Text Blocks are policies. Level 3 Text Blocks provide human readable HTML at the level of an individual disclosure. And finally, Level 4 Detail provides individual detailed facts for an individual disclosure. All this is explained in the SEC Edgar Filer Manual (EFM) section 6.7.12.
And so, the US GAAP XBRL Taxonomy says that there are 454 possible disclosures because they provide 454 Level 3 Text blocks ([Table Text Block]s).
Well, I went through the US GAAP XBRL Taxonomy and tried to identify each individual disclosure and I came up with about 957 total disclosures. That number includes a handful of statements, 129 Level 1 Text Blocks (Note Level), a handful of Level 2 Text Blocks (Policy Level), and a few odds-and-ends which really are not individual disclosures. As such, I will adjust the total number of true disclosures down to this approximate number: 807.
I will also point out that my list includes only disclosures for commercial and industrial companies. I am not including disclosures for banks, insurance companies, broker-dealers, and so on.
And so the US GAAP XBRL Taxonomy indicates that there are 454 disclosures, I can point out about 807. It is my guess that my list of 807 disclosures is off by between 50% and 100%. That is just an educated guess, hard to come up with an exact number without going through every public company filing and trying to identify every disclosure (which I am working on now). But my guess is based on work trying to determine all the different types of primary financial statements (what I call report frames, this document helps you understand report frames).
There is a relationship between the Level 3 Text Block and Level 4 Detail disclosures. Look at three examples which I created for fairly common disclosures:
- Inventory, Net: Roll up of the components of inventory.
- Property, plant and equipment components: Roll up of the components of PPE.
- Long-term debt maturities: Roll up of the maturities schedule of long-term debt.
Looking at rather uncommon disclosures also points out that text blocks are missing from the US GAAP XBRL Taxonomy. Here is an example:
- Capitalized Computer Software Roll Forward: Roll forward of capitalized computer software.
Looking at both the Level 3 Text Blocks and the Level 4 Detail for disclosures helps you understand if pieces are missing from the US GAAP XBRL Taxonomy.
Charlie
in Becoming an XBRL Master Craftsman, Creating Investor Friendly SEC XBRL Filings
|
Post a Comment
| Email
| Print
State-of-the-Art Use of XBRL Definition Relations to Express Business Rules
I will hold this out as a state-of-the-art use of XBRL definition relations to articulate a rich set of business rules for a taxonomy.
If you don't agree, please contact me and explain specifically why you might disagree. I am not saying that this is perfect, but it seems to be very useful to me. Keep in mind that this is a working prototype and still under construction, so the actual business rules might not be 100% accurate at the present time.
What this working prototype does is articulate machine-readable business rules for US GAAP financial disclosures. I will walk you through one disclosure and the big picture. From there you can look at other disclosures using the same process that I show.
To fully appreciate these machine-readable files, you need an XBRL Taxonomy viewer or some other way of reading these XBRL files.
One disclosure:
- Disclosure: Roll up of the components of inventory, Inventory, Net, Current [Roll Up]. If you look closely at the disclosure, you notice a list of multiple examples of the disclosure. Here is another version of that list. The information is the same, there is just more metadata on the alternative list.
- Disclosure's business rules: If you look at the disclosure, you notice some patterns. You notice that many use the Level 3 Text block us-gaap:ScheduleOfInventoryCurrentTableTextBlock. You notice that each of the individual disclosures provided is a [Roll Up]. You notice that the total of the roll up is generally, if not always, the concept us-gaap:InventoryNet. That information is basically business rules related to this specific disclosure. I articulated those rules in machine-readable form using XBRL definition relations. This is the machine-readable XBRL definition linkbase which contains the rules for that disclosure.
- Arcroles for articulating disclosure's business rules: To specify the relations in the XBRL Definition Linkbase, I created arcroles. I have two different files for no particular reason really, I just created the rules at different times. This is the first. This is the second.
That is really it. There is a lot of additional information in the human readable information, you can ignore that or dig into that as well.
Multiple Disclosures:
- Topics: First off, there are a lot of disclosures, I have about 1000. To better work with the disclosures, I wanted to organize them by topic. To do that I first defined the Topics in an XBRL taxonomy schema. I then organized the topics into a hierarchy of relations using an XBRL definition linkbase.
- Disclosures: Next, I defined a list of disclosures in the same way. First, defining the disclosures in a taxonomy schema and then just a flat list of of the disclosures.
- Organize disclosures: Because there are lots of disclosures, I wanted to organize the disclosures. Here is one example of an organization of disclosures by information model pattern.
- Disclosures organized by Topic: Combining the Topics and Disclosures provides a good organization of the disclosures. This is the XBRL definition linkbase which contains this information.
- Business rules organized by topic and by disclosure: This XBRL definition linkbase provides the business rules for every disclosure, organized by disclosure, which is then further organized by topic. See the graphic below to get the full grasp of what this set of XBRL definition linkbase relations provides.
Keep in mind that the business rules and disclosures are a working prototype. A lot works and is correct, other things are still a work-in-progress. But, this should give you a good idea of what you can do with XBRL definition relations.
This RSS feed provides a list to each of the sets of business rules, independent of the topics and disclosures. If you want a HUMAN READABLE list of disclosures, you can find that here.
If you dont have access to an XBRL Taxonomy Viewer, this is what the XBRL definition relations in the last bullet looks like:
 (Click Image for Larger View)
(Click Image for Larger View)
So in summary, XBRL definition relations are a powerful tool which can be used to articulate machine-readable business rules using a global standard format. I hope this helps you get an idea of how easy and useful this approach is.
Charlie
in Becoming an XBRL Master Craftsman, Demonstrations of Using XBRL
|
Post a Comment
| Email
| Print
Working Prototype of Disclosure Business Rules Using XBRL
How do you eat an elephant? A piece at a time. The US GAAP XBRL Taxonomy is not one big thing. It is made up of lots and lots of little things. Lots of disclosures.
If you are a human, you can read these disclosures here.
If you are a machine, you can read these disclosures here. That is an XBRL taxonomy schema which contains a list of disclosures from the 2015 US GAAP XBRL Taxonomy.
I wanted to test certain aspects of each disclosure such as:
- What is the information model of the disclosure?
- What is the equivalent Level 3 Text Block for a Level 4 detailed disclosure?
- What [Axis] are required to be used on a disclosure?
- What concept is required for a Level 4 detailed disclosure?
So, I created a set of arcroles which I could use to express relations as an XBRL taxonomy schema.
I then used those arcroles to express information from my bulleted list above for each disclosure in the form of an XBRL definition linkbase. Here is the individual XBRL definition linkbases for a handful of disclosures:
- Balance sheet (human readable)
- Environmental exit costs (human readable)
- Acquired indefinite-lived intangable assets, by major class (human readable)
That is just a few examples. Here is an RSS feed of the entire set of disclosures.
I combined each of the individual XBRL definition linkbases for individual disclosures to make this complete set of all the XBRL definition linkbases in this XBRL taxonomy schema. Basically, that is all the individual business rules combined. (This takes a few minutes to load into an XBRL taxonomy tool because it has to download each of the approximately 953 files. I am getting a few minor errors, but that should load into any XBRL taxonomy tool.)
Why bother with this? See here. A software vendor has created the ability to validate all of those rules. The software reads the metadata and checks to see if a certain disclosure exists, if say the information model is a "roll up" it looks for the XBRL calculation relations which should exist. If it is a Level 4 detailed disclosure, you would expect the Level 3 Text Block to also exist. If the specific concept or concepts which one would expect to find within a specific Level 4 detailed disclosure are present. If the expected [Axis] found on the disclosure.
Think disclosure checklist.
Charlie
in Demonstrations of Using XBRL
|
Post a Comment
| Email
| Print
Understanding Expressive Power and Your Digital Future
You think XBRL is complicated? It is not XBRL that is complicated, it is the real world which is complicated.
Since the time of Aristotle, who built the first ontology, humans have been coming up with ways to describe the world. It was not information technology professionals who created the notion of an ontology, it was philosophers. And there was no need for computers to read these descriptions of the real world, computers did not even exist in the time of Aristotle, 300 BC.
Today computers do exist and it is important for ontologies to be machine-readable. Arguably, the state-of-the-art for machine-readable representations of knowledge is the global standard W3C: RDF/OWL 2 DL + SAFE SWRL.
If you go to the W3C page for ontology, the first thing you might note is that the title of the page says "Vocabularies". I guess that the W3C feels the same as XBRL International who considered the term ontology but went with taxonomy because it seemed less scary.
This is the definition of vocabularies provided by the W3C:
Vocabularies define the concepts and relationships (also referred to as “terms”) used to describe and represent an area of concern. Vocabularies are used to classify the terms that can be used in a particular application, characterize possible relationships, and define possible constraints on using those terms.
(I don't want to go down the path of explaining all of these technologies. See the sections below "Semantic Web Technologies" and "Semantic Web Metadata" to take a closer look at these technologies.)
Ask yourself a question: Why is the W3C going through the trouble of creating all of this stuff?
Machines, if made to understand what you want, can do work for humans. To make a machine understand you have to express things so that machines can first simply read what you are expressing, then once read; additional work needs to be done for them to understand what you are expressing. All the W3C semantic web technology stuff is an effort to express as much as possible to get machines to do as much as possible.
The Semantic Web Technologies the W3C are creating have a high-level of expressive power. That means you can get machines to do a lot of stuff for you.
By contrast, take the CSV (Comma Separated Values) information format. It is not very expressive and therefore you cannot really do much with it. You can do some things, like transfer tables of information between Excel spreadsheets, but that is about it.
Financial reporting is complicated. As such, XBRL had to be closer to what the W3C is creating in terms of semantic web technologies than to the rather impotent CSV.
XBRL allows you to express terms or concepts, relations between terms/concepts, and constraints on using terms/concepts. When I say "XBRL", what I mean is XBRL 2.1, XBRL Dimensions, XBRL Formula, and a set of arcroles used to express relations which I have been trying to get included in the XBRL International Link Role Registry. That is what I mean when I use the term "XBRL".
What I don't quite understand is which has better expressive power:
- XBRL or
- RDF/OWL 2 DL + SAFE SWRL.
I don't think this is an either-or type question or one against the other, RDF/OWL 2 DL + SAFE SWRL --or-- XBRL. What I want to understand is the gap in the expressive power between the two.
Why understand the gap? Because if you understand something's limitations, then you understand something's true power. This is what I do know:
- RDF/OWL 2 DL + SAFE SWRL does not do math. Mathematics was consciously left out of OWL 2 DL because parts of mathematics is not decidable.
- XBRL has XBRL Formula; so XBRL does do math. You can also limit how you use XBRL Formula to keep XBRL decidable.
- RDF/OWL 2 DL + SAFE SWRL is more flexible than XBRL. If you want to express anything and everything, it does not get much better than RDF/OWL 2 DL + SAFE SWRL. However, the trade off is that RDF/OWL 2 DL + SAFE SWRL is harder to use because of that flexibility.
- XBRL is flexible, but not remotely as flexible as RDF/OWL 2 DL + SAFE SWRL. But, if you want to represent a business report or financial report, XBRL is specifically tuned for that task. Therefore, XBRL can be easier to use for that specific task because it is limited to that specific task.
- RDF/OWL 2 DL + SAFE SWRL could be used to express dimensional information, but you have to add additional functionality to make that happen. How do I know? The W3C created RDF Data Cube vocabulary (see below) to enable that functionality.
But that information above does not tell the the specific "gap" between RDF/OWL 2 DL + SAFE SWRL and XBRL. I want to figure that out. It provides a lot of good information, but I cannot point to specific limitations quite yet.
What it looks like to me is that XBRL has a potential advantage, a "sweet spot". That sweet spot is business reporting including financial reporting. You could recreate 100% of what XBRL offers in RDF/OWL 2 DL + SAFE SWRL perhaps. Or if you cannot, what you cannot express is "the gap" that I am looking for. THAT is the answer to my question.
What could be really, really interesting is the controlled natural language provided by Fluent. I don't believe that is itself a global standard. However, it can be converted into RDF/OWL 2 DL + SAFE SWRL which is a global standard. What if Fluent could also output XBRL syntax? In my view, that would be the perfect world. That would be the smoking gun which shows that syntax does not matter. It would also clearly delineate any expressive power differences between RDF/OWL 2 DL + SAFE SWRL and XBRL.
Business professionals and accounting professionals: how much of what I am talking about do you understand? While most business and accounting professionals should not even care about this stuff; those trying to get XBRL to work correctly to serve business reporting and financial reporting should. This information will tell you if XBRL is working the way you need XBRL to work.
What do you think the chances are that digital financial reporting will succeed in replacing current financial reporting practices? Another term for digital financial reporting is disclosure management. (see the end of this blog post for more information on disclosure management)
While it is hard to understand exactly how all this digital business reporting and digital financial reporting will sort out, what is clear is that change is not only inevitable, it is imminent. Being on the wrong side of this equation will have consequences.
Semantic Web Technologies:
The W3C OWL 2 specification is a formal language for building formal vocabularies for specific problem domains so that information can be shared by a community of users. OWL 2 specifies the classes of things, the relations between classes of things, the properties of classes and relations, and can be used to express individuals which represent instances of things and relations.
The W3C RDF (Resource Description Framework) is a framework for describing information. RDF is about as flexible as you can get, it can be used to describe pretty much anything which is describable. OWL 2 is used to constrain information to make sure that what is described is consistent with some OWL 2 formal vocabulary of some problem domain.
The W3C SWRL (Semantic Web Rules Language, a proposal to the W3C) is a language which expresses rules which OWL 2 does not have the power to express. This gets a little complicated, this tutorial helps you understand the details; but basically OWL is limited and SWRL overcomes those limitations.
This is where things start to get really messy. OWL 2 and SWRL have limits. RuleML, while not a W3C standard, is a de facto standard for expressing rules. A business rule is basically a business requirement of some sort which can be implemented within software. W3C RIF (Rules Interchange Format) is a standard syntax for exchanging rules from one system to another system. SPIN (SPARQL Interface Notation) is a very low-level (i.e. SPARQL queries) approach to creating rules. It seems that you can create almost any rule using SPIN. However, SPIN is pretty low-level and not something that a business user would directly interact with.
Semantic Web Metadata:
Here are some global standard sets of metadata created by the W3C mainly:
- W3C organizations ontology which is used to define organizational structures.
- W3C time ontology which is used to define time related structures.
- W3C RDF Data Cube vocabulary which is used to publish multidimensional data. They also say that it can be used to represent spreadsheets and OLAP cubes.
- W3C SKOS (Simple Knowledge Organization System) which is a common language for linking and sharing knowledge systems.
- W3C FOAF (Friend of a Friend) which is a common language for linking people and information.
- Dublin Core which is best describe as metadata which turns the entire internet into a "library card catalog".

