BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Essential Role of Taxonomies, Ontologies, Schemas, Theories, Models
Taxonomies, ontologies, schemas, theories, and models are not really all that sexy; but they are essential, and often forgotten, when it comes to getting artificial intelligence to fundamentally work or scaling artificial intelligence and get it to perform useful work.
Machines cannot read, interpret, make sense of, or otherwise understand data that has no structure. It is that structure that provides the power. A well designed taxonomy, ontology, schema, of a model are fundamental to teaching machines to understand patterns in data and information.
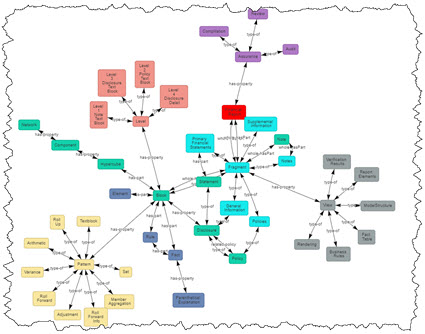
Subject matter experts with knowledge, skill, expertise, and training in an area of knowledge are critical to building taxonomies, ontologies, knowledge graphs, schemas, theories, and models correctly. Clean data is also critical to this pattern detection and documentation process. This process actually has a name, it is called sensemaking.
Sensemaking is the process of determining the deeper meaning or significance or essence of the collective experience for those within an area of knowledge. Sensemaking involves:
- Looking for patterns in information.
- Making connections among different things.
- Synthesizing lots of information and categorizing it into small chunks.
- Think about the big picture.
- Think about the "why" of a situation.
- Organizing and untangling things.
It is this sensemaking that yields the machine-readable taxonomies, ontologies, schemas, knowledge graphs, theories, models, and meta-models that make artificial intelligence fundamentally work and scale and perform useful tasks.
The machine-readable information makes no sense really unless you have a tool that can process the machine-readable information. Pacioli, which I now describe as an XBRL-based Financial Report Knowlege Engine, is such a tool.
The global standards based machine-readable information by itself, like my examples, make no sense if you don't have a tool that can process the information. A tool like Pacioli really makes no sense without all that machine-readable information. But when you put the two together correctly, what appears to be "magic" happens.
But it is not really magic, it is just logic and math.
Subject matter experts in the area of accounting, financial reporting, auditing, and analysis that have the skills, experience, training, and vision will put these pieces together. All this will get better, and better, and better over time as the machine-readable information evolves and the tools improve.
If you want to understand, read the Essence of Accounting, Financial Report Knowledge Graphs, and the Seattle Method. Become a bounty hunter. Help built the accounting oracle machine.
###############################
Terminusdb schema to blueprint appliations
TypeDB, a way to describe the logical structure of your data
 Charlie
in Digital Financial Reporting
|
Charlie
in Digital Financial Reporting
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
SFAC 6 Updated by SFAC 8
Today, Louis Matherne who is the Chief of Taxonomy Development at the FASB posted a message indicating that the FASB has updated Elements of Financial Statements (Chapter 4) and Presentation (Chapter 7) of the US GAAP conceptual framework.
I have represented the SFAC 6 Elements of Financial Statements in machine readable XBRL. Looks like I need to update that.
Elements of Financial Statements and Presentation are foundational. They are the basis for my Fundamental Accounting Concepts Relations.
Just as a reminder, the elements of financial statements defined by the FASB (and learned in Intermediate Accounting class) are:
- Assets
- Liabilities
- Equity (Net assets)
- Comprehensive Income
- Investments by Owners
- Distributions to Owners
- Revenues
- Expenses
- Gains
- Losses
Here are the relationships between the elements: (from this document related to business events)

Elements of Financial Statements says this about the elements of financial statements:
Elements of financial statements are the building blocks with which financial statements are constructed. The term elements refers to broad classes, such as assets, liabilities, revenues, and expenses. This chapter focuses on the broad classes and their characteristics and does not discuss or define particular items that might meet the elements definitions. For example, economic items and events, such as cash on hand or inventory, that meet the definitions of elements are not elements as the term is used in this chapter. Rather, they are called items or other descriptive names. Notes to financial statements are not elements, though they serve important functions that are distinct from elements, including amplifying orcomplementing information about items in financial statements.
For more information please see Essence of Accounting.
########################################
My Version of SFAC 8 in Machine Readable Form
Another version of SFAC 8 which adds features for not-for-profit entities (This is a more precise version)
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Pacioli: an XBRL Knowledge Engine
Pacioli is, I believe, an XBRL knowledge engine. Inspired by this description of Pyke as a "python knowledge engine", this is how I would describe Pacioli:
“Pacioli introduces Logic Programming (provided by Prolog) to the XBRL community by providing a specialized knowledge-based inference/reasoning/logic engine (rules based expert system) written in SWI Prolog. Pacioli, which understands the global standard XBRL technical syntax, the Logical Theory Describing Financial Reports, machine readable XBRL-based financial reporting rules, and XBRL-based financial reports; uses the techniques related to the Seattle Method to safely and reliably work with complicated XBRL-based financial information contained within those reports.”
You can understand the capabilities of the Pacioli XBRL Knowledge Engine by having a look at the reports on the reports of these dashboards and/or working through these examples.
Pacioli specializes in financial reporting and compliance reporting where report creators are permitted to make modifications to the report model. By way of contrast, LodgeiT is a compliance platform that specializes in tax form preparation and submission. Tax forms are, well, "forms".
But financial reports are not forms. Financial reports are knowledge graphs of complex information. Because of the way financial reporting works, the creators of financial reports are permitted to make modifications to the reports and their supporting report model. But report and report model modifications must be kept within permitted boundaries. The Seattle Method is used to articulate those permitted boundaries using machine-readable global standard XBRL-based rules. Those machine-readable rules help control report model modifications, keeping those modifications within permitted boundaries. Pacioli is the "engine" that drives this process and is used to verify report quality.
I started with a theory way back in 2012. But a theory is no good unless you prove the theory. Well, I have proven the theory by putting literally 100% of the XBRL-based financial reports submitted to the Securities and Exchange Commission (SEC) in both US GAAP and IFRS into the model represented by that theory. The most current version of my theory, Logical Theory Describing Financial Report (Terse), tunes the model and terminology. I have created a theory, framework, principles, and a method.
The Pacioli XBRL Knowledge Engine passes all my tests and supports my model, proving the theory and the model.
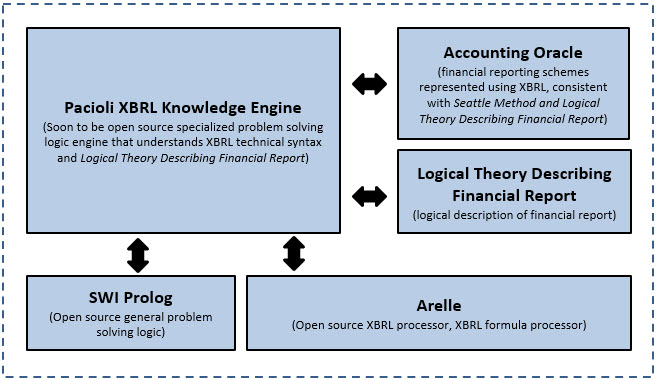
Let digital financial reporting begin!
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print
Learning XBRL-based Digital Financial Reporting
The following sets of examples are helpful in understanding and learning XBRL-based digital financial reporting. The best practices/good practices outlined by the Seattle Method are the basis for these examples.
This set of reports first walks you through very small reports and then increases the size of the report. It helps you see and understand that reports are made up of many logical fragments.

This set of reports helps you see and understand the importance of and the need for specific verification tasks to be performed in order to be sure an XBRL-based report is verifiably properly functioning.
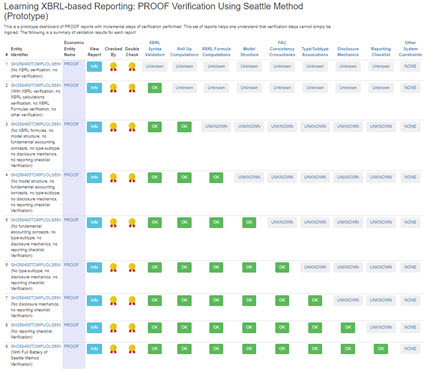
This set of reports shows you common errors that are made when creating XBRL-based financial reports and how those error are detected using sound procedures and good software tools. (much more coming soon)

DOW 30: (complete)
This set of reports helps you recognize that every report, even for the biggest companies in the world, follow the above dynamics.
Fortune 100 (Work in progress)
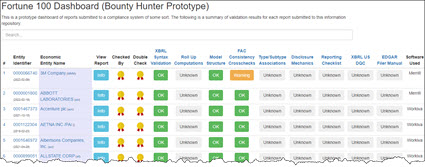
ESEF (European Single Electronic Format): (work in progress)

All of these and more examples can be downloaded here with documentation which shows you how to run the verification using Pacioli. To take your skills to the next level, try Essentials of XBRL-based Digital Financial Reporting. Then, look through these high-quality examples of errors. For even more details, see these high-quality explanations of errors in XBRL-based reports.
Charlie
in Digital Financial Reporting
|
Post a Comment
|
 1 Reference
| Email
| Print
1 Reference
| Email
| Print
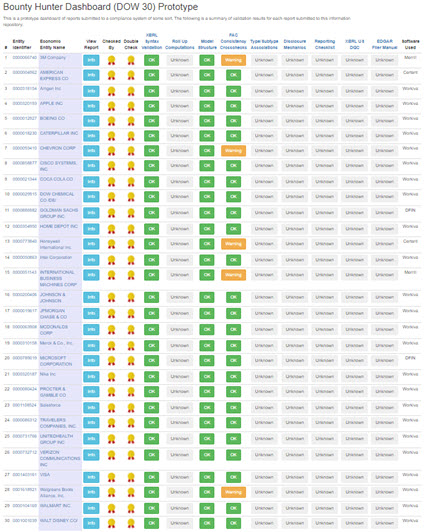
Bounty Hunters
I got the idea of bounty hunters from The Graph (specifically, The Graph Network in Depth Part 2). The Graph calls them "fishermen" and "arbitrators". Others call them bounty hunters.
The purpose of bounty hunters (a.k.a. fishermen, arbitrators) is to expose and fix errors in the system; incorrect information that got into the system, disputes, inconsistencies, and so forth.
In the case of XBRL-based financial reports submitted to the SEC incorrect information could take the following forms:
- Errors made by economic entities creating their XBRL-based financial report.
- Errors made by the creators of XBRL taxonomies such as the US GAAP or IFRS XBRL taxonomies.
- Errors made by those creating rules to control expert systems, test XBRL-based reports, or extract information from such reports.
- Bugs in software applications used to process XBRL-based financial reports.
This is kind of like how hackers expose security flaws in software. Think about it. How useful are XBRL-based financial reports if there are errors in those reports and data aggregators extract information that contains errors? How effective can public companies be creating XBRL-based reports if the base XBRL taxonomies for US GAAP and IFRS have mistakes or missing information? How well will software work if XBRL taxonomies are incomplete or contain mistakes?
The only way for automation to be possible and the benefits of such automation, such as extracting information from XBRL-based financial reports, is if all the pieces are working correctly. Bounty hunters help improve information quality.
Click on the image below and see a bounty hunter's dashboard that I prototyped for the DOW 30.
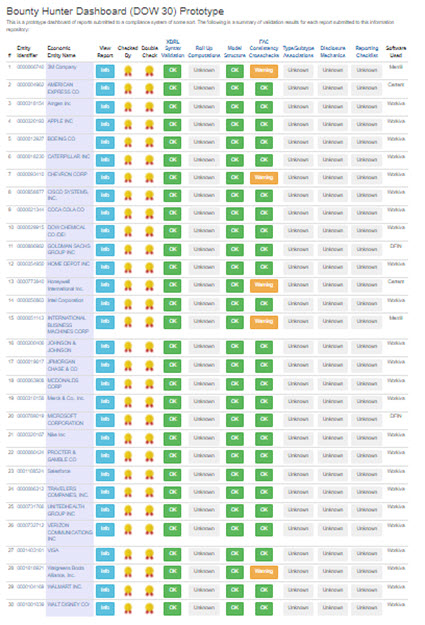
I have similar dashboard prototypes for the Fortune 100 and the S&P 500. Others will exist for the Russell 1000, Russell 3000, and other groupings of public companies. The equivalent will exist for listed companies in the European Union and other regulatory jurisdictions.
Bounty hunters play a role in the coordination of systems. Stay tuned for another blog post that explains the dynamics of bounty hunting and how you can become a bounty hunter and make money.
########################
Charlie
in Digital Financial Reporting
|
Post a Comment
|
1 Reference
| Email
| Print
