BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Bittrex Global, Tracking the AUDT Token
Auditchain listed their AUDT token last week. You can see the market for AUDT in terms of US Dollars using the USDT-AUDT market on Bittrex Global. Here is the deal though. Bittrex Global is not usable in the United States in some areas, I believe because of securities laws (but I am not sure). You can get around this by using something like ProtonVPN to change your IP address.
This video, Bittrex Global Tutorial for Beginners, provides a good introduction to using Bittrex Global.
If you want to join the discussion about AUDT, check out this Discord channel. Or, watch Facebook or Twitter.
Auditchain and the AUDT token may, or may not, succeed. But what is certain is that things are changing, the pace of change will only increase, and Auditchain or something like Auditchain will have a significant impact on accounting, reporting, auditing, and analysis.
You can also track the AUDT-USDT trading pair on TradingView.com
 Charlie
in Digital Financial Reporting
|
Charlie
in Digital Financial Reporting
|
 Post a Comment
|
Post a Comment
|
 1 Reference
|
1 Reference
|  Email
|
Email
|  Print
Print
Syncfusion Software GUI/UX
Syncfusion has some excellent demos of software interfaces for cloud-based software applications. You can demo every control. You can look at and run the code on Stackblitz.
Visirule is an application created using Syncfusion controls.
Pivot table controls. This is a comparison of pivot table controls.
Charlie
in General Information
|
Post a Comment
|
1 Reference
| Email
| Print
Baseline and Comparison of Fundamental Financial Report Logic
I did this comparison of financial reporting schemes in another blog post. This blog post tunes and enhances that prior comparison.
At the heart of Pacioli which was created by Auditchain lies a new unifying logical perspective upon financial reports.
Here is what I mean. Look at the graphic below (here is the document that contains the graph and more details). Consider the following and as you do have a look at the GREEN bars on the Pacioli summary page that show that EVERY financial reporting scheme can consistently represent the same logic within their XBRL taxonomy (or SHOULD be able to). Consider:
- Is a roll up different in US GAAP, IFRS, UK GAAP, AU GAAP? No.
- How about a roll forward? Same.
- Adjustment (Originally stated balance +/- any adjustments to arrive at a restated balance)? Same.
- A member aggregation (which is simply a roll up represented using a different technical approach)? Same.
- Variance? Same.
- Is “arithmetic” different in US GAAP, IFRS, UK GAAP, AU GAAP? Of course not.
- Is "logic" used by US GAAP, IFRS, UK GAAP, AU GAAP different? Of course not.
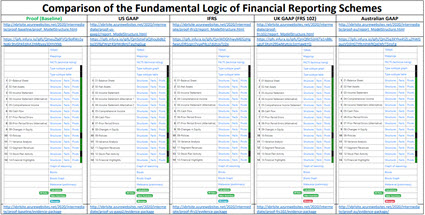
Here is a visual representation of the mathematical interconnections:
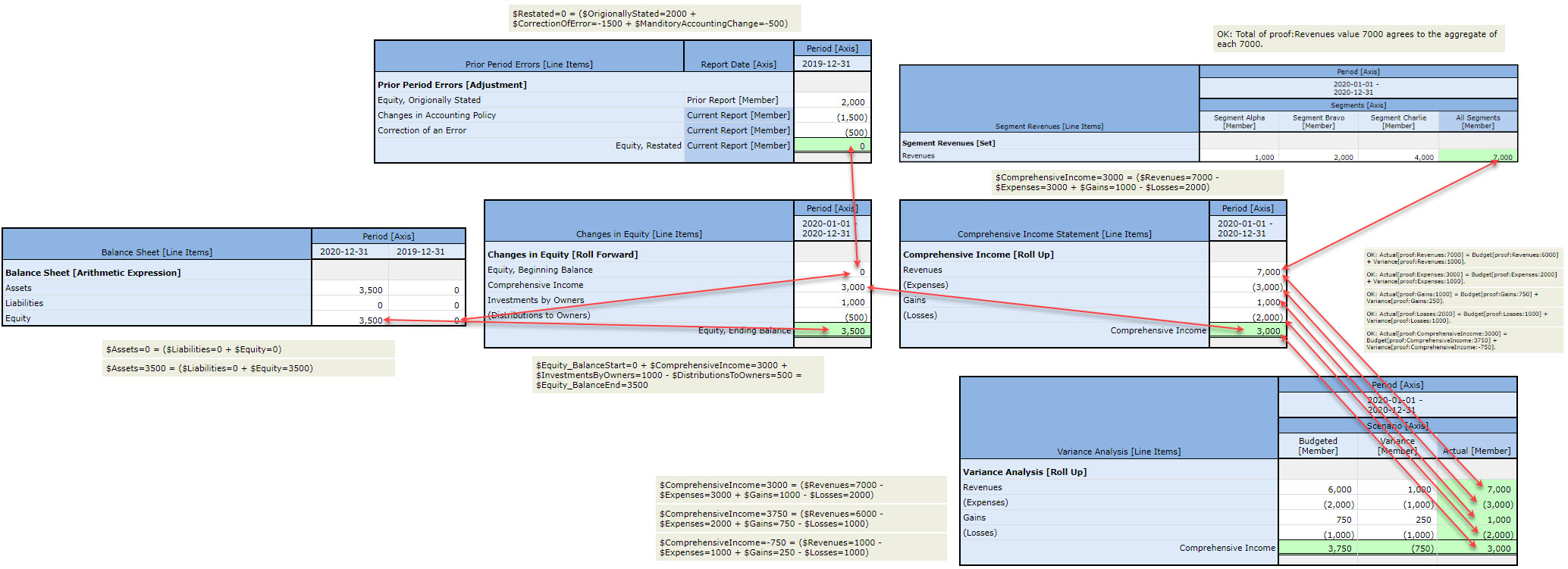
Here is the next level of logic, the elements of financial statements of numerous financial reporting schemes.
And so, not only are financial reports knowledge graphs, there is a logical meta-model that describes financial reports generally (see Logical Theory Describing Financial Report). It is this consistent logic that provides the patterns that are used to control processes; the basis for the Seattle Method. This is the magic of the double entry accounting model and the accounting equation. To understand, start by reading the Essence of Accounting. Then, dive into the Essentials of XBRL-based Digital Financial Reporting. Then check out these examples that will help you better learn XBRL-based digital financial reporting.
Charlie
in Digital Financial Reporting
|
Post a Comment
|
1 Reference
| Email
| Print
AUDT token makes its debut on Bittrex Global
AUDT token makes its debut on Bittrex Global. Here is Bittrex.
This blog post is my personal take on what Auditchain is.
Charlie
in Digital Financial Reporting
|
Post a Comment
|
2 References
| Email
| Print
Code is a Liability, Not an Asset
The "no-code" or "low-code" movement is interesting. This article, The Quest for Low-Code: 9 paths, some of which actually work, is worth reading. One statement made is the following:
Domain Languages have one major advantage: they don’t need to solve all problems but only those within a specific domain. By choosing a narrow domain, you can reduce the amount of flexibility you need and therefore the amount of code you have to write.
The article also points out that "Many of the effective domain languages are declarative." XBRL is declarative.
This product, VisiRule, is an example of no-code, low-code. It was created by Logic Programming Associates (LPA). This YouTube video, How to Make a VisiRule Chart, demostrates how code is generated. Here are some other resources worth checking out.
#################################
Charlie
in Digital Financial Reporting
|
Post a Comment
|
1 Reference
| Email
| Print
