BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from March 1, 2016 - March 31, 2016
Understanding the Importance of Standard Identifiers
Computers are machines. They are tools. Computers have the four basic strengths:
- Storage: Computers can store tremendous amounts of information reliably and efficiently.
- Retrieval: Computers can retrieve tremendous amounts of information reliably and efficiently.
- Repetitive processing: Computers can process stored information reliably and efficiently, mechanically repeating the same process over and over.
- Ubiquitous information distribution: Computers can make information instantly accessible to individuals and more importantly other machine-based processes anywhere on the planet in real time via the internet, simultaneously to all individuals.
To harness the power offered by these useful machines, four major obstacles need to be overcome:
- Business professional idiosyncrasies: Different business professionals use different terminologies to refer to exactly the same thing.
- Information technology idiosyncrasies: Information technology professionals use different technology options , techniques , and formats to encode information and store exactly the same information.
- Inconsistent domain understanding of and technology’s limitations in expressing interconnections: Information is not just a long list of facts, but rather these facts are logically interconnected and generally used within sets which can be dynamic and used one way by one business professional and some other way by another business professional or by the same business professional at some different point in time. These relations are many times more detailed and complex than the typical computer database can handle. Business professionals sometimes do not understand that certain relations even exist.
- Computers are dumb beasts: Computers don’t understand themselves, the programs they run, or the information that they work with. Computers are “dumb beasts”. What computers do can sometimes seem magical. But in reality, computers are only as smart as the metadata they are given to work with, the programs that humans create, and the data that exists in databases that the computers work with. (Andrew D. Spear, Ontology for the Twenty First Century: An Introduction with Recommendations)
Standard taxonomies, such as the US GAAP Financial Reporting XBRL Taxonomy, help to overcome those obstacles. Computers need to be able to grab onto a piece of information and standard taxonomies provide these "identifiers" or "handles" to grab onto or "addresses" for each specific piece of information.
In this age of "digital", business professionals need to understand how to create good taxonomies that provide these important identifiers. All too often, business professionals tend to confuse the following three distinct, different things:
- Notion, idea, phenomenon: something that exists in reality.
- Name: identifies some notion/idea/phenomenon.
- Preferred label: alternative ways used to refer to name.
The importance of quality identifies or "handles" or ways of addressing information correctly is hard to over-state. In an article they published, Barcodes of Finance, Allan D. Grody and Peter J. Hughes, explains the importance of these sorts of identifiers.
"Unique and standard identifiers, and standard data sets accessible by computer means through a tagging convention for both is the pre-requisite for financial stability objectives of the regulators. It is also a pre-requisite for fulfilling the promise of real-time straight-through-processing, significant infrastructure cost reduction and operational risk mitigation made to the industry by regulators."
In a webinar (about an hour in length) of the same name, Barcodes of Finance, Allan goes into details related to an initiative to create a global legal entity identifier scheme. The presentation helps you understand the importance of these identifiers and some of the work that is going on to create these identifiers for finance.
More information:
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
The XBRL Book: Technical, Simple, and Precise
Dr. Ghislain Fourny, a computer scientist for 28msec, has written a freely available book about XBRL oriented toward professional software engineers, architects, and developers: The XBRL Book: Technical, Simple and Precise.
Ghislain brief description of the book is:
Put simply, this book is the simple and precise starting point I wish I had had when I first encountered XBRL. Most of these pages do not require any XML or XML Schema knowledge, except for the one section in each chapter that goes into details about the syntax -- but the latter can easily be skipped on a first read.
If you want to see some of Ghislain's handiwork, check out SECXBRL.info.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding the Real Cause of XBRL-based Financial Report Quality Issues
In another blog post I explainedseven myths about quality issues related to public company XBRL-based financial reports submitted to the SEC.
So what actualy does cause quality issues? Based on measurements and testing that I have been doing for about five years, this is what I see from those measurements/testing. Below are common specific categories of basic errors that are still far too common:
- Using wrong concept: One common error is the public company simply using the wrong concept. For example, using the concept "us-gaap:AssetsNet" when the concept "us-gaap:Assets" should have been used as with this public company.
- Inappropriate extension concept: Creating and using an inapproprate extension concept is a common error. For example, creating an extension concept "jkdg:TotalAssets" like this filer did, rather than using the existing US GAAP XBRL Taxonomy Concept "us-gaap:Assets". Particularly if the filer (a) created an extension for a very high-level concept such as assets and (b) did not provide justification for the extension in the documentation they provide with the concept. NOTE: Not all extension concepts are inappropriate.
- Using a PART as a WHOLE; or WHOLE as a PART: A far less understood but common error is reversing the "PART" and the "WHOLE" of a part-whole relation. So for example, this filer provides an example of this. You may want to read the entire document to best understand the issue. A simple explanation of this issue is that the concept "Health Care Organization Revenue" is the grand total of all health care related revenue that an organization can have. But the filer used it as a PART of another revenue concept, thus a PART of the grand total is used as the WHOLE.
- Using a PART and a WHOLE together as PARTS: Again, less understood but a common error is where a PART and a WHOLE are both used as PARTS. Example #2 here in this document provides an example of this mistake. One of the two line items that are used to reconcile "Net income" to “Numerator for basic earnings per share” is the GRAND TOTAL into with the other concept is a PART. This is a logic error. Read the entire document to understand that specific error better.
- Reversing the polarity of a numeric value: Example #8 in this document shows where a filer puts in a negative value, then negates the label so it renders as a positive; but should have simply entered a positive value to make the math of the relations work correctly. Reversed values are each to catch because the amount of the error is double the amount of the value. Accounting trick!
There are many, many other categories of errors in XBRL-based financial reports. While manual effort can detect these sorts of errors, and others; automated machine-based processes tend to be more reliable. With all the details contained withing an XBRL-based financial report, it is very hard to do without automated processes. While it is not the case that all verification can be automated, a good portion can.
Good processes lead to quality levels already achieved by Google and Apple. Go back and have a look at this blog post to see the ramifications of not having good processes.
For more information about errors and how to correct them, please use visit this resource.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Public Company Quality Declines Slightly, but Generator High Reaches 97%
The quality of XBRL-based public company financial reports as measured using a set of fundamental accounting concept relations declined slightly, but one generator reached the point where 97% of all their customer digital financial reports were completely consistent with that measure.
Here is the summary:
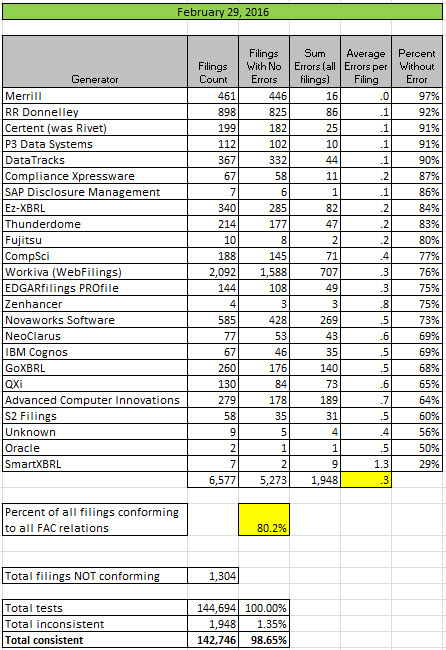 (Click image for larger view)
(Click image for larger view)
What seemed to cause the slight decline in overall quality was the fact that many 10-K reports were submitted to the SEC this past month. Filing agents and software vendors seem to use different report templates for a 10-K and 10-Q report. Those different templates seem out of sync and errors creep into the 10-K that did not exist in the 10-Q. Another problem is that information from the disclosures in a 10-K which is more comprehensive than a 10-Q conflicts with information represented in the primary financial statements. These sorts of inconsistencies look like the following when you compare quality results across filing periods:
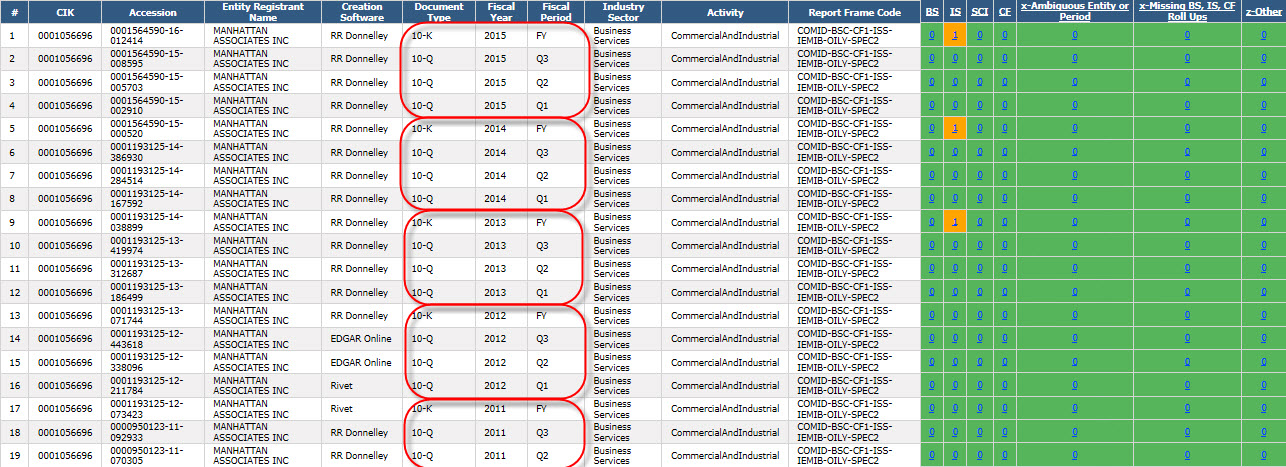 (Click image for a larger view)
(Click image for a larger view)
There is another trend which is very, very positive. Some public companies have the same inconsistency period, after period, after period. Lots of these long-standing inconsistencies are being fixed. Here are three examples of this. What you see is a list of XBRL-based public company filings in descending order. GREEN means no inconsistencies (a good thing), and ORANGE means that an inconsistency exists.
Alaska Airlines: (Notice the same inconsistency in EVERY prior filing, but the latest filing corrects that long standing inconsistency)
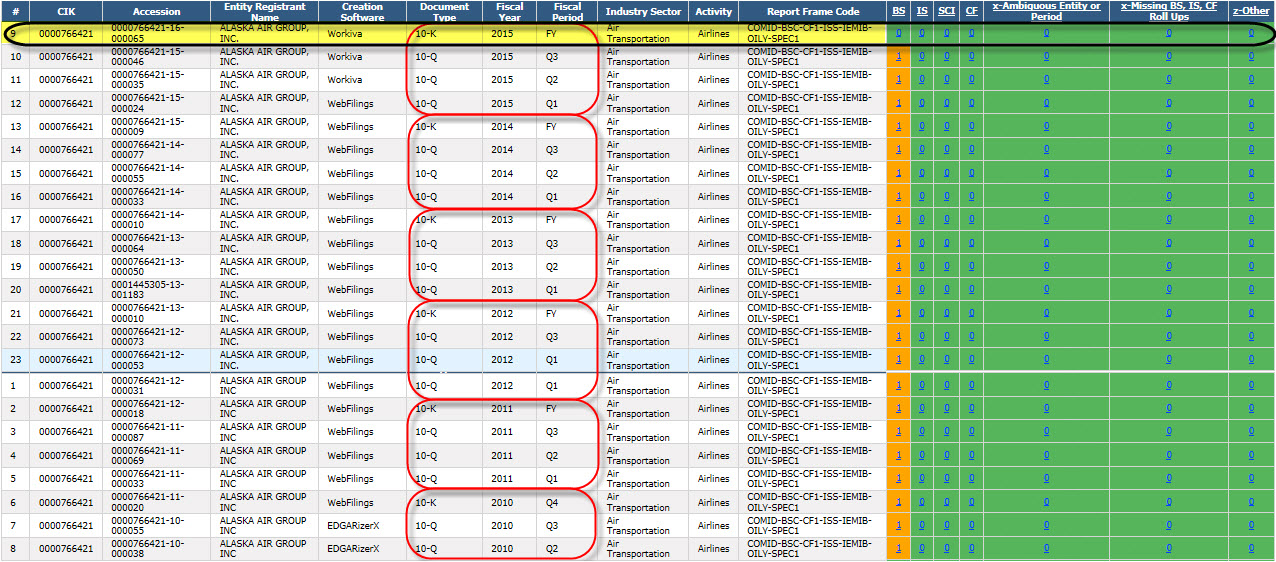 (Click image for larger view)
(Click image for larger view)
Verizon: (Notice how Verizon had no inconsistencies, then some inconsistencies creep in, then they were fixed, then some more crept in, then another inconsistency, and ultimately all inconsistencies got fixed)
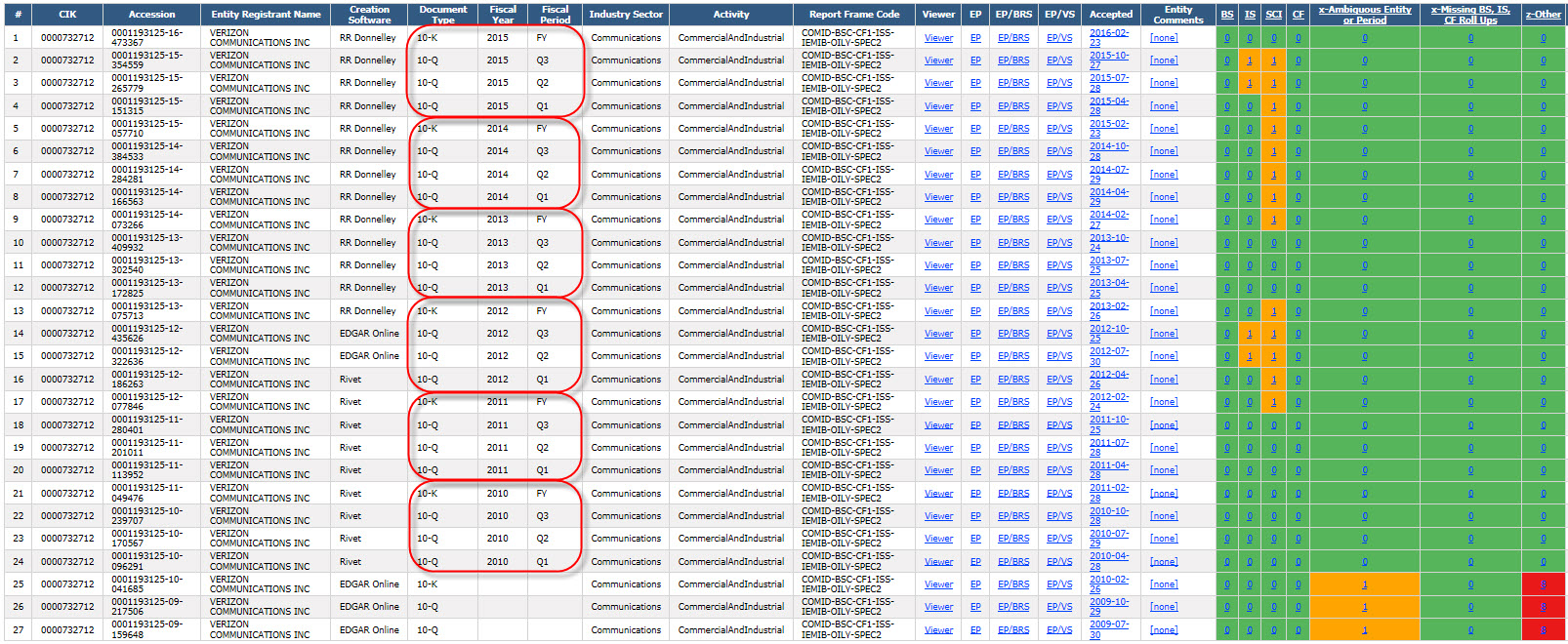 (Click image for a larger view)
(Click image for a larger view)
Boeing: (Note that Boeing had TWO inconsistencies, but only fixed ONE of them; so one inconsistency remains)
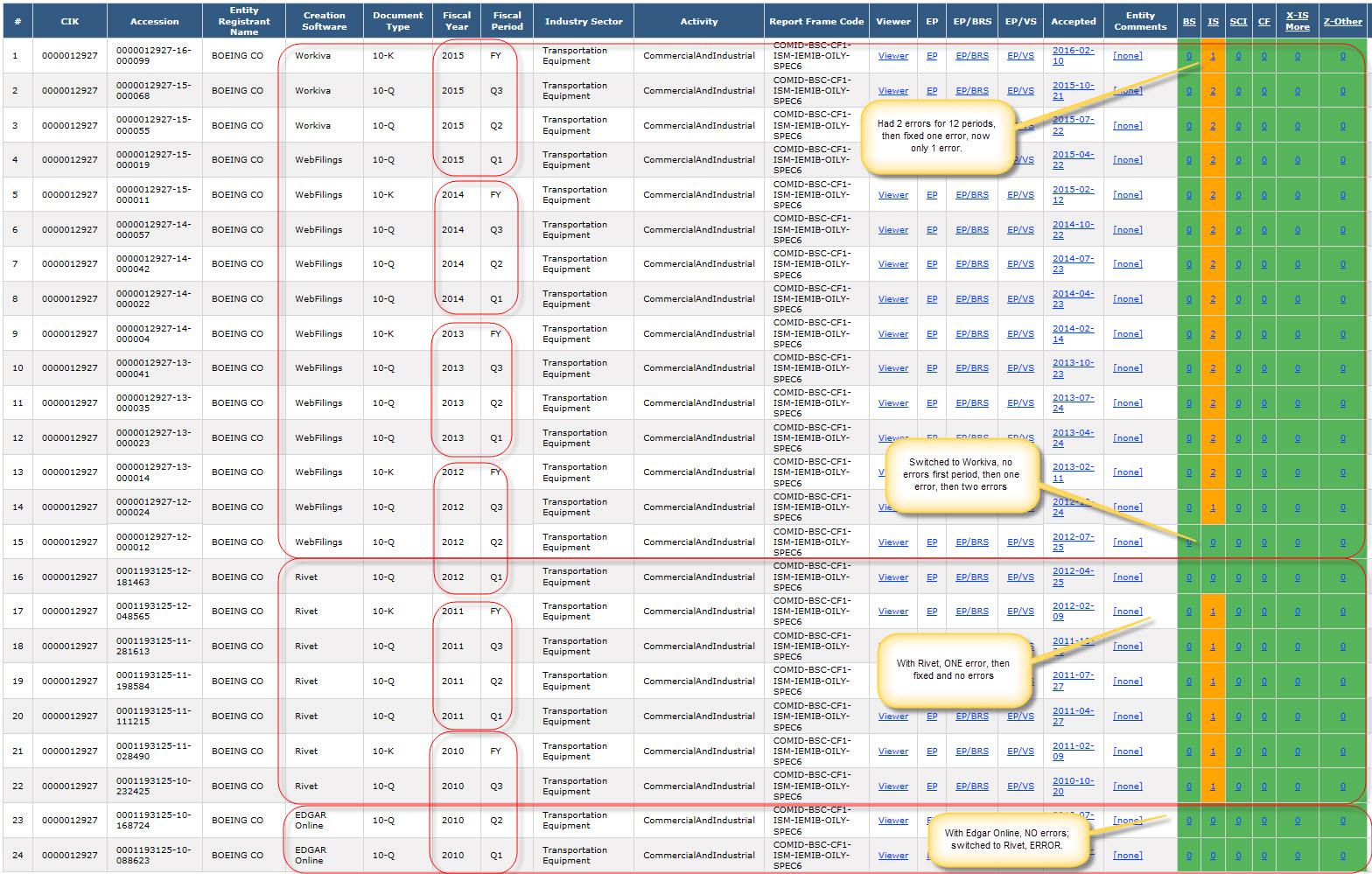 (Click image for a larger view)
(Click image for a larger view)
IBM: (This shows a lot of fluctuation and therefore it is unlikely automated processes are being used to watch over this financial filing)
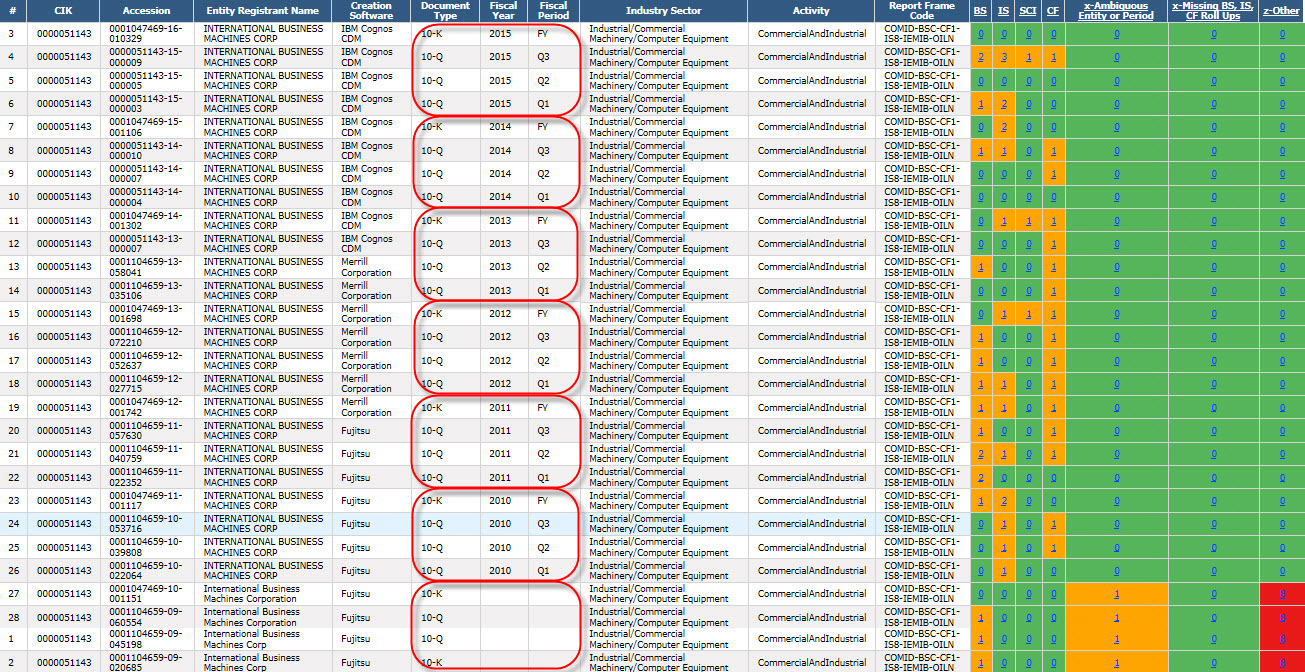 (Click image for larger view)
(Click image for larger view)
Can public companies get their XBRL-based digital financial reports dialed in? Of course they can. Look here at Google's, Apple's, Walker & Dunlap history; each has always been 100% consistent with the fundamental accounting concept relations. Quality is measurable.
What is the holy grail of verification to help public companies dial in their XBRL-based digital financial reports? Well, this is some brainstorming that I have done as to that holy grail.
If you look at those screenshots you can see how easy it is to see if an inconsistency exists and then take steps to fix the inconsistency. Filing agents and software vendors that cannot manage quality have process/system problems.
This narrative describes the prototype that I created and has links to the minimum criteria that I use to evaluate the fundamental quality of XBRL-based digital financial reports.
So Merrill has achieved a level of 97% quality. Their quality improved while the quality of most other generators (filing agents, software vendors) declined. They did not seem to be impacted by the 10-K/10-Q synchronization issue. Merrill seems to be fixing not only filings, but their entire process.
* * *
Previous fundamental accounting concept relations consistency results reported: January 31, 2016; December 31, 3015; November 30, 2015; October 31, 2015; September 30, 2015; August 31, 2015; July 31, 2015; June 30, 2015; May 29, 2015; April 1, 2015; November 29, 2014.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

