BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries in Business reporting logical model (5)
Consistent Semantics Leads to Automated Renderings Across XBRL Taxonomies
A number of years ago after a meeting at the XBRL International Conference in Tokyo where I was showing some things I was working on to Geoff Shuetrim and Rene van Egmond, Geoff made the statement, "Charlie, you are like a guy who is trying to escape from prison using a teaspoon."
I am not sure if that was meant as a complement, but that is the way I took it. I have been trying to achieve something for, I don't know, three or four years and I have finally reached my goal!
The goal was to render the information contained within an XBRL instance in a human readable format given any XBRL taxonomy.
The journey included rendering a complete IFRS financial report of a Singapore company, the Deloitte model IFRS financial report, modeling the some 28 business reporting patterns I had pulled from those and other such financial statements, modeling the 29 USFRTF patterns document patternsused to understand how to create the US GAAP Taxonomy, re-modeling the USFRTF patterns into XBRLS business use casesin order to overcome issues discovered with the USFRTF patterns. Each of these contains a rendering, and each of the renderings was generally created by hand coding an XSLT style sheet.
I have one final iteration of these business use cases to create. I want to model the business use cases I have been collecting (really financial reporting use cases) using the Business Reporting Logical Model. I have created one use case already, the "Simple Hierarchy" which you can see below. The others will follow.
The difference is that I will not code these renderings by hand, they will be 100% automated. I already have the process in place, it works, as can be seen from the renderings below.
How do you do this?
The following things are needed to automate renderings and generate something useable by humans:
- You have to have a good information model, i.e. a good XBRL taxonomy. It has to be consistent. That is the starting point. If the model is inconsistent or fundamentally broken, you will never achieve your result.
- Your XBRL processor has to ouput two consistent info sets. In the Business Reporting Logical Model the two sets are the Fact Groups and the Measure Relations. (See the link above to understand this.
- The semantics of the XBRL taxonomies need to be aligned.
Note that the first two have huge benefits, even if your semantics are not aligned. As long as the XBRL taxonomy is internally consistent, any XBRL instance can be reduced down to these two fundamental pieces: fact group and measure relations as they are called in the Business Reporting Logical Model. You can call them anything you want, but you will need them. XBRL Cloud, who helped by generating these in its format call them fact tables (here is a human readable version) and a logical model.
Again, let me repeat. 1 and 2 above is all you need for one taxonomy to work. To have interoperable taxonomies you need number 3. That is provided by the Business Reporting Logical Model: aligned semantics.
Two Messages
There are two messages here.
First, XBRL already HAS a logical model, but most people cannot see it. This is shown by the fact table created by XBRL Cloud, or at least you can get a glimpse of that model. Into that model will fit items, tuples, XBRL dimensions, typed dimensions, custom created segment and scenario metadata, etc. This is an epiphany for me, I never really realized this. This is good because at a technical level, this provides very substantial leverage.
The second message is that there has to be some mapping between the XBRL syntax used and the semantics expressed. If this is achieved you get leverage across taxonomies and business users can make use of the functionality of these very technical tools without the need for help from the IT department.
The bottom line is this: I had always thought that XBRL's flexibility was the real problem. That is not the problem. The problem is the inconsistent use of semantics within and across XBRL taxonomies. This is generally unconscious by most of those who create XBRL taxonomies because they tend to not understand how XBRL works.
My Automated Renderings
Here are the automated renderings I was able to generate. I will have more information later, there is a lot of stuff going through my mind as a result of going through this exercise.
The really good news is that teaspoon enabled my escape from the XBRL prison I have found myself in for the past 10 years, literally. I am really seeing some things in a very new light. More to come, stay tuned. I see some very significant positive implications.
Here are my renderings. Notice that this is a number of different XBRL taxonomies, each complying with the Business Reporting Logical Model:
Business Reporting Metapatterns (basic components of the business use cases):
- Sales Analysis, Summary:
- Sales Analysis, by Business Segment:
- Sales Analysis, by Geographic Area:
- Accounting Policies:
- Property, Plant and Equipment; by Component:
- Roll Forward of Land: (This rendering is not really acceptable, but it is readable. A better rendering algorythm and format is needed for this type of information model. I know what it should look like, just have not done the programming yet.)
- Director's Compensation:
State Fact Book:
- Population Trends:
- General Information for Period:
- General Information at Point in Time:
- Financial Information, by State:
- Financial Information, by State, Alternative Aggregation of Expenses:
Business Reporting Use Cases: (This is only the first of 28 business use cases which I will eventually create)
Transaction Use Cases: (This is a prototype I built for someone else which uses their dimensions but builds upon the Business Reporting Logical Model.)
- Demo Transaction: (Note that this had two typed measures)
 Charlie
in Business Reporting Logical Model, Business reporting logical model, General Information, Modeling Business Information Using XBRL, US GAAP Taxonomy, XBRL General Information, XBRLS
|
Charlie
in Business Reporting Logical Model, Business reporting logical model, General Information, Modeling Business Information Using XBRL, US GAAP Taxonomy, XBRL General Information, XBRLS
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Business Reporting Logical Model Enhances Comparability and Interoperability
Another thing that the Business Reporting Logical Model does is enhance comparability and interoperability. Or to be more precise, the Business Reporting Logical Model minimizes the effort required to achieve comparability and interoperability. It opens the possibility of a business domain to create comparability, should they desire to do so. Interoperability means easier to use software and less costly software for business users.
Here is why.
Comparability
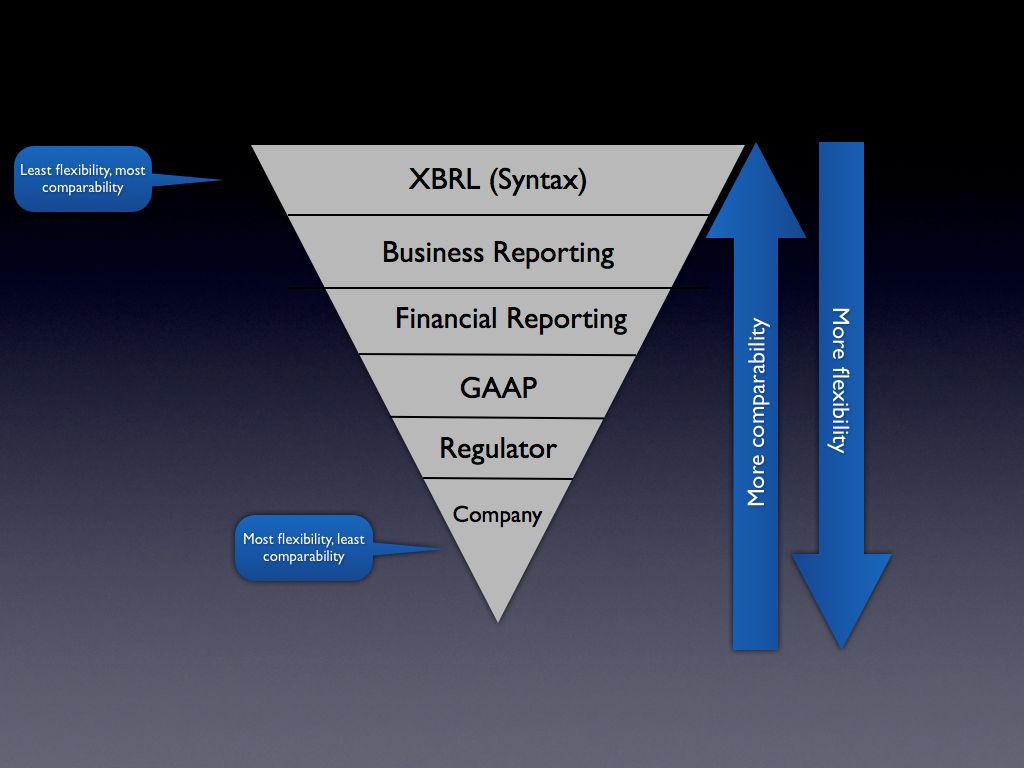
(Here is a link to a PDF of this graphic.)
Today, there is no logical model below the XBRL syntax level. The only model any business domain has to work with is the XBRL syntax or some model they create. Creating that model and all the infrastructure to enforce that model takes time and costs money.
Or, another way of looking at this is that each company desiring to use XBRL for, say, financial reporting could create their own model using XBRL. That model could be 100% XBRL compliant (i.e. comply with the global standard). Each company would have to deal with all the "stuff" in the middle such as which GAAP (accounting standards they would use), create their own XBRL taxonomy, and so forth.
The "middle ground" needs to be created. The US GAAP Taxonomy created some of this middle ground. You can see that middle ground in the US GAAP Taxonomy Architecture. But, the US GAAP Taxonomy is not enough. That is why the SEC had to create a boatload of additional EDGAR XBRL Validation tests (see this list of errors, here is the test suite). Of course, the SEC would probably never want XBRL International to deal with 100% that that specific regulator needs to deal with, nor would XBRL International members do that; it would be like everyone agreeing to do business reporting exactly like the SEC does it, that would become the XBRL standard.
Business information exchange is a balancing act. Where agreement is achieved has ramifications for business users. Too much flexibility has its issues, too much comparability (or requiring things too high in the stack) has its issues. Where comparability exists within the "stack" (the diagram above) is up to the business domain's implementation of XBRL. XBRL itself does not control this. How XBRL is used does.
Interoperability
There is another piece to this puzzle. XBRL is a standard. What a system needs to make business information exchange work properly, it seems to me, is a protocol. There is a difference between a standard and a protocol. A difference worth understanding. Erez Ascher (Ascher Consulting & Development) articulates the difference between a protocol and a standard as:
- A protocol is a series of prescribed steps to be taken, usually in order to allow for the coordinated action of multiple parties. In the world of computers, protocols are used to allow different computers and/or software applications to work and communicate with one another. Because computer protocols are usually formalized, many people consider protocols to be standards. However, such is not actually the case.
- Standards are simply agreed-upon models for comparison, such as the meter and the gram. In the world of computers, standards are often used to define syntactic or other rule sets, and occasionally protocols, that are used as a basis for comparison. Some good examples include ANSI SQL, used to compare derivations of the SQL database query language, and ANSI C, used to compare derivations of the C programming language.
In other words, it seems to me that protocols can be standards, but standards may not contain all that is necessary to "allow different computers and/or software applications to work and communicate with one another". Therefore, every business system, such as the SEC XBRL filings system, must add "stuff" to XBRL to turn the standard into a protocol it seems. For every system to have to do this is both inefficient and ineffective because you really don't get cross business system interoperability. What you get is what we have today - many point solutions or one-to-one integrations.
So not only does the Business Reporting Logical Model enhance comparability, it also enhances interoperability. The Business Reporting Logical Model can provide the pieces which can turn the XBRL standard syntax into a business reporting protocol. I am not sure if it is all the pieces, time will tell. But I am sure XBRL alone is not enough to give business users what they need from XBRL.
The Bigger Picture - Financial Reporting in the Age of the Semantic Web
There is a bigger picture here. Consider this blog post titled "Why the Semantic Web Will Fail". The post is pretty good, but what is really interesting are the comments to the post. The way I read that post and all the comments is that the Semantic Web is inevitable, but no one knows when it will arrive.
I contend that the Semantic Web is already here. The US Securities and Exchange Commission (every US public company financial in XBRL by July 2011), XBRL US (US GAAP Taxonomy), Tokyo Stock Exchange, Japan Financial Services Agency, Korean Stock Exchange, China Securities Regulatory Commission and Shenzhen Stock Exchange, Japan's EDINET, the Commission of European Banking Supervisors, the US Federal Deposit Insurance Corporation, the International Accounting Standards Board (IFRS, standardized financial reporting meta data expressed in the XBRL syntax) among others have already created pieces of it for financial reporting. The US SEC, Japan FSA, and IASCF are already reconciling their implementations of the XBRL standard to make them more interoperable. The Business Reporting Logical Model will make it so others don't have to go through this reconciliation process.
Is XBRL perfect? Certainly not. But XBRL is not RDF/OWL. Who cares, both XBRL and RDF/OWL are just syntax. On can convert from one syntax to another easy enough. The hard part, agreeing on the meta data and getting vendors to support the idea, is done (for US GAAP and IFRS). The IASB started on IFRS in the 1970's, even before the Internet existed. Most countries have either switched to IFRS already or will. Even if they all don't (i.e. the US will converge, but may not convert), reconciling US GAAP to IFRS is not that much of a challenge really. Oracle, SAP, and IBM all support XBRL within their software.
Maybe I am wrong, but it seems to me that a better question might be "When will others catch up to how the financial reporting business domain has embraced the Semantic Web?" That may by an over statement, financial reporting has a ways to go. The Business Reporting Logical Model will help others get into the Semantic Web easier than the early pioneers.
How did XBRL International get to where it is? Back in 2003 Joan Starr wrote an article Information politics: The story of an emerging metadata standard. Here is the article's abstract:
Information politics: The story of an emerging metadata standard by Joan Starr
This is the story of how one commercial metadata standard — XBRL, or Extensible Business Reporting Language — has attracted the participation and support of some of the world’s most powerful public and private organizations. It begins with a look at the nature and use of financial information in today's Internet-enabled environment and discusses three information use patterns: Transaction, retrieval, and reporting. While numerous, sometimes competing standards have been developed for transaction information, XBRL alone has emerged to address reporting formats. Today, the XBRL specification has wide support across the accounting, financial, and regulatory communities. This has come about largely through the efforts of the standards’ governing board, which has pursued a strategy of careful definition of market scope, deliberate courtship of important allies, and establishment of a culture of aggressive outreach for members. The results are impressive. Members of the organization are now positioned to take greatest advantage of a number of new entrepreneurial opportunities that have been created by the organization. Additionally, some participants are now representing the XBRL metadata standard as a key tool for the restoration of public confidence in the scandal-rocked accounting and investment industries. This may create a serious problem for researchers and investors as unaudited financial statements formatted in XBRL proliferate on the Web sites of corporations anxious to demonstrate a commitment to what some are calling "the new transparency."
XBRL seems to have achieved the right mix of technical and business participation. While what the technical people did was very good and very important, I think that what the business people who participated in XBRL created was perhaps even more important. Business users of XBRL should try and understand and push for the Business Reporting Logical Model to be standardized within XBRL International.
This will provide the flexibility where flexibility is needed, but also the things needed for a protocol to work well, be effective, and be efficient. Having every implementation of XBRL undertake this task will hurt XBRL, making comparability of XBRL based information more challenging and interoperability of XBRL software and different implementations near impossible.
So that is what I see. How do you see it?
Charlie
in Business Reporting Logical Model, Business reporting logical model, General Information, Modeling Business Information Using XBRL, XBRL General Information, XBRL and the Semantic Web, RDF/OWL, XBRLS, comparability
|
Post a Comment
| Email
| Print
Seeing the Benefits of the Business Reporting Logical Model
This post begins a series of posts where I point out the benefits of the Business Reporting Logical Model. If you are unfamiliar with the Business Reporting Logical Model, be sure to check out my straw man implementation of this model.
In my straw man implementation of the Business Reporting Logical Model, I created a prototype application in Excel called the "Hypercube Viewer" which allows you to extract and render XBRL instance information. The prototype application does not actually read XBRL, rather it reads an info set generated by an XBRL processor which supports the Business Reporting Logical Model. The prototype starts by reading an RSS feed which contains links to XBRL instances. My straw man implementation uses this RSS which points to two XBRL instances: ACME Company and Sample Company. Here are the info sets for those two companies:
- ACME Company: Fact Groups, Measure Relations, XBRL instance
- Sample Company: Fact Groups, Measure Relations, XBRL instance
If you follow my blog, you may have heard about the State Fact Book prototype which I had created to test some things. I created this prior to the Business Reporting Logical Model being available. I did use XBRLS in creating the State Fact Book which has many characteristics of the Business Reporting Logical Model.
What I wanted to do is refactor my State Fact Book XBRL example to use the Business Reporting Logical Model. To do that, I made two changes to my State Fact Book XBRL implementation. First, I corrected the data I was using to fix the error in the US Census Data which I had discovered and the Census Bureau subsequently adjusted. Second, I modified the State Fact Book taxonomy to use the Business Reporting Logical Model. I then generated the info sets for the three XBRL instances I was using which you can see here:
- Population Trends: Fact Groups, Measure Relations, XBRL instance
- General Information: Fact Groups, Measure Relations, XBRL instance
- Financial Information: Fact Groups, Measure Relations, XBRL instance
Next, I organized those three XBRL instances with the XBRL instances above into a new RSS feed which you can see here. This RSS contains all 5 XBRL instances, all created using the same Business Reporting Logical Model. I then pointed a new version of the Hypercube Viewer to that new RSS feed to see if the Excel application would read those new info set files generated by the XBRL processor.
After fixing a few bugs in the State Fact Book XBRL taxonomy and the application, my Excel application would read all five sets of information and render the sets consistently in the way I would have expected the information to be rendered. You should consider trying this for yourself.
For the intellectually curious who understand a little about Excel, you may want to consider reverse engineering the Excel application to create something which reads those info sets. In doing so you will realize the benefits of the consistency enabled by the Business Reporting Logical Model.
Even if the Business Reporting Logical Model never becomes an XBRL International standard, everyone creating an XBRL taxonomy will have to use something to ensure consistency in the XBRL taxonomies created. This is less important if you do not use taxonomy extensions, it is vital if you do allow extensions. Those creating extensions have to be guided to create extensions which are consistent with the taxonomy they are extending.
What I learned from this exercise is that some of the things I thought were important are not really important at all. I have always tried to keep taxonomies consistent by using the presentation linkbase. It is clear to me now that that is the wrong approach. I also thought that you would never get consistency unless you ditched a number of the pieces of XBRL such as typed members and tuples. That really is not necessary. You do need to control those pieces and others, but you don't necessarily need to ditch them all together.
Consistency is key. The Business Reporting Logical Model does allow for creating consistency. There are certainly other alternatives. While smart software engineers can figure out all the ins and outs of XBRL and generate an info set with information similar to the ones generated for my straw man implementation of the Business Reporting Logical Model, the "channeling" of XBRL syntax which the model does makes it significantly easer to process the XBRL syntax to generate that info set. Once you have the right info set, you can convert that into whatever syntax you might like. The syntax is really unimportant. It is the consistency of the business semantics which is important. The Business Reporting Logical Model is one way to achieve that consistently. There are others.
Charlie
in Business Reporting Logical Model, Business reporting logical model, Creating Investor Friendly SEC XBRL Filings, General Information, Modeling Business Information Using XBRL, US GAAP Taxonomy, XBRL General Information, XBRLS
|
Post a Comment
| Email
| Print
Business Reporting Semantics to SEC XBRL Implementation Mapping
In order to both test the Business Reporting and Financial Reportin Logical Models and demonstrate how to implement SEC XBRL filings using those models, I created a mapping from the logical models to the SEC XBRL implementation. You can get that mapping here. If you wanted to contrast that to the mapping of my straw man implementation, that mapping can be found here.
What is easy to see from the mapping I created is that it is very possible to use these logical models in creating SEC XBRL filings and their related XBRL taxonomies. What is harder to see is why that is beneficial. To see the benefits, one would need to use a software application which leverages the logical models, making it so you don't have to struggle with XBRL at the syntax level.
Charlie
in Business Reporting Logical Model, Business reporting logical model, Creating Investor Friendly SEC XBRL Filings, General Information, Modeling Business Information Using XBRL, US GAAP Taxonomy, US SEC, XBRL General Information, XBRLS
|
Post a Comment
| Email
| Print
Straw Man Implementation of Business Reporting and Financial Reporting Logical Models
As I have mentioned on a number of occasions, the XBRL International Taxonomy Architecture Working Group is working to create a business reporting and financial reporting logical model. I am part of that working group. It is my hope that XBRL International will make modifications to the next version of the Financial Reporting Taxonomy Architecture (FRTA) to address:
- interoperability issues between financial reporting taxonomies (i.e. why is the SEC, IASCF, EDINET having to reconcile their taxonomy architectures, the Interoperable Taxonomy Architecture Group),
- XBRL usability issues (i.e. XBRL is too hard for business users to use such as for SEC XBRL filings),
- system implementation issues (i.e. why can't the FDIC and the SEC XBRL implementations work together; why does the SEC have to write 400+ rules to implement XBRL within their system; why don't vendors agree on SEC XBRL error messages)
- software creation issues (i.e. why is it so hard for software vendors to create XBRL software which business users can actually use)
- taxonomy extension issues (i.e. why are SEC XBRL company extensions so inconsistent)
This blog post looks into possible future scenarios of XBRL adoption, taking the realities of the list above into consideration.
What more details about these sorts of issues and how to solve them? If so, you are in luck. I created what I am calling a straw man implementation of the business reporting and financial reporting logical models in order to both show the problems and why they are problems, and to show a solution to the issues outlined above. The straw man implemention also proves the issues are all solvable, showing specifically how to solve them.
Straw Man Implementation
Here is information about my straw man implementation:
- Overview: This is a good starting point, it provides an overview.
- Semantics to XBRL Syntax Mapping: This maps the logical model semantics to its XBRL syntax in my implementation.
- Processing Model: This shows the processing model or steps in working with the business reports.
I do realize that this is a lot of information. All this information is the first step in doing what I want to do. The next step is to take this detailed information and summarize it down to its essence in order to show business users why the efforts of the XBRL International Taxonomy Architecture Working Group to create this logical model are a good thing and why a global standard is better than the proprietary solutions to the XBRL issues (which I mentioned in this blog post) which will be created should XBRL International not address these issues.
As I see it, this is the future of XBRL, be it via a global standard (my preferred option) or proprietary solutions (if nothing is done).
Take a look at this information and let me know what you think.
Charlie
in Business Reporting Logical Model, Business reporting logical model, Creating Investor Friendly SEC XBRL Filings, General Information, Modeling Business Information Using XBRL, US GAAP Taxonomy, US SEC, XBRL General Information, XBRLS, financial reporting logical model
|
Post a Comment
| Email
| Print
