BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from January 1, 2016 - January 31, 2016
Future of Life Institute: Top AI Breakthroughs of 2015
The Future of Life Institute published an article, Top A.I. Breakthroughs of 2015, which is very helpful in understanding the true capabilities of artificial intelligence.
They categorize the breakthroughs into five categories:
- abstracting across environments
- intuitive concept understanding
- creative abstract thought
- dreaming up visions
- dexterous fine motor skills
This article is worth reading if you are trying to master digital financial reporting. Imagine Siri with an MBA or with an accounting degree.
Don't understand AI? Here is more good information.
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Free Public Company Financial Information Repository
The folks at 28msec, the creators of the SECXBRL.info public company financial information repository have told me that now they are making 100% of the information in their repository available for FREE for noncommercial use. (In the past you could only access information for the DOW 30.)
As I understand it, EVERYTHING from the SEC EDGAR system is now available.
To understand the sorts of things you can do just go fiddle around with the repository. Information is available in human-readable HTML and machine-readable XML, JSON, and CSV.
Here is an updated set of queries against their repository. That set focuses on cross entity comparisons. The queries pull sets of companies: DOW 30, Fortune 100, S&P 500, and Russell 1000. Look at the parameters of the examples I am providing (it is in the form of an RSS feed). Edit my URLs by changing the parameters to create the queries you want.
I will make some additional queries available over time.
This walks you through some of the queries.
Using XBRL Definition Relations to Express Business Rules
My last blog post shows how to leverage the power of XBRL Formula to express business rules. In this blog post I will show lot to leverage the power of XBRL definition relations to express business rules.
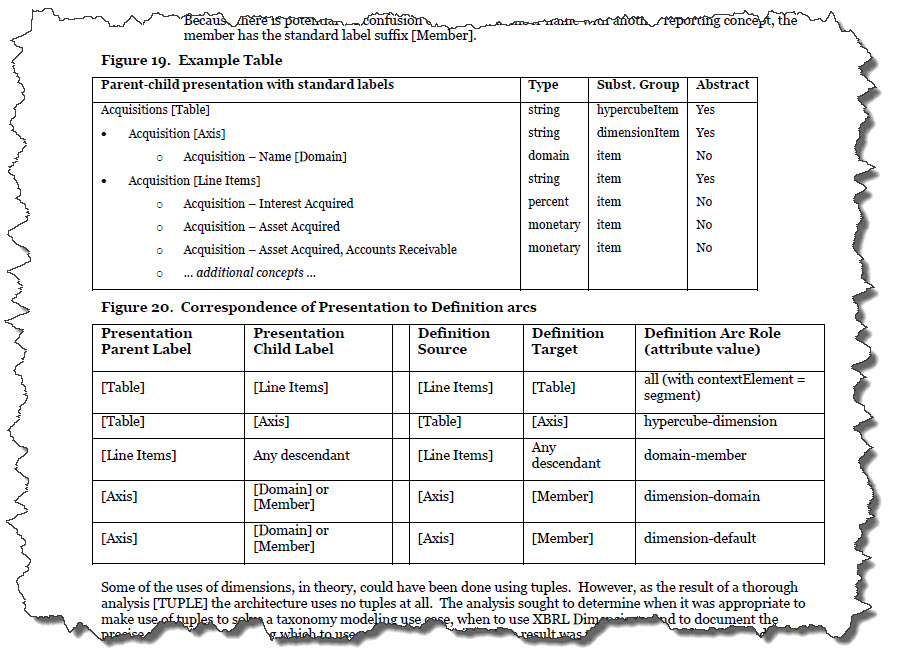
One of the common mistakes people make when working with XBRL is in configuring their XBRL presentation relations appropriately. The FASB understands this issue and on page 24 of this document, section 4.5 Implantation of Tables, they explain, sort of, how [Table]s should be configured.
 (Click image for larger view)
(Click image for larger view)
What do I mean by "sort of"? Well, three specific things.
- The explanation provided is not complete nor precise.
- The explanation does not include representing information when [Table]s are not used.
- The explanation is in human readable form, but not in machine-readable form.
These three issues cause problems in how public companies organize their presentation relations in their XBRL-based financial reports. I took the proprietary approach that I originally used and converted that proprietary approach to an XBRL definition relations based approach. I will walk you through how I did that in the following paragraphs.
First, you need to understand that all of the elements in the XBRL presentation relations can be distilled down into one of the following categories: Network, Table (or hypercube), Axis (or dimension), Member, Line Items, Concept, and Abstract.
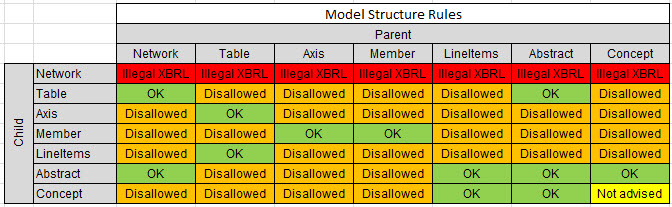
Second, you need to understand as the FASB tries to point out in their US GAAP Financial Reporting Taxonomy Architecture document that there are allowed and disallowed relations between each of those categories. For example, a [Member] is never related to a [Line Items]. You can express the allowed and disallowed relations in the form of a human-readable matrix:
 (Click image for a larger view)
(Click image for a larger view)
That matrix provides more clarity between the allowed and disallowed relations between the categories of report elements within XBRL presentation relations. It is also complete and covers when there is a [Table] (hypercube) or when there is not.
Don't make the mistake of focusing on the specific rules and whether a relation is or is not allowed. That is not the point, that can be a little subjective. The point to focus on is that the matrix provides a complete set of the allowed/disallowed/not advised relations. You can set them however you might desire.
So providing the matrix alone is helpful. That matrix is understandable by humans. But the matrix is not understandable by machines. What if you put that information into machine-readable form? How would you do that? Well, here is how you do that.
First, you have to define a set of XBRL arcroles that define the type of relations you want to work with. I did that here in this XBRL taxonomy schema. If you want to look at those, see the last three arcroles which define the three types of relations: allowed, disallowed, and not advised. That matches the information in that matrix.
Next, I articulated the different relations using XBRL definition relations. You can see that XBRL definition relations linkbase here. Essentially all the linkbase does is articulate relations between the categories of report elements using the arcroles which were defined.
To make the XBRL presentation relations easier to process, the XBRL presentation relations are converted to an easier to read XML infoset. I could do that, but I rely on a web service provided by XBRL Cloud. Here is that XML infoset that shows the relations in an easier to read form. Here are those same relations in human readable form. (If you want to see the XBRL presentations that I am using, here are those.)
Then, I created an application using Microsoft Access to process the XML infoset file and accumulate information about how the elements are related to one another. Here is that VBA code so you can get an idea of what I am doing.
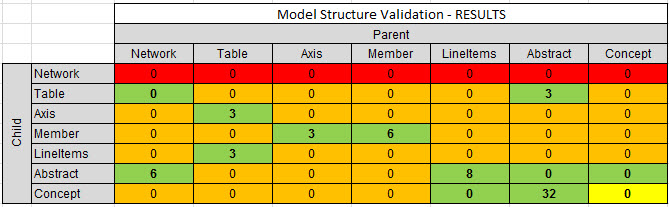
The code looks at the XML file, looks at the allowed relations (which I hard coded, but you could make this dynamic by reading the XBRL definition relations), and then generates a table of the evaluated relationships. I then format the table which is readable by humans and looks like this:
 (Click image for larger view)
(Click image for larger view)
Note that there is no RED or ORANGE cell that has a value other than "0". That means that the XBRL presentation relations follow the rules defined in the XBRL definition relations file.
So, that is only ONE example of the sorts of relationships you can express in global standard XBRL definition relations. A while back I provided another example that evaluates other sorts of relations related to disclosures.
When you combined XBRL Formula based business rules and XBRL definition relations based business rules, that is a lot of expressive power at your disposal in a global standard format. And to the extent you can express information, machine-based can be used to automate work performed by humans. Not all business rules you might want to express can be automated, but a lot can.
When you do this, you have to pay attention to not induce logical catastrophes that cause your rules to fail/crash.
At the time XBRL was being created everyone agreed that XBRL definition relations where very powerful. The XBRL Link Role Registry(LRR) was created to allow for new global standard relations to be created.
Just because most people do not understand the power of XBRL definition relations does not mean that they are not powerful. When you combine the power of XBRL definition relations and the power of a properly implemented XBRL Formula processor, a lot of functionality becomes available to the business professionals who use these global standard tools.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
50 Papers on Data Mining and Machine Learning
50 selected papers related to data mining and machine learning from Big Data Made Simple.
Gaining an Appreciation of XBRL's Power to Express Business Rules
Just because some of those who implement XBRL in a manner that DOES NOT take advantage of XBRL's power to express business rules does not mean that XBRL lacks that expressiveness. A quick reminder that expressiveness of a language is directly related to what can be automated because it minimizes possible information quality issues. And so, understanding XBRL expressiveness is important and understanding how to create business rules leveraging this power is likewise important.
This blog post walks the reader through a prototype for the XBRL US Work in Progress (WIP) Taxonomy which is seeking public comments. I created this prototype to help me understand the taxonomy and to provide feedback to the creators of the taxonomy. While this prototype relates specifically to the WIP taxonomy; the ideas presented here are general to all digital business and financial reports.
The Work in Progress Taxonomy is used by construction contractors and insurance companies to exchange information related to "work-in-progress" information related to construction contracts for the surety bonds issued by insurance companies and banks (loans).
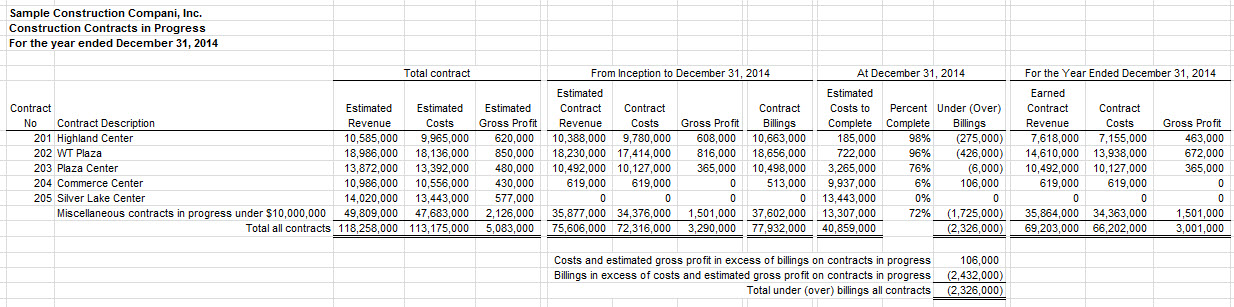
Here is a sample of one specific schedule which a contractor might create an report to an insurance company or bank. The WIP taxonomy is for the creation of such reports. This is a small but relatively sophisticated report so it provides an excellent example for what I want to show. (I got this example from a video of creating this schedule provided by DataTracks.)
 (Click image for larger view)
(Click image for larger view)
I modified that first screen shot slightly to point out the business rules that exist in that schedule. On this screen shot below I have added ORANGE and YELLOW relationship indicators. The ORANGE business rules can be expressed using XBRL calculation relations. The YELLOW are beyond the capabilities of XBRL calculations and require XBRL Formula to express those business rule relations:
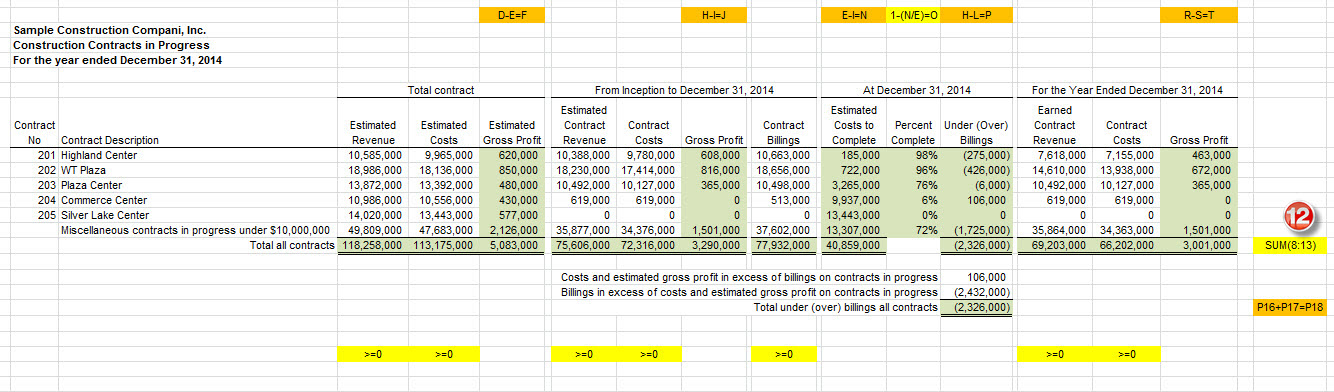 (Click image for larger view)
(Click image for larger view)
If you count you will find that I have pointed out 26 different business rules which need to be represented. There are 15 ORANGE and YELLOW cells, but the YELLOW cell to the far right needs to be created for each of the 12 numeric columns. So 14 of the 15 are created once and 1 needs to be created 12 times; so 14 + 12 = a total of 26 business rules. (I will show you each rule in a moment.) Now, 6 of the 26 rules can be represented using XBRL calculation relations and 20 need to expressive power of XBRL formula to represent the business rules effectively.
If you count the FACTS on the report you will find that there are a total of 93. Keep that number in the back of your mind.
Now, to make what I want to show a little easier, I created the 6 XBRL calculation relations and I duplicated those relations using XBRL Formula; so basically I created all 26 business rules using XBRL Formula so that I can see all the business rules in one location. Here is the XBRL Formula file which contains those rules:
http://www.xbrlsite.com/2016/Prototype/WIP1/abc-20160131_formulas.xml
Now, while that file is easy for machines to read, it can be hard for humans to read. So, here is a list of those business rules in human readable form. Note that the rules that are also expressed using XBRL calculations are shown in ORANGE, the business rules highlighted with YELLOW require XBRL Formula to express:
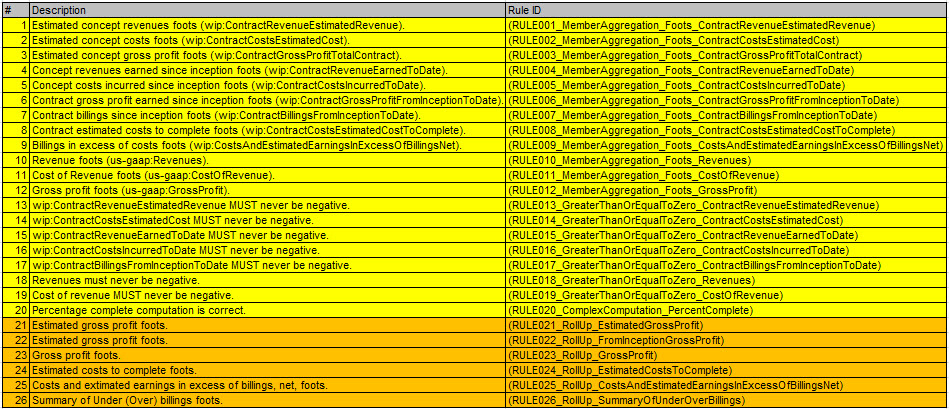 (Click image for larger view)
(Click image for larger view)
When you run the rules against an XBRL instance, some rules might execute more than once. All of the rules will execute based on the relations between the facts. What will make this clear is to actually look at the validation results. The validation results are shown next from two different XBRL Formula processors. Each output has its pros and cons. One list shows the count of 104 times the rules filed, so you can get the total count. The other shows the actual fact values which is helpful. Between the two reports you can get an idea of what the rules do.
Validation results (from the UBmatrix XBRL Formula Processor)
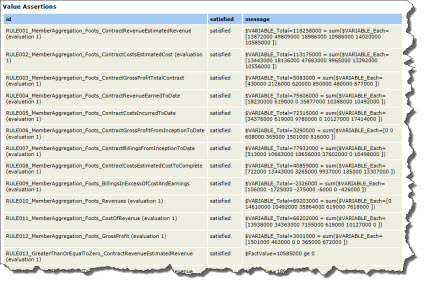 (Click image for complete list)
(Click image for complete list)
Validation results (from the XBRL Cloud XBRL Formula processor):
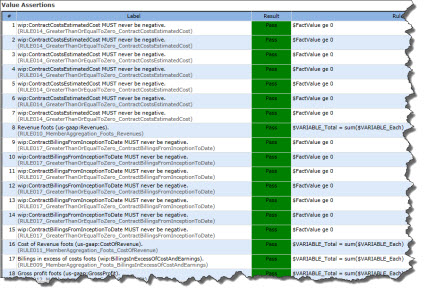 (Click image for complete list)
(Click image for complete list)
And so, a total of 93 facts and 104 tests to make sure the facts are correct if both XBRL Formula and XBRL calculation relations are used. You know what the rule count would be if you ONLY used XBRL calculations? It would be 42.
So what is the deal with the difference between the 104 validations done using XBRL Formula and the 42 that you get using only XBRL calculations? Well, those would be opportunities for error because there are no business rules watching over the information entry process!
It is that gap that is one cause of data quality problems of XBRL-based public company financial reports to the SEC. Notice that I am testing ONE schedule. How many schedules does a 10-K financial report have? Lots and lots.
And I am only focusing on computations here. There are many other types of relations which could be represented correctly, or potentially incorrectly, if you do not have business rules watching over the information creation process. Remember; the only way a meaningful exchange of information can take place is with the prior existence of agreed upon technical syntax, business semantics, and workflow rules.
This graphic can be a bit overwhelming, but it puts all this information into one place. You see the information, you see the rules, and I try and link as much of this stuff together so that you can get your head around it:
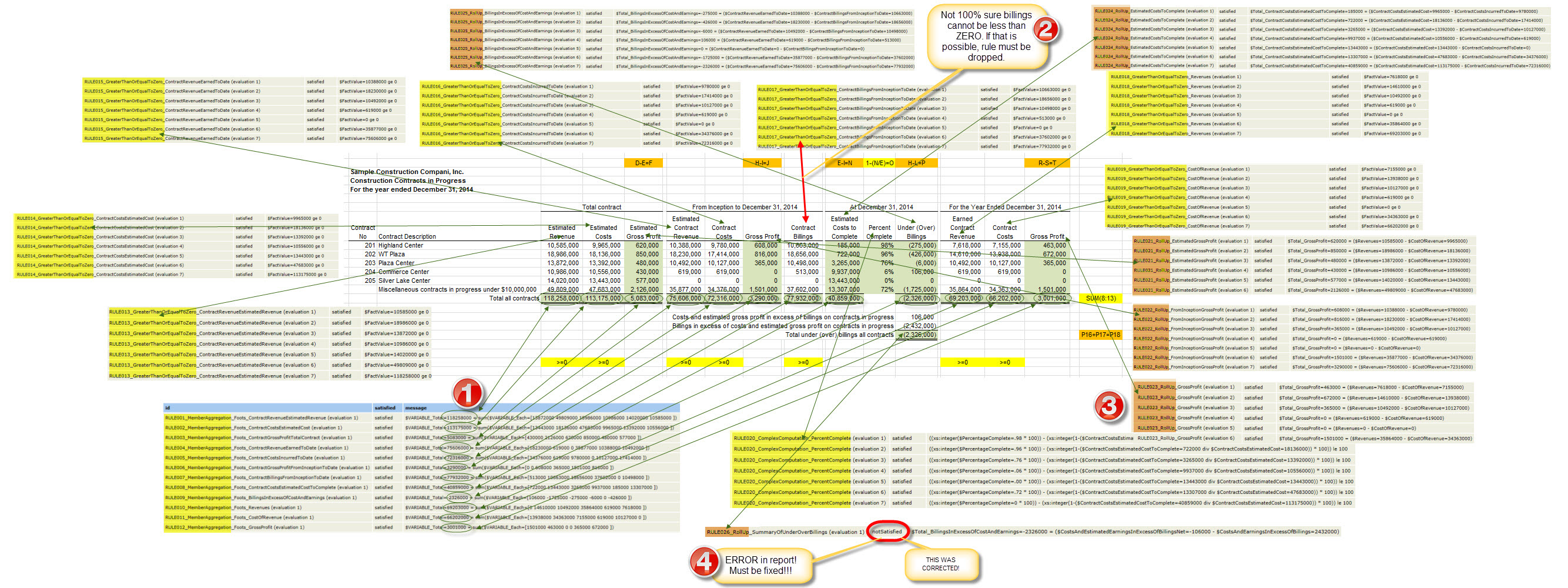 (Click image for larger view)
(Click image for larger view)
I won't bother to explain this. It will resonate with some, not with others.
For those who want to run this validation themselves using their favorite XBRL Formula processor, here is a ZIP file that contains a prototype XBRL instance using the WIP taxonomy which includes the XBRL formula file. I am still working on this prototype so check back for even better versions. (If you don't have an XBRL Formula processor, try Arelle.)
Finally, there are three applications I tested this WIP taxonomy prototype in which provide excellent renderings. Click on each of the links below to have a look at each rendering. Notice how the renderings are very readable with no need for Inline XBRL or the Table Linkbase. That is because the renderings leverage business report semantics. For example, each rendering engine understands the difference between a roll up and a roll forward.
For what it is worth, I have provided similar information but with no real explanations of what I was providing in the past. Here is a reference implementation of an XBRL-based public company filing to the SEC. That shows the interrelations between the fragments of a financial report. Here are some smaller report fragments of what such a report might contain.
XBRL-based business rules using XBRL Formula will very likely be the mechanism used to articulate and rearrange the abstract symbols of financial reports in the future. Understanding this now will provide you with an advantage.
Understanding machine-readable business rules will be critical for professional accountants when digital financial reporting takes off. Don't be left behind.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

