BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from April 1, 2017 - April 30, 2017
High Quality Examples of Errors in XBRL-based Financial Reports
Below are links to PDF files that have high-quality documentation of approximately 380 errors that exist in XBRL-based financial reports of public companies which and been submitted to the SEC as of March 1, 2017. I detected these errors as part of my measurement of the fundamental accounting concept relations and the continuity errors discovered as part of those cross-checks.
Examining and understanding these errors can help professional accountants improve their skills in working with XBRL-based digital financial reports and software developers create software useful to business professionals that help them not make these sorts of mistakes.
I created this information so that I could provide it to professional accountants who were not detecting these errors when they created their XBRL-based financial reports. Over the past several years I have made this information available to filing agents and software vendors which they used to understand and fix these sorts of errors. These 380 errors are about one quarter of the remaining high-level errors in the set of about 7,000 public company financial reports.
These errors tend to be very uncontroversial. Proof of that is that software vendors and filing agents, once they are made aware of these errors; fix these errors. For example between 2015 and 2017; Merrill went from 55% consistent to 97% consistent; RR Donnelley went from 73% to 98% consistent; DataTracks went from 62% to 98% consistent. (See the comparison of periods here.)
All of these errors were detected using processes that have been implemented in commercial software. For example, here is a tool provided by XBRL Cloud which they make available on their Edgar Dashboard.
None of these errors are related to the XBRL techical syntax. The errors all relate to employing XBRL to convey meaning. These are logical, mechanical, and mathematical mistakes made by the creators of the reports. Software needs to support the functionallity to detect these sorts of errors. Here are a few examples of the patterns of errors that you find in the XBRL-based financial reports of public companies: (documented by the PDFs provided below)
- Reporting contradictory/conflicting information. For example, reporting "revenues" facts that contradict one another.
- Using concepts incorrectly relative to other concepts. For example, WHOLE/PART relations that are wrong such as using "us-gaap:CostOfRevenues" (DIRECT operating expenses) as a PART OF "us-gaap:OperatingExpenses" (INDIRECT operating expenses) when they should have used the concept "us-gaap:CostsAndExpenses" (TOTAL DIRECT + INDIRECT operating expenses)
- Simply using the wrong concept. For example, a common error that you will see is using a concept that relates to "Other comprehensive Income" to represent a line item related to "Comprehensive income" because an incorrect concept was mistakenly selected.
- Creating completely XBRL valid relations, but the relations either is inconsistent with the US GAAP XBRL taxonomy or literally CHANGES THE MEANING of US GAAP.
- Creating unjustifiable extension concepts. For example, a handful of public companies create the extension concept "my:TotalAssets". Really?
Each of these errors are logical errors, mechanical errors, or mathematical errors which have NOTHING to do with XBRL technical syntax. Each error was represented using PERFECT XBRL technical syntax; but the information conveyed was just wrong.
Principles help you think about something thoroughly and consistently. As a result of my measurement of the fundamental accounting concept relations, I created the XBRL-based digital financial reporting principles. They help you think about XBRL-based reports.
This information should be very helpful to professional accountants creating XBRL-based reports and software developers building tools those professional accountants use. There are those reports grouped by audit firm. I am not saying that any of these audit firms have responsibility for any of these inconsistencies, I am simply making this information available in this form because I also sent this information to each audit form to help them understand these sorts of errors. (April 2017)
- BDO:
- EY:
- KPMG:
- PWC:
- Deloitte:
- Other
Happy learning! Oh, if you are wondering why I am taking time to put together the business rules for discovering there errors; have a look at the components of an expert system and/or check out my little expert system for creating financial reports. The rules contribute to making the expert system work.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
World's First Expert System for Creating Financial Reports
Remember when I posted that I had created the world's first machine-readable financial reporting checklist? Well, I now have a machine that can read that checklist.
I believe that a software developer and myself have created what I can honestly call the world's first expert system for creating financial reports (as far as I am aware).
But what is even more interesting is that what drives this expert system is a global standard XBRL-based general purpose business reporting expert system. The system is both in the form of a tool that is very approachable by business professionals and an API interface.
There are many sources for defining what an expert system or what people are now tending to call "knowledge based systems". This web site points out two very important things. First, the components of an expert system. Secondly, which is even more interesting, is a discussion of a notion of a general purpose expert system. Imagine an expert system where the syntax of the fact database and knowledge base is a global standard: XBRL.
The diagram at the bottom of this post explains the components of an expert system. Here is how we implemented those expert system components in our software:
- Knowledge acquisition: The domain knowledge which was represented represented in the form of machine-readable business rules were created manually (i.e. not via machine learning). And so, the application has interfaces for creating business rules.
- Knowledge base of rules: The knowledge base of rules is represented 100% using the XBRL technical syntax. The knowledge base of rules includes an XBRL taxonomy schema, XBRL linkbases, and XBRL Formulas. I defined some XBRL arcroles that are used in the XBRL definition relations to represent specific types of relationships.
- Fact Database: The fact database is an XBRL instance or set of XBRL instances. My fact database can be from ONE XBRL instance such as a single financial report, all the different periodic reports of one entity, the reports for some set of economic entities that report, or all the way up to every XBRL instance that makes up the SEC EDGAR database.
- Reasoning, Inference, Rules Engine: The reasoning/inference/rules engine is an XBRL processor + and XBRL Formula processor + additional processing that overcomes specific deficiencies in the XBRL Formula specification. The primary deficiencies relate to a lack of chaining (we support forward chaining, a lack of inference logic to derive new facts using the rules of logic, and deficiencies in specific types of problem solving logic (which we added via the XBRL arcrole definitions).
- Justification and Explanation Mechanism: The justification and explanation mechanism provides information, generally in a controlled natural language type format, which is very readable and understandable to business professionals and an "audit trail" that enables a business professional to trace any piece of information all the way back to its origin within a financial report fact or knowledge base business rule.
Using the notion of "profiles", the application supports US GAAP-based financial reporting, IFRS-based financial reporting, what I call a "general profile" that provides an architecture and any business reporting scheme simply has to supply the metadata for that reporting scheme. Here is a brief initial video that I have created to help show the GUI.
Here is a document that helps you understand the current validation capabilities of the application. Why is this important to understand? Because it helps you understand the knowledge that is in the applications knowledge base of rules and the capabilities of the reasoning/inference/rules engine.
In my view the approach that we took to create this application is very interesting and provides insight that would help others leverage the XBRL global standard. We are very happy to help others who want to understand what we believe we have created. If you want additional information, please contact me. Additional information will also be provided on my blog.
Components of an Expert System:
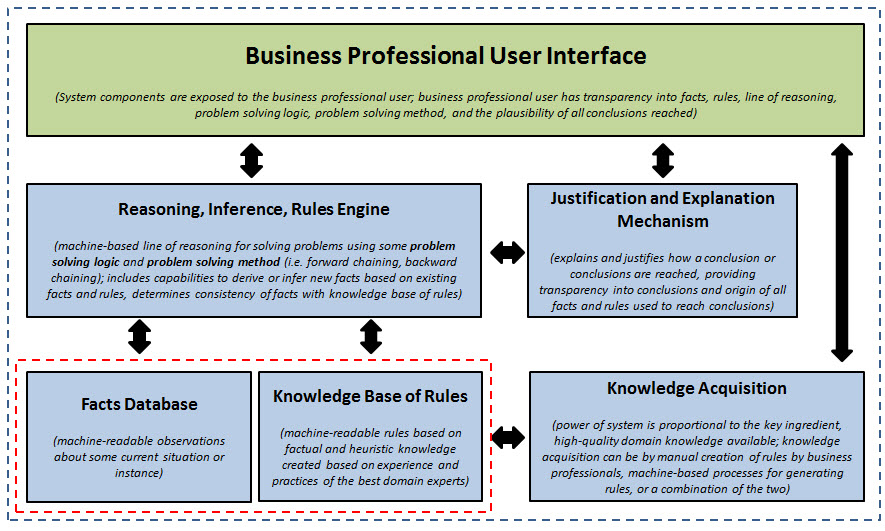 (Click image for larger view)
(Click image for larger view)
Processing Complex Logical Information or Structured Knowledge
(Please consider this a draft at the moment, a work-in-progress. I am trying to get this 100% precise. That is doable, but this is a painstaking task because it is so detailed and there are parts that I am pulling together and learning as I write this information.)
Artificial intelligence is coming perhaps sooner than you might realize. For example, the article The Use of AI in Banking is Set to Explode says that 32% of all banks use some sort of predictive technology. This Wired article starts off,
"IT'S HARD TO think of a single technology that will shape our world more in the next 50 years than artificial intelligence."
And this article, Top 5 Jobs Robots Will Take First, points out that accountants are high on the list of those who will be impacted by AI. My personal view is that the best way to protect your job is to learn as much as possible about AI and how it works.
A financial report is complex logical information.
Before XBRL, a financial report was unstructured information and therefore the only way you could interact with that financial report was to have a human that understands financial reports read the financial report and pull information out. Or, possibly, you would write a computer algorithm that would parse the unstructured text to try and glean information from the financial report.
With XBRL, information reported in a financial report is structured and can still be read by humans using renderings generated from the structured information; but the information can also be read by machine-based processes directly. (See the video How XBRL Works for more information about the difference between structured and unstructured information.)
So how do you process complex logical information, or structured knowledge, such as the information found in an XBRL-based intelligent digital financial report? How do those creating such reports create the reports correctly so that the reports mean what the creator intended so that the correct information is conveyed to users of the financial report? How to analysts, investors, regulators and others know that the report they are using has been created correctly? How do standard setters such as the FASB know that they created the US GAAP XBRL Taxonomy correctly to enable the creator and users to interact with harmony, minimizing dissonance?
Well, people (meta-engineers) like Benjamin Grosof, Ian Horrocks, John Sowa and others have been working to solve that problem for 25+ years. Today if you try and look for an answer to the question, "How do you process complex logical information?" the answer exists but that answer looks like a bit of a convoluted mess if you don't understand what has been going on the past 25 years. But it is not really a mess. There are different opinions because there are different "camps" because there are different needs, different target audiences, and different approaches have been taken to solve the same problem. There is a solution and I will get to that.
But the problem itself, processing complex logical information, has its roots in artificial intelligence. That is one of the problems the artificial intelligence community had to solve in order to get artificial intelligence to work. Does artificial intelligence work? Well, the article The Use of AI in Banking is Set to Explode seems to think so. There are other clues that it is working.
So how did they make it work? Who made it work? To process complex logical information you had to represent that complex logical information in a form that a computer would read, understand, and effectively work with. Three general approaches were used to solve that problem:
- Ontology: This lead to what has become the "Semantic web stack".
- Business rules: This lead to the Business Rules Manifesto, an entire business rules community, business rules management systems, etc.
- Schema: This lead to database schemas such as SQL, XML Schema, and other such schema-based approaches for describing information.
One more approach to representing complex knowledge is worth mentioning. Description logic is another method to representing complex knowledge but in the past, description logic was not machine-readable. That is changing. OWL 2 DL has a description logic style syntax and supports SROIQ description logic as I understand it.
There are two approaches to specify knowledge: based on axioms (used by ontology) and model based (used by business rules and schema).
So who got it right? Is an ontology, business rules, or a schema the best way to represent complex logical information? Is it better to use axioms or a model to represent knowledge? There has to be only one best way, right? Well...no.
In an article, The Semantic Web and the Business Rules Approach ~ Differences and Consequences, Silvie Spreeuwenberg answers that question in this way:
"Fundamentalism for one position undermines collaboration between the two communities."
I agree with Ms. Spreeuwenberg. Too many people tend to exist in silos and believe everything in their silo is right and every other silo is wrong. Another way to say this is, "If the only tool you have is a hammer, then everything looks like a nail."
Some people, like the meta-engineers I mentioned, crossed the silos.
In another blog post I pointed to a paper by John Sowa that explained the problems caused by fads, trends, misinformation, politics, arbitrary preferences, and competing standards.
There is something that is common between all three knowledge representation approaches: ontology, business rules, and schema. That common thing is logic. As I mentioned in the blog post Describing Systems Formally, Aristotle created logic in about 450 B.C. Logic is a discipline of philosophy. Logic has been around a long time and is useful for many things.
Logic is the study of the principles of correct reasoning. Formal logic helps identify patterns of good reasoning and patterns of bad reasoning. These logic systems can be used to describe how things work so you can understand if they are working as expected.
Another definition of logic from the Book of Proof is as follows. Logic is a systematic way of thinking that allows us to deduce new information from old information and to parse the meanings of sentences. There are different definitions of logic and you could likely have interesting philosophical and theoretical debates about logic. Or, you can use logic as a useful tool.
Business professionals use logic and reasoning in everyday life. Logic and reasoning are not hard to understand; in fact, humans tend to have an innate understanding of logic and reasoning. Some people tend to use logic and reasoning more than others but that is a different story.
Business professionals care about correct reasoning. As I explained in the 15 XBRL-based Digital Financial Report Principles, fundamentally a financial report is a system and that system needs to work. There needs to be harmony between all the stakeholders that play a role in the process of working with financial reports: standards setters, report creators, data aggregators, analysts, regulators. Logic can serve as a communications tool that helps maximize harmony.
Each of these stakeholders tends to have a natural understands logic. People who have no formal training in logic still tend to understand logic. Sure, perhaps a bit of additional training in logic would help business professionals work with complex logical information even better.
OK, so let us assume that you buy the argument that logic is a good tool to describe complex logical information. Let us assume we want to use logic. Which logic is the best logic to use for the task? There are lots of different logic systems.
In his presentation, Survey of Knowledge Representations for Rules and Ontologies, Benjamin Grosof answers that question. That presentation is very technical. I have tried to distill the essence of what Mr. Grosof is saying into this explanation below that should be both accurate and understandable by business professionals.
Here is an overview of some logical systems. What I am concerned with is picking the logical system that can be used by software application so that the software provides results that are reliable, predictable, repeatable and otherwise safe to use. (i.e. software that blows up on us or is not reliable is not very useful to business professionals)
- Higher order logic tends to be powerful but unsafe to implement in software because it tends to be too complex and can lead to unexpected or unpredictable behavour by the software.
- First order logic (a.k.a. first order predicate calculus, predicate logic) tends to be safer to implement in software, but not all first order logic is safely implementable in computer systems.
- Horn logic is a subset of first order logic. Horn logic is safer than first order logic because it explicitly prohibits some things that make it first order logic unsafe. But Horn logic is still not safe enough for many ways business professionals use software. Prolog uses Horn logic as does ISO Prolog.
- Datalog imposes additional specific restrictions on Horn logic making the Datalog logic provably safe, reliable, and therefore predictable. Datalog is a subset of Prolog that is, as I understand it, as safe as a SQL database.
- SQL or relational databases were the first commercially successful semantic technology. SQL is based on relational algebra which is based in logic. SQL is reliable, predictable, and therefore safe. Business professionals have been successfully using relational databases for 35 years. They trust relational databases. Do relational databases make mistakes? Actually no, they don't. Programmers and others might make a mistake in logic in their interaction with a SQL database. But the SQL database itself reliably and predictably provides answers to the questions we ask and they don't blow up. Why? Because of the logic system that relational databases use.
- RuleLog safely extends Datalog adding some specific aspects of higher order logic that can be safely implemented. For example, RuleLog adds non-monotonic or defensible inferences. You can think of non-monotonic logic as reasoning based on probabilities.
The following is my best attempt to describe a deductive system using terms which a business professional might be familiar with.
A properly functioning deductive system must be sound, complete, and effective. A fundamental principle of logic is that a fact (or declarative statement or proposition) is a logical consequence of one or more other facts (or declarative statement or proposition). A deductive system is sound if any fact that can be derived in the system is a logically valid fact. A deductive system is complete if every logically valid fact is derivable. A deductive system also shares the property that it is possible to effectively verify that a purportedly valid deduction is actually a valid deduction; such a deduction system is called effective.
A deductive system can be extended. While a fact might not be directly derivable; a fact may be defensible. Probabilistic reasoning or non-monotonic logics provide the feature whereby non derivable but defensible inferences can be made. It is crucial that derived knowledge and non-derived but defensible knowledge be distinguishable.
Systems are not homogeneous, they tend to be heterogeneous even within one organization. As such being able to use either ontology-based approaches, rule-based approaches, and/or schema-based approaches to describe complex logical information has advantages. But to exchange information between these different systems the systems must agree on a logic.
The following graphic shows somewhat of a hierarchy of logics. Business professionals need to be conscious of the capabilities of the problem solving logic they are using, the expressive power of the problem solving logic, and the propensity of the problem solving logic to "blow up" or have some sort of catastrophic failure (i.e. not be safe to use). If this information is laid out appropriately then business professionals can make good choices.
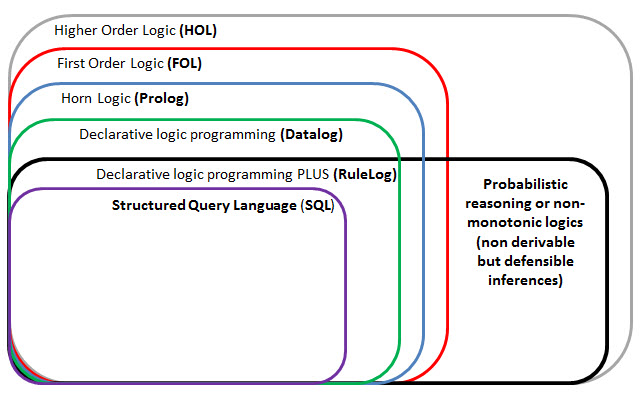 (Click image for larger view)
(Click image for larger view)
There are two logics that I left off the graphic above that are very important but I did not add them because I don't want to clutter that fairly straight-forward graphic and I don't know the relative problem solving logic. The two logics are ISO/IEC Common Logic and OMG Semantics of Business Vocabulary and Business Rules (SBVR). Common logic and SBVR are logically equivalent as I understand it. As I understand it, they are a subset of RuleLog. I would also like to understand where OWL 2 DL fits into that graphic. All things considered, the safest and most expressive problem solving logic is RuleLog.
The graphic below shows a complete knowledge based system. In order to process complex logical information while you do need some sort of problem solving logic, it does not matter if you use an ontology, or business rules, or a schema as a delivery mechanism for that logic. You also need to be conscious of the expressive power of the problem solving logic.
(Click image for larger view)
But it is important that your system is provably sound, complete, and effective. Your system needs to work. Your complex logical information needs to be correct. Business professionals need to know that information is correct and that systems are reliable, operate predictably, and are otherwise safe.
A question that you might have is, "What syntax should you use to represent the logic you select?" I will answer that question in a blog post in the very near future.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
|
 8 References
| Email
| Print
8 References
| Email
| Print
Public Company Quality Continues to Improve, 11 Quality Leaders
There are now 11 software generators and filing agents that have 90% or more of their XBRL-based public company financial reports consistent with all of the fundamental accounting concept relations continuity cross-checks.
This ZIP file contains an Excel Spreadsheet which contains detailed information about errors.
Per my measurements, the quality of XBRL-based public company financial reports continues to improve. If you compare the 2016, 2015, and 2014 results you can definitly see the improvement.
Here is the summary of consistency with the fundamental accounting concept relations continuity cross-check business rules as of March 31, 2017:
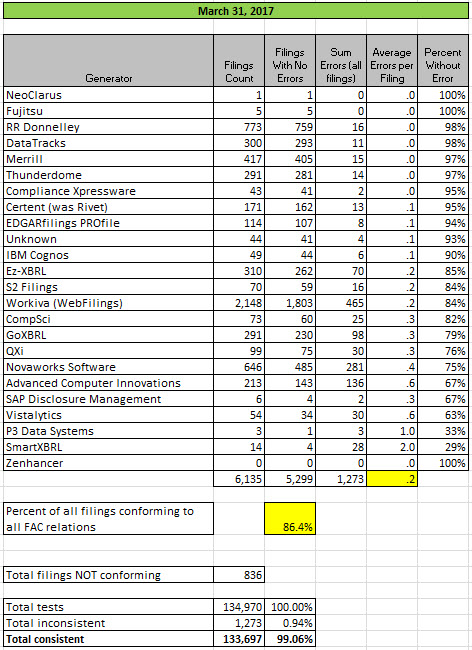 (Click image for larger view)
(Click image for larger view)
Comparison March 2017 with November 2016:
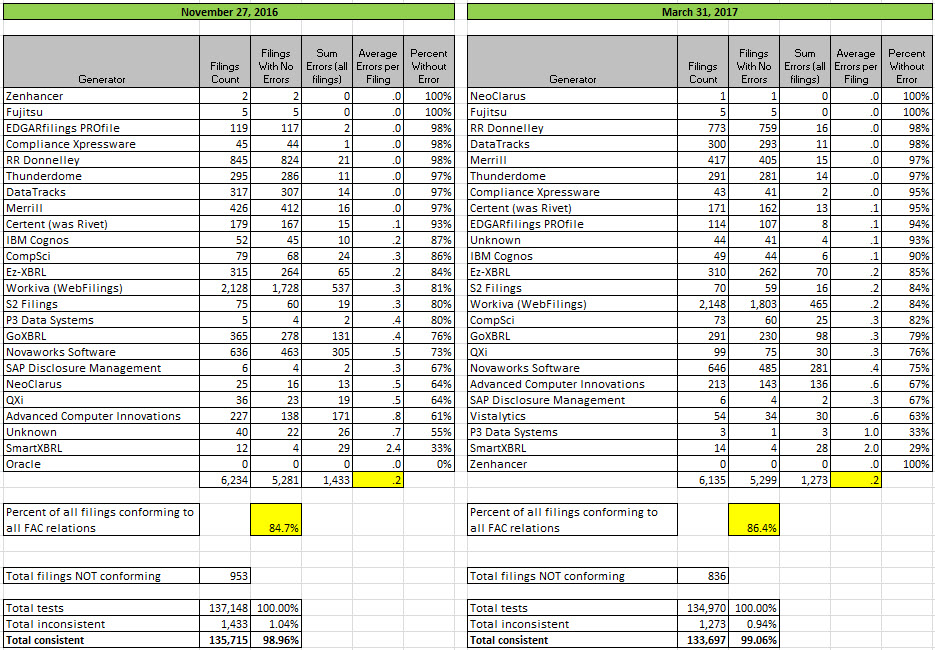 (Click image for larger view)
(Click image for larger view)
Compare March 2017, March 2016, March 2015:
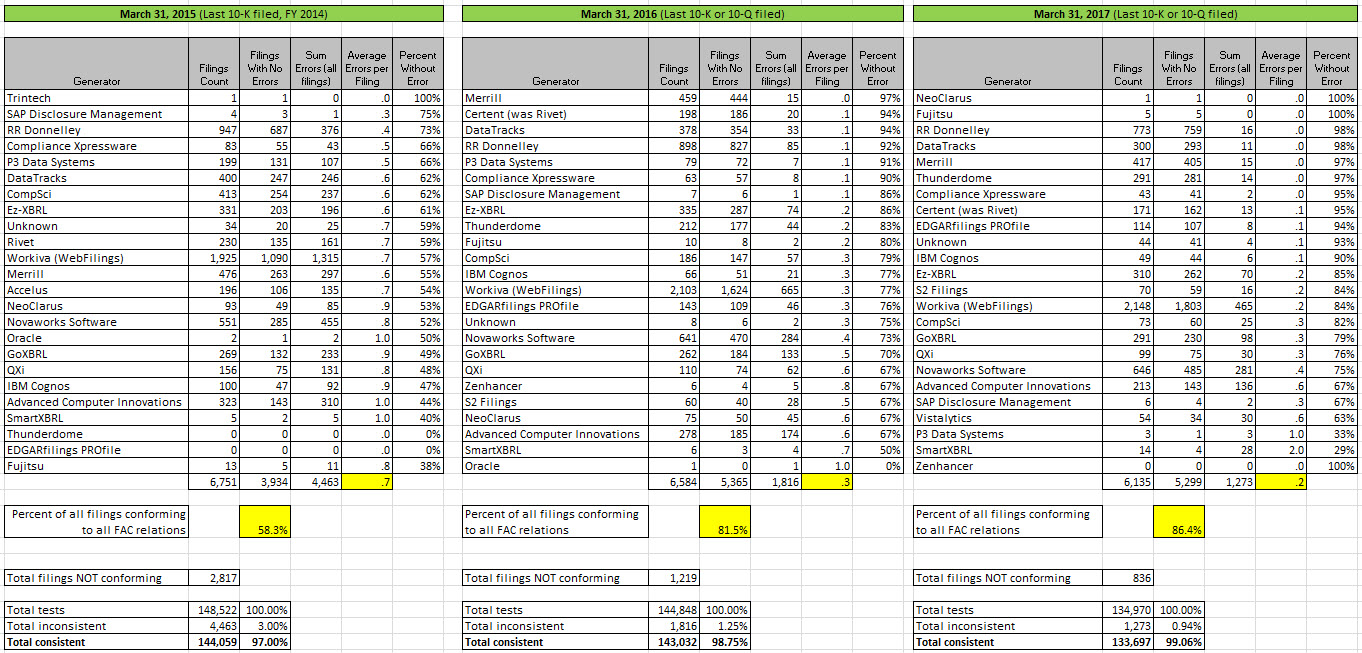 (Click image for larger view)
(Click image for larger view)
**********************PRIOR RESULTS**********************
Previous fundamental accounting concept relations consistency results reported: November 28, 2016; August 31, 2016; June 30, 2016; March 31, 2016; February 29, 2016; January 31, 2016; December 31, 3015; November 30, 2015; October 31, 2015; September 30, 2015; August 31, 2015; July 31, 2015; June 30, 2015; May 29, 2015; April 1, 2015; November 29, 2014.
Charlie
in Creating Investor Friendly SEC XBRL Filings
|
Post a Comment
| Email
| Print

