BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from May 1, 2015 - May 31, 2015
Introducing the Digital Financial Report Explorer (Beta)
The Digital Financial Report Explorer (Beta) is a Microsoft.Net software platform for working with repositories of financial information. You can download an explore a version of this platform which works as n Excel add-in. The application has been tested with Excel 2010 and likely works with Excel 2013 but has not been tested as well using that version.
The Digital Financial Report Explorer was created by Hamed Mousavi, a software developer, and myself. The platform provides general functionality to query a financial information repository filled from XBRL-based financial report information. Currently, two repositories are supported: SECXBRL.info and EDINET.info both provided by 28msec. Support is planned for other information repositories including XBRL Cloud's EDGAR Report Information REST Web Service.
To download and try out the Digital Financial Report Explorer (Beta) for free, please do the following:
- Close Excel.
- Uninstall any prior versions of the Digital Financial Report Explorer you have installed. (Control panel, Programs and Features)
- Download and then run this Microsoft Installer which will install a new Excel add-in.
- After the installer as completed, the add-in is now assailable for use.
The Digital Financial Report Explorer adds a new tab to the toolbar ribbon called "DFR Explorer":
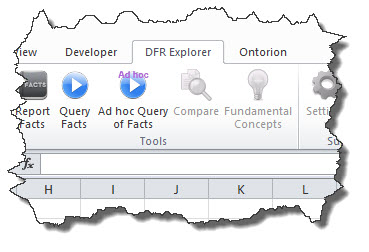
You don't need to get a SECXBRL.info authorization token, the application provides a default authorization token complements of SECXBRL.info. However, if you register with SECXBRL.info, you can have complete access to all financial information in the repository for commercial or noncommercial use. If you have troubles getting an access token, use this token (copy and paste it into the application):
c3049752-4d35-43da-82a2-f89f1b06f7a4
Using the application is rather straight forward. The information below will help you understand the capabilities of the application:
Login to multiple repositories: This may seem simplistic, but this really is a big deal. You will be able to log into the repositories of any number of software vendors that provide financial repository information. This leverages the global standard nature of XBRL. Not only that, but imagine being able to login to multiple repositories at the same time and then be able to query across repositories using a single user interface! That aspect is coming soon.
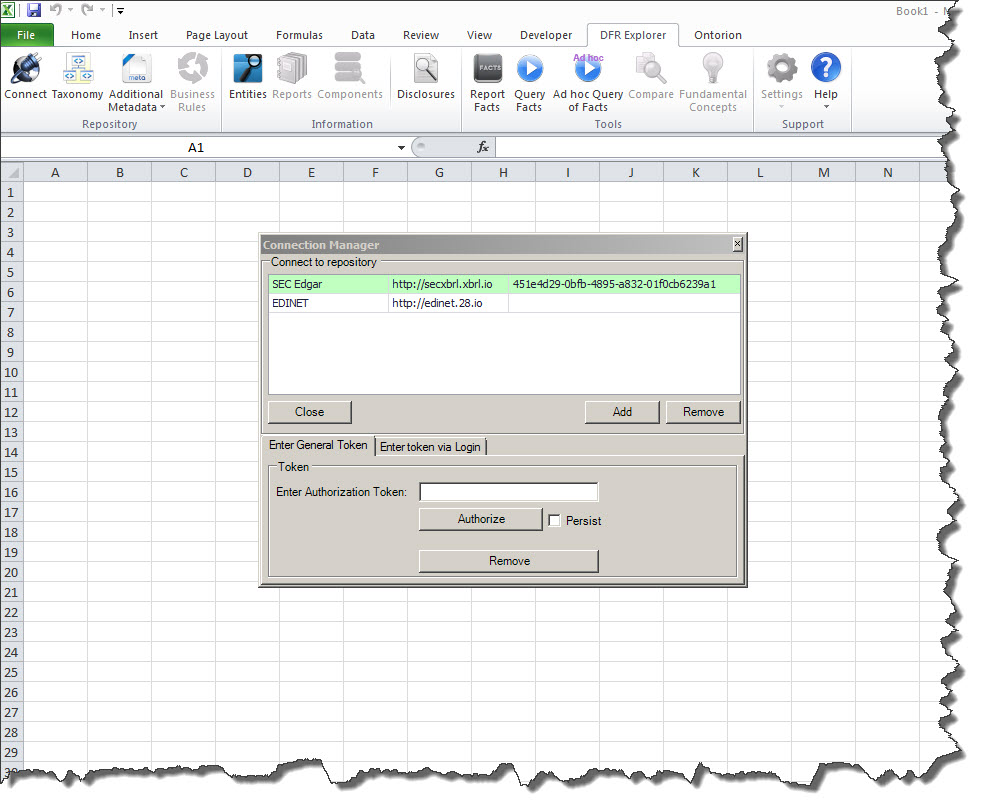 (Click image for larger view)
(Click image for larger view)
Repository metadata: Work with repository metadata. This is not just metadata provided by the XBRL-based financial report. While that metadata is provided, additional metadata and meta-metadata is provided. Be sure to check out the Taxonomy icon, the Additional Metadata Icon, and the Business rules icon (coming soon), and the filtering capabilities that help you sort through all that metadata:
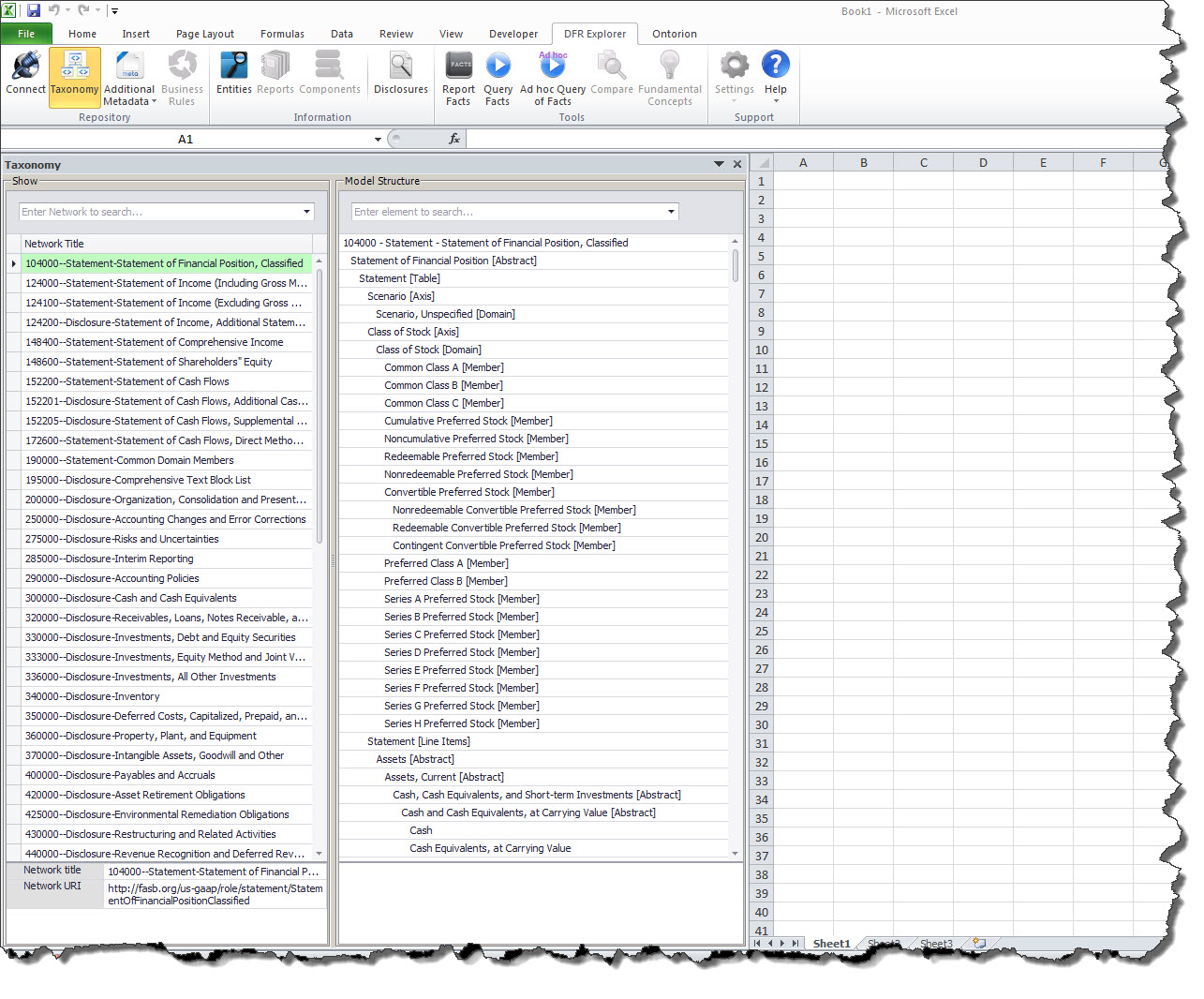 (Click image for larger view)
(Click image for larger view)
Entity perspective: You can look at information from the perspective of a reporting entity. Again, all public companies that file a 10-K or 10-Q are available from SECXBRL.info.
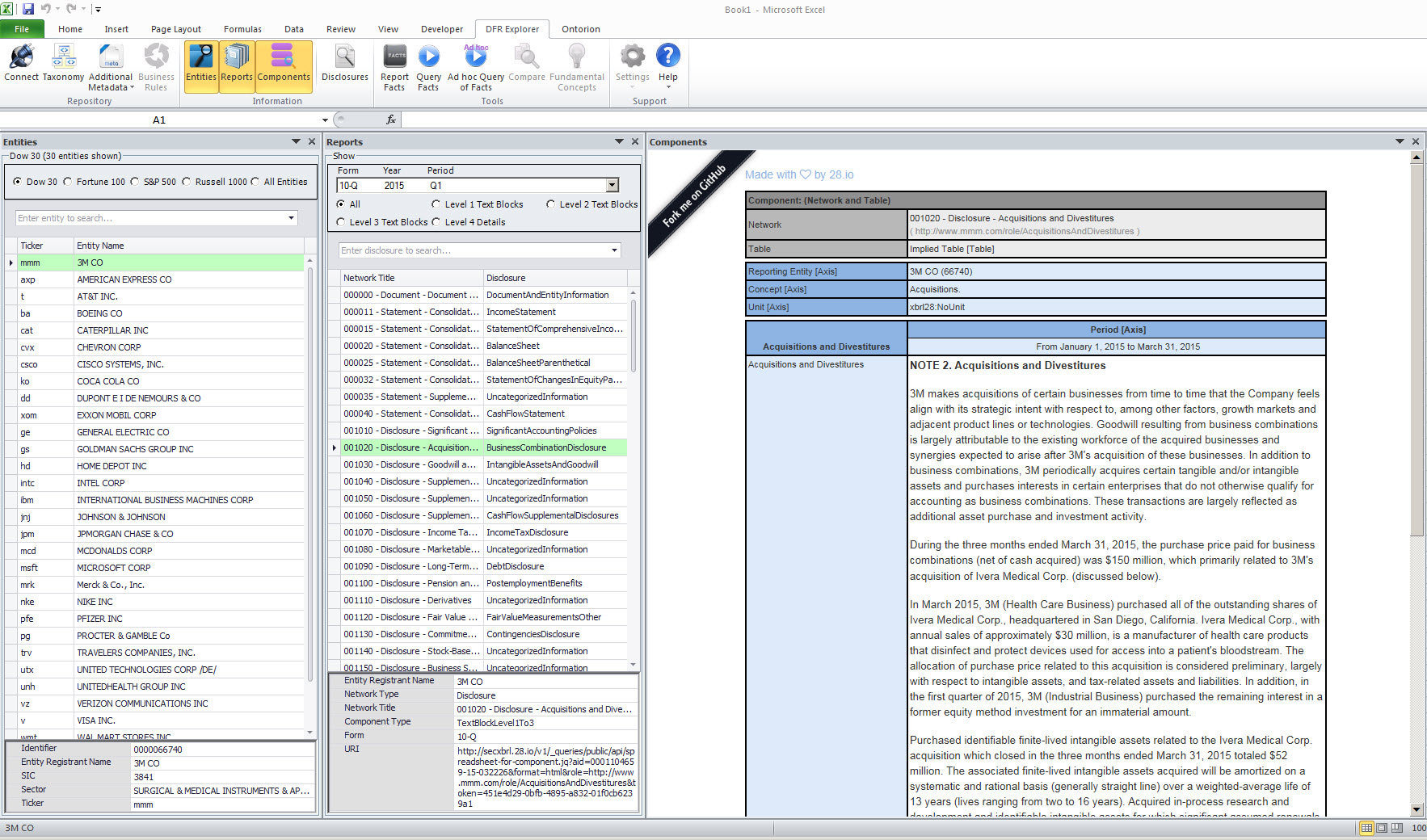 (Click image for larger view)
(Click image for larger view)
Disclosure perspective: Where the application becomes very interesting is when you start querying for components of a of a financial report across many financial reports. For example, compare how different public companies provide the same disclosure using this functionality:
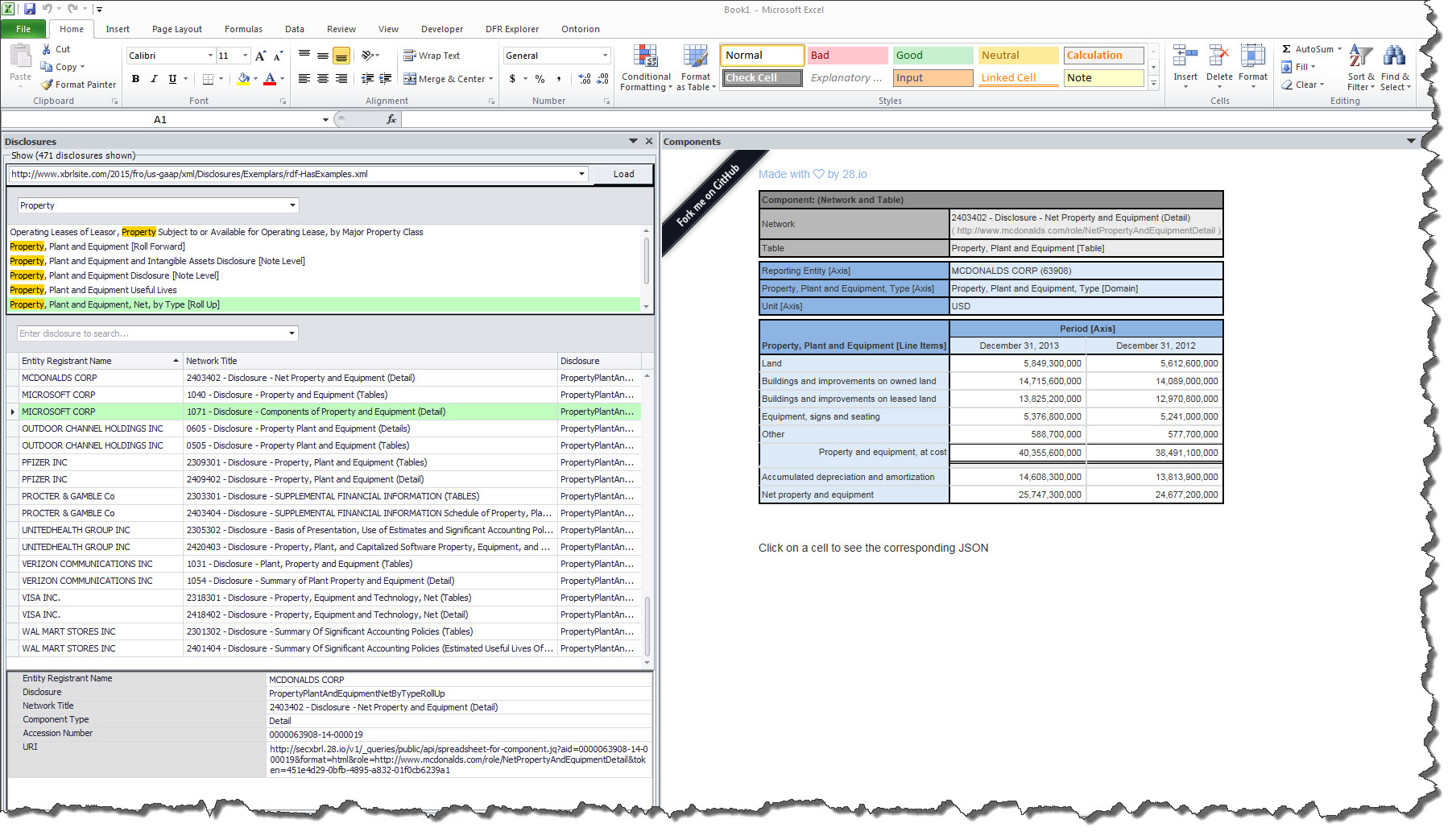 (Click image for larger view)
(Click image for larger view)
Report library and Query library: Create and maintain your own library of reports or library of queries. You can exchange entire sets of queries using standard RSS library formats. You can not only run queries and reports within the application, but you can copy and paste the link to a report or query into an email, web site, or other location.
Ad hoc Query, load results into Excel: Using the functionality of the SECXBRL.info platform (i.e. we did not build this ourselves, we are leveraging the platform) you can load any information you desire into Excel. We provide fact-type queries which you can use for experimentation:
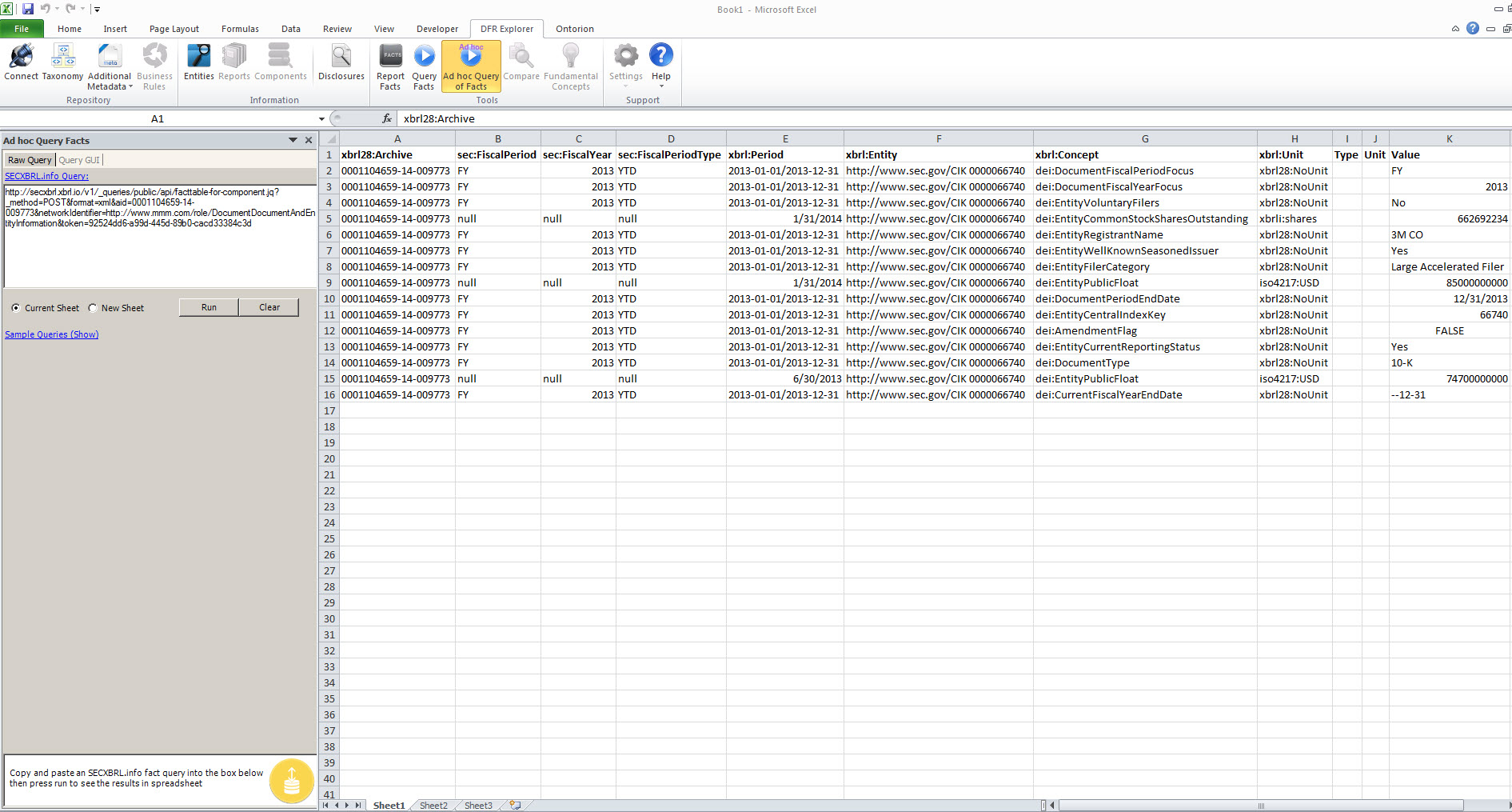 (Click image for larger view)
(Click image for larger view)
Remember, the Digital Financial Report Explorer (Beta) is more of a demonstration of what is provided by the SECXBRL.info repository platform and the Microsoft.Net components used to create the Digital Financial Report Explorer itself. You can create your own products in a fraction of the time and expense.
And this is only the start. There are many, many additional high-level components on their way. To get a better understanding of what all this means, be sure to read through these resources which helps you understand new capabilities that are coming to financial report creation and financial information consumption software.
Don't make the mistake of thinking that you have to build everything from scratch yourself. Let the platform take care of the hard work, you do the rest to add real value. Digital isn't software, is a mindset! Create stories which show information from a financial report across reports.
Any set of concepts that you want for any periods that you want.
Basic sets of concepts. Or come up with your own interesting combinations! Change the format from JSON, to CSV, to XML, to HTML.
Got any good ideas you want implemented? Send them our way.
 Charlie
in Demonstrations of Using XBRL
|
Charlie
in Demonstrations of Using XBRL
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Brazil's XBRL Study Group
An XBRL study group in Brazil has organized it's information about XBRL into an XBRL Framework.
As I understand it, this study group is led by professor Dr. Paulo Silva who is also a financial analyst of the Centeral Bank of Brazil. The focus of the group is XBRL computer projects which have been developed by master and doctoral students. All projects and scientific papers are free and open source and our scientific paper.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding the Law of Conservation of Complexity
A kluge, a term from the engineering and computer science world, refers to something that is convoluted and messy but gets the job done.
Anyone can create something that is complex. But it is hard work to create something that is simple. As Steve Jobs put it, creating something that is simple and elegant to use is the ultimate sophistication.
"It takes a lot of hard work," Jobs said, "to make something simple, to truly understand the underlying challenges and come up with elegant solutions." As the headline of Apple's first marketing brochure proclaimed in 1977, "Simplicity is the ultimate sophistication."
Simplistic is dumbing down a problem in order to make the problem easier to solve. Simplistic ignores complexity in order to solve a problem which can get you into trouble. Simplistic is over-simplifying. Simplistic means that you have a naïve understanding of the world, you don't understand the complexities of the world. Removing or forgetting complicated things does not allow for the creation of a real world solution that actually work.
Simple is something that is not complicated, that is easy to understand or do. Simple means without complications. An explanation of something can be consistent with the real world, consider all important subtleties and nuances, and still be simple, straight forward, and therefore easy to understand.
Complexity can never be removed from a system, but complexity can be moved. The Law of Conservation of Complexity states:
"Every application has an inherent amount of irreducible complexity. The only question is: Who will have to deal with it-the user, the application developer, or the platform developer?"
Another version of the law of conservation of complexity:
"Every application has an inherent amount of complexity that cannot be removed or hidden. Instead, it must be dealt with, either in product development or in user interaction."
Irreducible complexity is explained as follows: A single system which is composed of several interacting parts that contribute to the basic function, and where the removal of any one of the parts causes the system to effectively cease functioning.
So for example, consider a simple mechanism such as a mousetrap. That mousetrap is composed of several different parts each of which is essential to the proper functioning of the mousetrap: a flat wooden base, a spring, a horizontal bar, a catch bar, the catch, and staples that hold the parts to the wooden base. If you have all the parts and the parts are assembled together properly, the mousetrap works as it was designed to work.
But say you remove one of the parts of the mousetrap. The mousetrap will no longer function as it was designed, it will not work. That is irreducible complexity: the complexity of the design requires that it can't be reduced any farther without losing functionality.
As pointed out in the document Understanding Blocks, Slots, Templates, and Exemplars, technical details can be hidden from business professionals using clever techniques. Coming up with the clever techniques can be a challenge. But the payoff is simplicity and elegance.
For example, the notion of a fact table explains the interaction between networks, hypercubes or [Table]s, dimensions or [Axis], [Member]s, primary items or [Line Items], [Abstract]s, and Concepts. As pointed out in an analysis of 6,751 XBRL-based financial reports submitted to the SEC,
- 99.9% of public companies consistently follow the structural relations between these report elements (Networks, [Table]s, [Axis], [Member]s, [Line Items], [Abstract]s, Concepts
- 98.7% follow a set of fundamental accounting concepts and relations between those concepts, that percentage continues to push toward 100%
- 100.0% of the pieces of a financial report are identifiable as either a
- roll up (about 16%),
- roll forward (about 5%),
- text block (about 54%)
- hierarchy (about 24%)
Not a lot of software products are leveraging this information, but the number is slowly increasing. Once software developers figure out how to leverage this information, business professionals will begin to see the power of digital financial reports.
Simple is elegant!
Elegant: Characterized by highly skilled or intricate art, tasteful beauty of manner, form, or style; excellently made or formed; simple and clever.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Public Company XBRL-based Digital Financial Report Quality Continues to Improve
The quality of public company XBRL-based financial reports submitted to the SEC continues to improve. The last measurement of a specific set of fundamental accounting concept relations showed that 58% of all such public company financial reports were consistent with expected basic accounting relations. That consistency rate has increased 5% to 63%. The average number of inconsistencies per financial report (for my set of relations) has decreased from .7 per report to .6. The total number of inconsistencies dropped by 626.
This is the summary of information by software vendor and/or filing agent (generator):
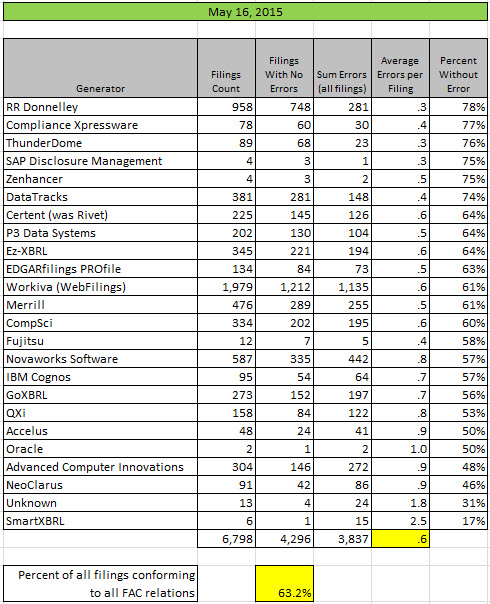 (Click image for larger view)
(Click image for larger view)
There were 11 software vendors/filing agents that had a 5% increase in quality or greater as compared to my prior analysis in April 2015.
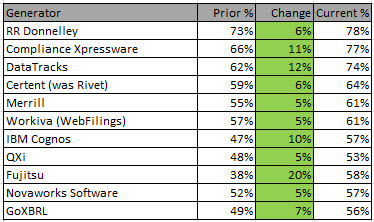
This graphic shows comparison information for the 2013 10-K season, the 2014 10-K season, and this most current analysis:
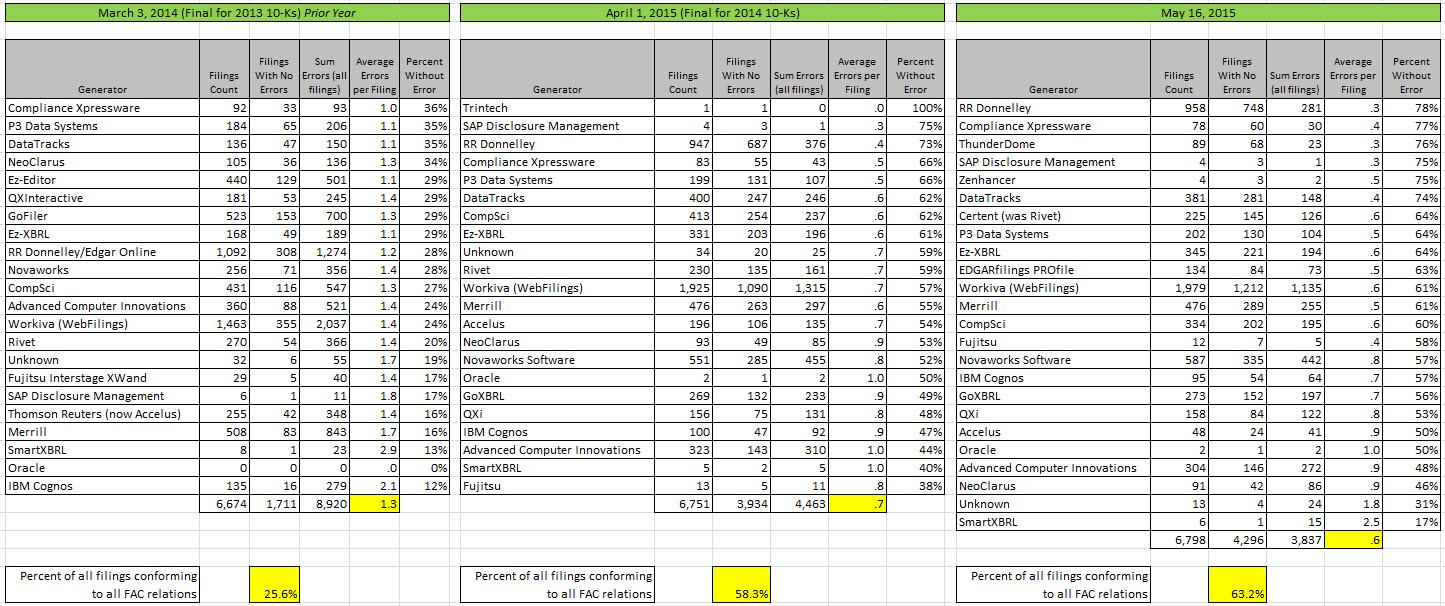 (Click image for larger view)
(Click image for larger view)
Competition is a good thing. Public companies have plenty of options when it comes to software vendors and/or filing agents for helping them create their digital financial reports. These choices will help push quality even higher, I believe, and will help the financial reporting supply chain achieve what other domains such as health care and electronic medical records are trying to achieve.
Want to understand how to improve your consistency with these basic fundamental accounting concept relations? This chapter of Digital Financial Reporting provides information about the fundamental accounting concepts. This page on my blog provided very detailed information on these accounting relations. If you want to understand the bigger picture, I suggest these two resources: Digital Financial Reporting Principles and Knowledge Engineering Basics for Professional Accountants.
I will measure quality again in three months. I predict that there will be another healthy increase in quality, that over two thirds of all public company XBRL-based financial filings to the SEC will be consistent with all of these basic accounting relations, and that at least four software vendors/filing agents will have 80% of their financial filings or more completely consistent with these basic accounting relations.
Charlie
in Creating Investor Friendly SEC XBRL Filings
|
Post a Comment
|
 4 References
| Email
| Print
4 References
| Email
| Print
Understanding Cognitive Computing's Impact on Financial Reporting
The article, What is cognitive computing? IBM Watson as an example, says that cognitive computing is the third era of computing:
If we consider that the first era of computing that the one of tabulating systems (1900), the 2nd the one of programmable systems (1950), cognitive computing is the 3rd era of computing.
It is a mistake to overstate the capabilities of something. It is likewise a mistake to understate the capabilities of something. Philosophers, theologians, and academics like to debate things simply for the sake of the debate. Business professionals, me included, tend to take a different approach. We like to use practical tools that actually work. Me personally, I don't see a computer having a conscience any time soon.
People love buzz words. Early in my career one buzz word was "client server". Few people seemed to know what client server was, but everyone felt they needed one. Artificial intelligence has been a buzz word for quite some time. Some of today's buzz words are: Big data. Smart data. Smart machines. There are even people who track buzz words. I tend to take this persons view on buzz words:
Not all buzzwords are bad. Some actually convey an idea, a concept, or a valid technology. However, some exist to confuse, distort, and empower those who don't want you to know what they're talking about.
Many people tend to miss a really important point when it comes to XBRL. They look at XBRL as "tagging" and they equate XBRL to the "barcode". But, turn the equation around. What would it mean if all financial information were properly bar coded? What could you do? What would that enable?
Think about this: What would happen if you took financial reports and rather than reporting information in an unstructured format that only machines could understand (because the information is unstructured or more accurately structured for presentation); but rather reported information was in a structured format both humans and machines could read and understand? What exactly would that mean?
Well guess what. We will get a chance to see exactly what that means. Financial information is being reported to the SEC by public companies in the structured format XBRL. The quality of that information is being dialed in. Professional accountants are understanding more and more about how digital works. Professional accountants are building prototype financial report ontologies and suggesting how ontologies can be used to improve financial reporting. Professional accountants are coming up with ways to work with technical artifacts so that they can employ these useful technologies on their terms.
Cognitive computing is the simulation of human thought processes in a computerized model.
Notice the word simulation. Computers cannot think, they are dumb beasts. But these dumb beasts can be made to mimic the human thought process, if you understand how to harness the power of a computer. (If you don't understand what it takes to harness the power of a computer, read Zeroing in on the Holy Grail of Global Standard Financial Reporting.)
Computers do not create the magic. Skilled craftsmen who wield their tools effectively are what create the magic. Computers simply follow instructions.
This article, Cognitive Computing And Semantic Technology: When Worlds Connect, points out something that is really important in two key statements in that article:
Statement #1:
For cognitive computing to achieve its promise we need a thick metadata layer that incorporate semantic tagging formats.
Statement #2:
A lot of the focus is on machine learning, especially as things move to really analyzing and building explicit knowledge models, but other areas that should be included in the cognitive computing mix include constructive ontologies and constructive knowledge modeling, whether it's done by groups or individuals or crowd-sourced in the case of the semantic web.
So, what is not in dispute is the need for a "thick metadata layer" in order for the computer to be able to perform useful work. But what is sometimes disputed, it seems, is HOW to get that thick metadata layer. There are two basic approaches:
- Have the computer figure out what the metadata is: This approach uses artificial intelligence, machine learning, and other high-tech approaches to detecting patterns and figuring out the metadata.
- Tell the computer what the metadata is: This approach leverages business domain experts and knowledge engineers to piece together the metadata so that the metadata becomes available.
Now, I understand many things about how computers work. Not remotely everything, but a lot. If there is an error in my understanding of what computers can achieve, it would tend to under estimate what they can achieve rather than over estimate.
As a professional accountant, I understand that the probability of a computer starting from scratch and using the most sophisticated technologies and approaches available today and creating any useful metadata is very close to zero. However, the more manually created metadata that a computer has to work with, the higher the probability that the computer would be helpful in correctly figuring out financial reporting metadata.
So what I am saying is that humans are going to have to prime the pump and get quite a lot of metadata pieced together. Then at some point and for some things, computers can effectively be used to contribute more metadata. And so, this is not an either-or question. Both approaches can be used effectively and contribute to what is needed to realize the potential offered by cognitive computing. I am also saying that there are no short cuts.
Can cognitive computing work and have an impact on financial reporting? No doubt. Work practices of professional accountants will be changing over the coming years in very big ways. 1 year? 5 years? 10 years? 15 years? Hard to say. So keep Gartner's Hype Cycle in the back of your mind.
Computers assisting professional accountants in correctly representing financial reports digitally will cause high-quality financial information to be available for analysis by investors and regulators. Everyone in the financial reporting supply chain will benefit from the meaningful exchange of financial information in machine-readable formats.
XBRL was never about "tagging" or "barcodes". XBRL is about all the possibilities that are enabled if information can be successfully exchanged between business systems. While financial reporting is leading the way, in particular XBRL-based financial reporting by public companies to the U.S. Securities and Exchange Commission, other reporting schemes will likely benefit from the SEC's bold experiment. Business professionals will build their own Watson-type systems for way less than what IBM paid to build Watson.
Concept computing will contribute to changing how financial reports are created similar to how CAD/CAM contributed to how blueprints are created and how the design supply chain interacts.
Charlie
in Digital Financial Reporting
|
Post a Comment
| Email
| Print

