BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from October 2, 2011 - October 8, 2011
Creation of Financial Statement is a Collaboration
The creation of an external financial statement is a collaboration between multiple parties. This collaboration is both inter- and intra-organization. The graphic below shows many of the parties which collaborate to create an external financial statement.
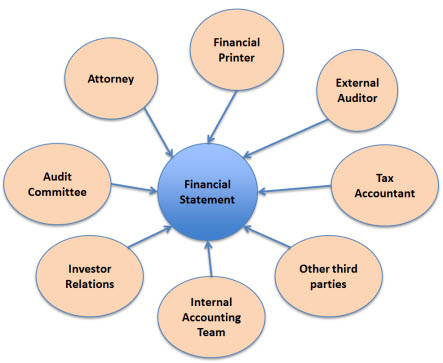
Before the internet existed, many of the means of collaboration we take for granted today were either simply impossible or cost prohibitive for all but the largest organizations. As such, collaboration could be considered "efficient" by pre-internet standards. However, by today's standards with the capabilities enabled because of the internet, those same efficient looking processes seem quite inefficient.
Before the internet collaboration with external parties took the form of the postal service, the fax, couriers, etc. Even collaboration with internal parties required these types of resources. Today, we all know that this is different and that anything which is in a digital form or can be put into a digital form can be anywhere on the planet in milliseconds.
But, if you look at the process of creating an external financial statement, how efficient is it? This how Ventana Research describes the process in their white paper Selecting the Right XBRL Solution (2008, page 5):
All larger companies keep the text and numbers that go into their external reports in multiple enterprise systems and a large number of spreadsheets (usually Microsoft Excel) and text documents created with word processing software (such as Microsoft Word) scattered around on individual hard drives and multiple network directories. People cobble together filings from a large number of text files and spreadsheets in a highly manual, time-consuming and error-prone process.
Gartner tells a similar story in their research report XBRL Will Enhance Corporate Disclosure and Corporate Performance Management (April 23, 2008):
For example, it is estimated that the average Fortune 1000 company used more than 800 spreadsheets to prepare its financial statements for regulatory reporting.
And that describes the internal collaborative process. One would anticipate that the method of collaborating with external participants in this process is similar or likely even worse.
Is there a better way?
The primary objective of XBRL is to enable one business system to exchange information with another business system without the involvement of the IT department. The IT department can exchange information between systems with one hand tied behind their back. But when you get the IT department involved, costs go up. Plus, without standards the costs go up because all you can build is point solutions which allows interoperability between two systems. Standards, like XBRL, offer general interoperability.
Are we there yet with XBRL? Not quite, but getting closer. Today business system interoperability is easier because of standards such as XBRL. But, you still need that IT department to help out. Proof of this is the high number of SEC XBRL filers who out source this task.
But in the future there will be better business system interoperability, achieving the interoperability will be easier, and not only will the internal collaboration be easier; but collaboration with external parties will likewise be easier. Costs will be reduced. Applying a "bolt on" process, even if that bolt on process is out sourced, simply adds more work.
In a future post I will like at some of the specific types of collaborations involved in external financial reporting and how XBRL and other technologies can enable significant improvements in not only efficiency but also in effectiveness.
So stay tuned!
 Charlie
in Creating Investor Friendly SEC XBRL Filings
|
Charlie
in Creating Investor Friendly SEC XBRL Filings
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Mashup of Taxonomy Relations and SEC Financial Filing Rendering
Inspired by what I had mentioned about linking directly to a component of an SEC XBRL filing (as opposed to having to get the entire filing), a statement made to me by a CPA about how it would be nice if I connected two things together, and some information provided to me by the SEC in response to a question I posed to ask-oid@sec.gov; I created this prototype mashup.
The mashup is similar to several things I already had so it literally only took me two hours to create. The first puzzle piece was this list of the taxonomiesfor the top 100 SEC XBRL filers by total assets. That is useful, but it leaves a lot to be desired in terms of what I was trying to achieve which is allow a CPA to quickly browse through SEC XBRL an see how others expressed their financial information in XBRL.
The second thing I did was this set of what I call exemplars which allows you to look at information for the same 100 SEC filers as above, but this time, it breaks the pieces of the filings into components; thus letting you focus on one specific component and browse through that by filer. For example, you could browse through the document information or the balance sheet or the income statement.
The obvious thing which is missing from that exemplar viewer is the actual rendering of the financial report. If you had that, plus the taxonomy you can really look at SEC XBRL filings in a very helpful way. So when someone showed me that Rivet CrossView Preview, what I saw was this. That was good, it makes it easier to browse SEC filings faster than you can at the SEC web site; but my first question was could I go directly to a component of one filing. Someone kindly pointed out that I could do that, and then this was the view I was able to have, linking directly to the Exxon income statement.
http://crossview.rivetsoftware.com/financial/Default.aspx?cik=0000034088&accession=0001193125-11-209772&rfile=R2.htm&query=EXXON+MOBIL+CORP
So my next question was: Could I generate the URL from my software, allowing me to autogenerate the links to this information.
Well, I know everything in that URL (the CIK, the accession number, the company name) EXCEPT for that funky "R2.htm". I new what it was, if you go to this link you can see these pages. But how do you figure out those page numbers?
Well, I looked at the pages and noticed that the pages correlated to the networks in a filing. So, I tried that and sure enough I was pretty successful predicting which network was in which of those "R" whatever HTML pages.
And that is how I created that mashup of my taxonomy information for one network and the corresponding rendering, complements of the SEC! Pretty slick.
But, what I noticed is that (a) I cannot be sure this is reliable, in fact it is not reliable. I have some glitch in my algorithm. If you go to filing #9 (AMERIPRISE FINANCIAL INC) you can see that I have the wrong file for the network I wanted to grab. My metadata is fine, I point to the correct balance sheet network (i.e. my taxonomy relations are fine). So, for this reason this approach may not be reliable. Also, I noticed some filings which have like 60 or so networks and there are only R files which go up to R42.htm. Not sure what the deal is with that.
Also, if you use those files, you will notice that the handy little pop up with the concept name, references, and other detailed information does not work.
I do believe that you can see how useful this functionality is. This will help me create this Accounting Trends and Techniquestype functionally for SEC XBRL financial filings. Do you think something like that would be useful with both the taxonomy relations, the viewer rendering, and all this information usableinto an application which generates XBRL? Let me know.
Charlie
in Demonstrations of Using XBRL
|
Post a Comment
| Email
| Print
Link Directly to Component of an SEC XBRL Filing
Someone pointed out an incredibly useful feature of a tool. If you click on this link, it will take you directly to the income statement of the June 30, 2011 10-Q of Exxon.
That is similar to a feature in another tool which will take you directly to a concept within a taxonomy. For example, if you click on this link it takes to you to the concept "Cash and Cash Equivalents, Period Increase (Decrease)"in the US GAAP Taxonomy.
I have always tried to build my web pages in that manner. For example, if you click on this link it will take you to a rendering of the Exxon taxonomy.
The really interesting thing is the ability to string all of this information together, say in some sort of mashup, which provides new information.
What neither of those links really does is make it easy to generate from a computer software application the URLs which you need. The reason you would want to do this is that you can avoid having to manually create links.
Charlie
in Demonstrations of Using XBRL
|
Post a Comment
| Email
| Print
Semantic, Structured, Model-based Authoring Enabled by XBRL
Most people look at XBRL as simply a means of exchanging information. For example, in the US public companies exchange information with the SEC using the XBRL format. Others around the world are doing the same. Most of these companies use XBRL because they have to.
But XBRL will enable more than an ability to exchange information. In fact, the exchange of information is really only a by product of the structured nature of XBRL. As I point out in my book XBRL for Dummies (page 12), XBRL is:
A means of modeling the meaning of business information in a form comprehendible by computer applications.
It is the structured nature of the informationexpressed in XBRL which is the key. This enables the effective information exchange between business systems. But the structuring of the information causes something else to be structured: metadata. Looking closely at the US GAAP Taxonomy will reveal that the metadata of financial reporting is articulated in a taxonomy which can be used by a computer software application. That metadata, along with other metadata, will enable software developers to create interesting new software.
As I pointed out in a previous blog post, Microsoft Word is used to create 85% of all financial statements yet Word knows nothing about financial reporting.
Looking at three diagrams will help you understand why this structured metadata and the structured nature of XBRL will enable this interesting new software.
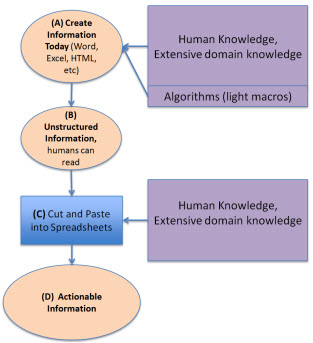
Software today
When a financial statement is created today using Microsoft Word, a highly skilled domain expert has to structure that information into the form of a financial statement within Word. That highly skilled person has extensive domain knowledge. They might use some light weight computer algorithms (macros) to assist in the process, but it is mostly a highly skilled domain expert, perhaps with someone else doing the actual typing of information, which hammers out the financial statement.
Then, because the information in the financial statement is unstructured, to reuse the information another domain expert with extensive domain knowledge "cuts and pastes" that financial information into a spreadsheet analysis model or perhaps some other software.
This diagram shows this process: (A) create information, (B) the unstructured information is read by humans or (C) cut and pasted into spreadsheet models, which (D) leads to actionable information, or information which "supports action", information you can do something with.
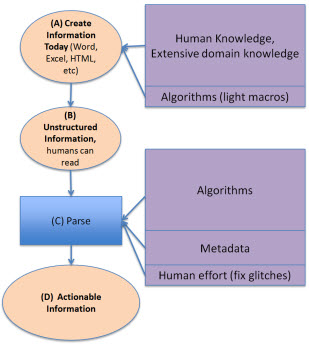
Rather than "cutting and pasting" the information you could do what Edgar Online has been doing for years which is creating parsing routines which minimize the need for "cut and paste" and use software algorithms to parse the information. Edgar Online parses SEC HTML and SGML filings and then makes the information available to those that use the information, for example analysts.
A key point to realize here is that these parsing routines are driven by domain metadata. It is those computer understandable algorithms and metadata which allows a computer to recognize that, say, a piece of information is a specific balance sheet line item. Rather than the human "cut and paste" by a highly skilled domain expert, it is a computer algorithm and metadata created by highly skilled domain experts and software developers which puts the information where you want it. The key thing to not here is how the domain knowledge moved around a bit.
Semantic, Structured, Model-based Authoring
What if we moved this metadata and some of these algorithms to the creation end of the financial statement creation, rather than the reuse end? That is what semantic, structured, model-based authoring is all about. The unstructured form and the need to parse the unstructured form into some more useful structured form is totally eliminated because the information is structured in the first place.
How does this happen? Magic? Voodoo? Artificial intelligence? Nope, it happens because of the metadata. Computers may not be able to do everything for the user who wants to create a financial statement, but there is an incredible amount that a computer can, and will, do. Human effort is reduced by the algorithms and metadata, costs are saved. Having a highly skilled domain expert doing cut and paste operations is a waste of their skills. Using a 10 key to verify that the numbers in the financial statement add up is not only a waste of skill, but humans get tired and make mistakes. Computers don't get tired. These repetitive, simple, time consuming tasks can be taken over by computer software leaving the highly skilled domain experts to focus on things like judgment; things a computer will never have.
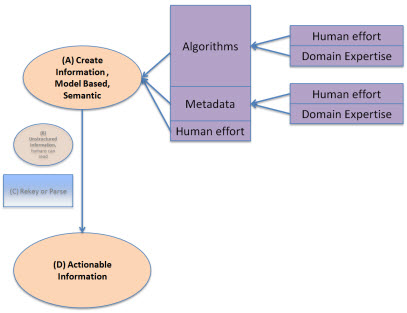
Metadata
What is the only thing better than metadata? More metadata. Metadata can take various forms such as business rules, for example:
- Assertions: For example asserting that the balance sheet balances or Assets = Liabilities + Equity.
- Computations: For example, calculating things, such as Total Property, Plant and Equipment = Land + Buildings + Fixtures + IT Equipment + Other Property, Plant, and Equipment.
- Process-oriented rules: For example, the disclosure checklist commonly used to create a financial statement which might have a rule, "If Property, Plant, and Equipment exists, then a Property, Plant and Equipment policies and disclosures must exist."
- Regulations: Another type of rule is a regulation which must be complied with, such as "The following is the set of ten things that must be reported if you have Property, Plant and Equipment on your balance sheet: deprecation method by class, useful life by class, amount under capital leases by class . . ." and so on. Many people refer to these as reportability rules.
- Instructions or documentation: Rules can document relations or provide instructions, such as "Cash flow types must be either operating, financing, or investing.
Another type of metadata is relations. For example, how one concept is related to another concept.
The US GAAP Taxonomy itself is metadata, it defines concepts and relations between concepts used in financial reporting.
Other metadata is the conceptual framework of US GAAP itself. Not all this metadata will be, or even has to be, expressed using XBRL. It only needs to be understandable to a computer. Who will create this metadata? Humans who have domain knowledge.
It is this metadata which articulates the semantics which today exist in books and other forms not understandable by computers. It is the semantics which will drive the software. It is the model-based nature, which is really more metadata, which enables this new approach to authoring.
The world is already going down this path. Many software companies started down this path long before XBRL even existed. Many tools already exist for specialized tasks, but they are very expensive.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Video Overview of XBRL Abstract Model Created by XBRL International
XBRL International held a webinar which explained the UML model they are creating for XBRL, referred to as the XBRL Abstract Model. You can watch this 1 hour 34 minute video on YouTube here.
For those serious about understanding XBRL, this video is worth investing in. As stated in the webinar, XBRL International is trying to create two models:
- Primary model: Models semantics.
- Secondary model: Maps modeled semantics to the XBRL technical syntax.
One of the most useful aspects of this video are the very, very good questions which were asked. The webinar stated that a public working draft of this model would perhaps be available in October.
The semantic model which I have created can be found here. My model, which would fit into the model I saw in the webinar, is more focused on financial reporting and tends to be at a higher level than the model created by XBRL International.
Charlie
in Modeling Business Information Using XBRL
|
Post a Comment
| Email
| Print

