Best Processing Approach for Fundamental Accounting Concepts Metadata?
I now have an updated set of fundamental accounting concepts metadata to pure XBRL. One software vendor implemented that metadata (more on that later) to create some incredibly useful queries of the XBRL-based information from public company financial reports to the SEC. Here are three examples of those queries you will want to be sure to check out on the page above:
Analysis of interest-based revenues:
 (Click image to navigate to web page)
(Click image to navigate to web page)
Analysis of insurance-based revenues:
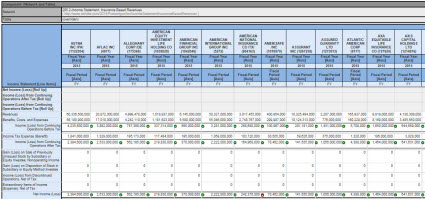 (Click image to navigate to web page)
(Click image to navigate to web page)
Comparison of entity across periods:
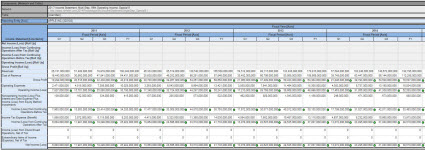 (Click image to navigate to web page)
(Click image to navigate to web page)
The query results you see are screen shots of query results. The actual queries are a substantial improvement over other query examples that I have provided. First, it is a full implementation of the fundamental accounting concept relations. Second, the implementation is pure XBRL and what I have been trying to get to for some time.
While the fundamental accounting concepts metadata representation approach is very good in my view and the queries using that metadata are impressive and useful; the real question that I am trying to answer is what is the best way to process this XBRL-based machine-readable metadata.
I now have three distinct sets of relations that I want/need to process:
- Fundamental accounting concept relations: These are US GAAP specific financial accounting relations. These same types of relations exist for IFRS financial reporting.
- Disclosure mechanical relations: These are general mechanical-type relations that exist for all financial disclosures with some SEC-specific stuff mixed in that probably should be separated out. I am pretty sure this can be generalized. These sorts of relations are used to identify a disclosure and explain the mechanics of a disclosure. For example, these rules are things like what concept is used to represent the total of the disclosure, what type of concept arrangement pattern is the disclosure (roll up, roll forward, etc), what is the matching text block for the detailed disclosure, and so forth. General, mechanical stuff.
- Disclosure accounting relations: The most valuable stuff is the accounting knowledge related to disclosures and that is this category. Information such as "IF you have disclosure A, THEN you also need disclosure B". Or, "IF the line item A exists in the balance shet, THEN policy B" must be provided. Basically, these are machine-readable rules that you would find in what accountants call a disclosure checklist.
If you don't understand what a disclosure checklist is, read Digitizing Disclosures Part 1, Part 2, and Part 3. And if you really want to understand the remaining part of this discussion and have not read it yet, I would very strongly recommend that you read the Digital Financial Reporting Manifesto because it pulls together a lot of the moving pieces to the puzzle.
And finally, keep in mind that I have represented the financial reporting ontology which is additional metadata in a pure XBRL format also.
And so this is the $64,000 question that I am trying to find an answer to:
"What is the best way to process all of this XBRL-based metadata?"
This is where I have more questions than answers. I considered this in a blog post where I contemplated the difference between a semantic reasoner, an inference engine, and so forth. And then there was this blog post where I considered the difference between forward chaining and backward chaining. And then you have the consideration of decidability and other logical catastrophes that need to be avoided at all cost because they completely break systems.
And so I show above WHAT I want to process. I point out that it is specifically NOT THE CASE that "anyone can say anything about anything" for what I am trying to process. That mantra of the semantic web is a wonderful objective and a good goal; but it is NOT the objective or requirement here.
And so, this is what I speculate based on the evidence that I see:
- It is far easier to make an XBRL formula processor (which already supports dimensions and mathematical computations well) support the additional relational processing that you need than it is to modify an RDF reasoner or other semantic reasoner/inference engine to support dimensions and mathematics and to constrain that reasoner so that you don't get logical catastrophes.
- RDF is too low-level for business professionals to deal with; business professionals will never be able to write rules in RDF/OWL. The fact-of-the-matter is that the average business person will not even be able to write rules in XBRL. That is why an abstraction layer and other techniques need to be used to move the complexity away from the business user. (All this is explained in the document Understanding Blocks, Slots, Templates, and Exemplars.)
- The XBRL Formula specification does not have a global standard chaining model. That does not mean that you cannot create chaining within an XBRL Formula processor; all the lack of a standard means is that the chaining that you come up with will not be global standard because there IS NO GLOBAL STANDARD for chaining.
- As I understand it, XBRL Formula is fundamentally based on PROLOG and PROLOG supports backward chaining. So, I think that the internals of an XBRL Formula processor actually do chaining when it does it's work; but that chaining is not exposed to the user of the XBRL Formula processor. DATALOG is a subset of PROLOG. Both PROLOG and DATALOG are safe, but DATALOG is the safest as I understand it.
- I do know that forward chaining is easier for most people to get their heads around, but it does have limitations. Backward chaining is very powerful and probably needed. My conclusion: have both backward and forward chaining features in an XBRL Formula processor. I think that might be possible, but it might not be practical.
- I will not even call what is needed an XBRL Formula processor, although it will only be processing XBRL. I will call it a "business report processor" and/or a "financial report processor". A financial report is a class of business report.
- There are some things that change when you work with a financial report as opposed to a business report. A financial report has rules like "IF this disclosure exists, THEN that disclosure must also exist. But it might be possible to generalize that sort of rule so that it works for both business reporting and financial reporting.
- I think the only thing that changes when you move from "business report" to "financial report" is metadata. And therefore, it could be the case that you don't need a financial report processor at all. I don't know the answer to that either.
- Reinventing the wheel is a really bad idea. If something already exists one should leverage that, unless there is some specific reason that you cannot.
- An OWL2 DL semantic reasoner (here is a good list; Apache JENA is a general purpose rules engine; not sure how that differes from LINQ) could do the trick, but XBRL syntax would have to be converted to RDF/OWL, processing for a dimensional model would have to be created/standardized, processing for mathematics would have to be created/standardized. This would likely offer the maximum power. I am confident that the complexity could be hidden from business professionals. Ultimately, someone will likely take this approach.
- What people think an XBRL Formula processor is and what it really could be can be changed. XBRL Formula processors today tend to have knowledge of XBRL instances, they reference an XBRL taxonomy but they really don't understand an XBRL taxonomy. What I mean is, most (if any) XBRL Formula processors don't consider the "general-special" or "essence-alias" relations or other arcroles someone creates such as the ones I created such as these or these. Ultimately, people will figure this out and more of these arcroles and other such things will end up in the XBRL International Link Role Registry.
Considering all of those details above, this is what I speculate. The ultimate goal is some sort of reasoner, processor, inference engine, math engine, and so forth that is specific to business reports. If another layer above the business report needs to be created for the special case of financial reporting, fine. But try to avoid the separation if possible. Recreating PROLOG or DATALOG might, or might not be a good idea. I don't know. If an XBRL Formula processor is based on PROLOG, as I have been told by people I trust, then does an XBRL Formula Processor already do a lot of what PROLOG does?
The lack of a global standard chaining model will eventually be solved, it has to be. Either a global standard will be created or a de facto standard will appear. Probably both forward and backward chaining models will likely be created. Perhaps chaining models already exist. Can you get away with forward chaining alone? I doubt it.
Again, please read the Digital Financial Reporting Manifesto for more details. While the organization of that document could use improvement, all the important information is there.
Know the answer to this question? Please let me know because I am seriously looking for an answer because I am working with some people who are building approaches to processing all this fundamental accounting concept relations and other metadata.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
Post a Comment
 View Printer Friendly Version
View Printer Friendly Version Email Article to Friend
Email Article to Friend
Reader Comments