BLOG: Digital Financial Reporting
This is a blog for information relating to digital financial reporting. This blog is basically my "lab notebook" for experimenting and learning about XBRL-based digital financial reporting. This is my brain storming platform. This is where I think out loud (i.e. publicly) about digital financial reporting. This information is for innovators and early adopters who are ushering in a new era of accounting, reporting, auditing, and analysis in a digital environment.
Much of the information contained in this blog is synthasized, summarized, condensed, better organized and articulated in my book XBRL for Dummies and in the chapters of Intelligent XBRL-based Digital Financial Reporting. If you have any questions, feel free to contact me.
Entries from March 30, 2014 - April 5, 2014
Summary Information from Evaluating SEC XBRL Financial Filings Against Minimum Criteria
The document Arriving at Digital Financial Reporting All Stars: Summary Information provides information obtained from a detailed analysis of 6674 SEC XBRL financial filings. The purpose was to determine what it takes to actually be able to make use of reported financial information.
While not a scientific experiment or perhaps not perfect in any regard; this exercise was very useful and yielded pragmatic insight into creating and consuming digital financial reports and other types of digital business reports. This information is useful to professional accountants wishing to position themselves well for the future of financial reporting. It is useful to software vendors who might choose to build software to support digital financial reporting. It is useful to regulators who might be considering implementing systems which leverage XBRL-based digital financial reporting for compliance purposes. In is useful to other organizations who might want to experiment with XBRL-based digital business reporting within their organization.
The following is a summary of specific conclusions I have reached and other key insights I have obtained which I believe might also be useful to others. Details can be obtained from the above PDF.
- Currently 19% of all SEC XBRL financial filings analyzed satisfy minimum criteria and 95% are 5 or fewer errors from meeting criteria
- Specific identifiable and observable reasons exist for every issue pointed out
- Using SEC XBRL financial information need not and should not be a guessing game
- Minimum criteria are not judgmental or subjective in nature
- Validation and verification of the seven criteria are 100% automatable
- Current generation of digital financial report creation software has systemic issues
- Need for a framework for tuning the quality of SEC XBRL financial filings
- Need for a roadmap for tuning the quality of SEC XBRL financial filings
- My next level of criteria
- Any system which desires to implement XBRL-based digital financial reporting or XBRL-based digital business reporting can learn from SEC XBRL financial filings
The last point is the primary, key point. If someone wants to make XBRL-based digital financial reporting or XBRL-based digital business reporting work within their systems, SEC XBRL financial filings provide plenty of clues to help figure that out.
I have this vision. It is a simple vision. It is an achievable vision. It is a useful vision. Here is the vision:
 Click for larger view of image
Click for larger view of image
Imagine that every software vendor passed 100% of the seven minimum criteria which I outlined in this analysis. What would that mean? It would mean that fundamentally usable information would be provided by all those SEC XBRL financial filings. Yes, it would mean that.
But it would mean much more. What it would mean is that the concept of digital financial report would have been proven to work. What it would mean is that a digital financial reporting beachhead would have been established. What it would mean is that a framework for improving the quality of these digital financial reports even more would have been identified.
I will not go quite as far as saying that for the first time an open system has successfully been implemented, but it is a step in that direction. More on that later.
What it would mean is that about 34 different software vendors have provided off-the-shelf software which was used by 6,674 different public companies to report information to a government regulator and that information can safely, reliably, predictably be used via 100% automated processes to provide reported financial information to countless analysts and investors. This is a meaningful exchange of information.
Tell me that is not useful.
But we are not quite there. The analysis shows that 19% of SEC XBRL financial filings meet this vision, 1281 All-Stars as I call them. But even more encouraging is that 95% of all SEC XBRL financial filings are 5 or fewer errors from achieving this goal. So the vision is already within grasp and what is necessary to achieve that vision is clear.
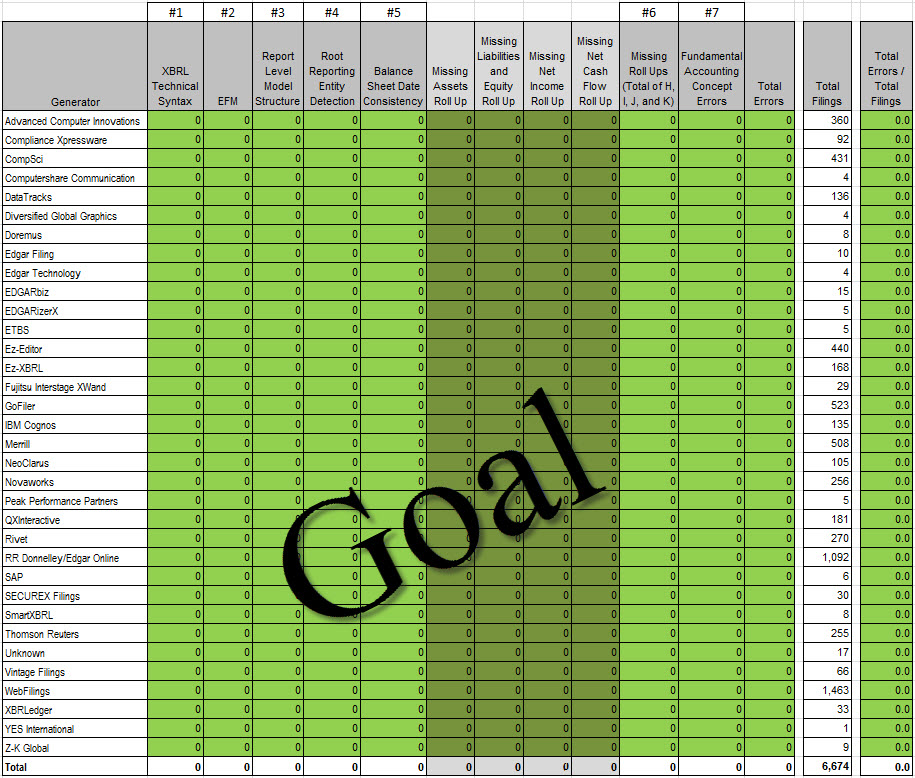
This is where we currently are in terms of all stars by generator (software vendor or filing agent): (average is 19%; green is at average or above average)
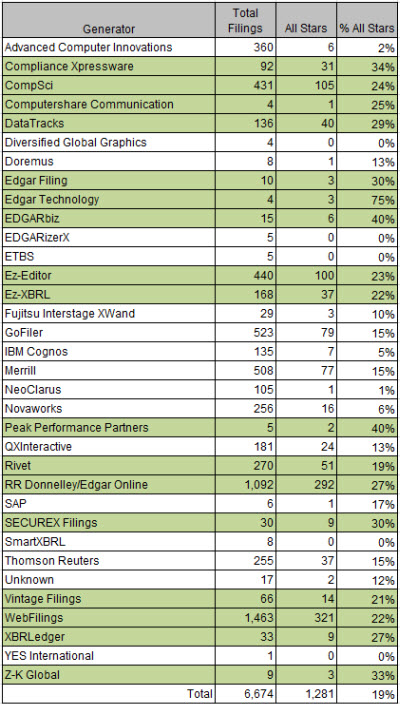
You can interpret this information however you want. This is how I interpret the information. If a software vendor or filing agent does not have 100% all stars, then there is some sort of systemic problem with the software. Full stop. Now you can play the blame game all you want, try and pass the buck. That helps nothing. Solving the problem helps. Achieving the vision helps.
If a software vendor does not understand this or believe this, then they certainly don't understand the bigger opportunity. This is only the tip of a much larger iceberg. Smart digital financial reporting tools are the future. If software cannot control these extremely basic things, there is no way that software can provide smart digital financial reporting functionality. If software does not pass the hurtle of these seven basic criteria, there is little hope that the software will ever be helpful to a professional accountant.
Achieving the vision helps the SEC be successful, it helps the FASB be successful, it helps XBRL US be successful, it helps public companies who are mandated to use XBRL be successful, but most importantly it helps software vendors be successful. The software vendor would have created something that works and is beginning to show signs of usefulness. It will also help the software vendor understand what professional accountants really need.
If software vendors pull this off, achieve the vision above, create something that really works; the software vendors might be able to expand the market: some 8 million private companies, 360,000 not-for-profits, 90,000 state and local governmental entities, and that is just financial reporting in the US. This is not about "save as XBRL". This is about machines assisting professional accountants in the creation of a financial report which is an extremely complex task. In digital financial reporting the output can still be a paper-based financial statement.
If software vendors don't achieve this vision, the market will certainly not expand, it might even contract. Case in point: the legislation to eliminate the XBRL filing requirement for smaller reporting entities, market reduction of 60% by some accounts.
Now, it would be best if all software vendors and filing agents worked to achieve this vision. Some will, some won't. The enemy is not each other, the enemy is the status quo. What if only one achieves 100% all-stars? What will the market do? What will likely happen is that some will achieve this goal, some won't.
I have provided this information to every software vendor and filing agent contact that I have. I have provided the information to the FASB, the SEC, XBRL US, and many others. New software vendors are also entering the market who want to fundamentally change accounting work practices. Be interesting to watch what happens. Be interesting to see who grasps this opportunity.
Am I nuts? Maybe. But that is what I see. What is your view?
 Charlie
in Becoming an XBRL Master Craftsman
|
Charlie
in Becoming an XBRL Master Craftsman
|
 Post a Comment
|
Post a Comment
|  Email
|
Email
|  Print
Print
Attaining High Semantic Clarity and Smart Digital Financial Reporting Tools
Machines can do things to help humans create or use digital financial reports. This help from machines will reduce costs and increase quality. How? Exactly how do you make financial report creation applications smart?
Simple. The first thing you have to do is realize that many of the work practices accountants use today will not be the work practices accountants will use in the future. What if you take the knowledge related to financial reporting, you put as much of that knowledge as possible into machine readable form, and then build software which can make use of that knowledge to assist the users of that software tool in creating financial reports.
Sound odd? Sure, it sounds odd to professional accountants who have been creating financial reports using first paper and typewriters, then paper and word processors, then paper and word processors outputting electronic formats such as PDF and HTML. Work practices will change.
But when you really think about it and realize that Microsoft Word (which is used to create about 85% of financial reports) and Microsoft Excel (which is used to accumulate, aggregate, and organize the stuff that ends up in Microsoft Word) don't understand anything about financial reporting, you can see the opportunity.
Hypothetically, let us say that you wanted to do this. (We will ignore the fact that people are already predicting that this will happen, that the global standards to do this efficiently already exist, software vendors already seem to be doing pieces of this, and that other domains such as health care are working toward this same goal.) How would you do it?
The key is machine readable knowledge with high semantic clarity, making sure the software truly understands financial reports and that users of the software agree that the software understands financial reports and creates those financial reports correctly. How do you achieve that?
First off you have to realize that a machine cannot do everything. Some things are objective and other things are subjective, requiring human judgement. Machines will not do the things that require judgement, humans will still perform those tasks. Machines will take care of the objective tasks, the tasks which can be effectively performed by a machine such as a computer.
So how do you do this and how do you make sure you have high semantic clarity? Here is the summary:
- Classification system: You will need some sort of classification system. Some classification systems are more expressive than others. The classification system should be flexible or extensible because financial reports are not forms. The classification system should be a global standard so that the classification system can be shared as broadly as possible to keep the costs of creating and maintaining the classification system within reason.
- Syntax: You will have to express the information in the classification system you come up with in some machine readable syntax. Some syntaxes are more expressive than others. Some are more flexible than others. Is the syntax a global standard or proprietary? A global standard would be preferable.
- Business rules: You will need to express the business rules of the domain as completely as possible so that (a) people understand and agree on those business rules and (b) information can be validated against those business rules to make sure the information created is correct. Both of these work together to make sure financial reports are created correctly.
- Interoperability: No one business system can do everything that is necessary. You will want to leverage business rules and other metadata from other systems so interoperability is important. This will help keep costs down. One of the problems with software today is that the software is centered on itself, not on the user or what the user needs to do. What if software were truly user centric or task centric? What if all the resources used to create a financial report were available within the same software application? The Accounting Standards Codification (ASC), GAAP guides, disclosure checklists, audit guides, accounting trends and techniques, etc. What if all these things were not human readable things, but things that were both machinge readable and human readable. What if you had an integrated "Chat" window where you could ask for advice from a professional. What if you could get on-demand training on a topic you had not yet been exposed to. I could go on and on.
A domain classification system can be on the formal side, or on the informal side. Achieving the appropriate balance is important. This graphic from the Ontology Summit provides a sense of this
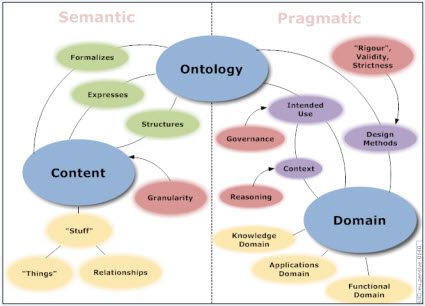 From An Intrepid Guide to Ontologies http://www.mkbergman.com/date/2007/05/16/
From An Intrepid Guide to Ontologies http://www.mkbergman.com/date/2007/05/16/
The graphic below based on work by Leo Obrst of Mitre as interpreted by Dan McCreary shows the trade-off between semantic clarity and time/money required to obtain that semantic clarity:
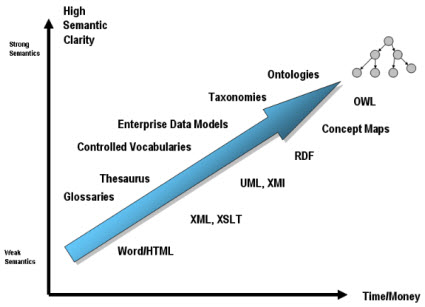 From An Intrepid Guide to Ontologies http://www.mkbergman.com/date/2007/05/16/
From An Intrepid Guide to Ontologies http://www.mkbergman.com/date/2007/05/16/
This second graphic, similar to the graphic above from the Semantics Overview, adds the syntactic, structual, and semantic interoperability into the equation and changes the "Time/Money" axis from above into the "Reasoning capacity" axis:
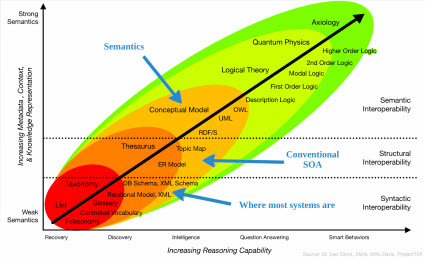 Semantics Overview http://prezi.com/prwsxj8po3ln/semantics-overview/
Semantics Overview http://prezi.com/prwsxj8po3ln/semantics-overview/
What is really encouraging is that even without the approprite software tools, accountants creating SEC XBRL financial filings are getting a high level of reported information correct when evaluated against a set of seven criteria. Admittedly these criteria do not exercise the entire digital financial report. But it is a start and provides both a beach head to start with and a framework to work within. A roadmap would be very helpful. Clearly quality needs to grow to a level of 99.9% or better if that is possible. Learning from SEC XBRL financial filings will help strike the appropriate balance.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
|
 7 References
| Email
| Print
7 References
| Email
| Print
Toward Digital Assurance of Digital Financial Reports
In his paper, Toward Assurance on Demand, Joris Hulstijn of Delft University of Technology in The Netherlands outlines both a vision of and framework for digital assurance reports for digital financial reports.
The paper discusses audits, reviews, and compilations; not just audits. The paper mentions how the credit rating departments of banks are setting up a kind of "auditing" services themselves. He says accountants would like to win back this market.
The author discusses more targeted assurance and assurance reports for specific classes of users of financial information, rather than every user fitting into one general group. Assurance profiles is what he calls this idea.
If you truly understand digital financial reporting you will realize that a lot of things have the potential to change accounting work practices. The accounant's report is no exception: audit, review or compilation.
This is a very thought provoking and insightful paper, particularly for professional accountants who offer assurance services.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding Interoperability
Bear with me as I walk through several different explanations of what is necessary to achieve meaningful interoperabilty. If you want to scroll directly to the final result, go to the bottom of this post.
One of the most helpful things that I had run across which helped me understand issues XBRL was having was a video published by the HL7 people. The HL7 video outlined three key things needed to achieve meaningful interoperability:
- Technical interoperability is concerned with the conveyance of payload. (moving data from system A to system B)
- Semantic interoperability communicates meaning unambiguously, using Codes, Identifiers and Context. (ensuring that system A and system B understand the information in the same way)
- Process interoperability enables shared human understanding that is needed to coordinate work processes and enable business systems to interoperate. (enable business processes housed at system A and system B to work together)
A great graphic that I found which discussed semantic clarity had a slightly different list and did not provide details of each item on the list: (but note that this does not have process interoperability)
- Syntactic interoperability
- Structural interoperability
- Semantic interoperability
This description of interoperability has the same set if items above, but provides explanations of each of the line items; but I don't particularly care for the explanations: (likewise this does not have process interoperability)
- Syntactic interoperability is just the ability to exchange information. It requires agreement or compatibility at the transport and application layers of the communications protocol stack and with the messaging protocol and encoding format
- Structural interoperability means that all of the expected information components are present with the same arrangement and granularity
- Semantic interoperability requires that the content of the message be understood by the recipient application or process
Another list (page 21) provided a different set of items, still similar: (likewise this does not have process interoperability)
- System
- Syntactic
- Structural
- Semantic
First, why interoperability? Easy. As the HL7 video puts it "Interoperability = Business benefits" (read this as better, faster, and/or cheaper). Second, likewise from the HL7 video: "Standards enable interoperability".
And so here is my list which steals the best ideas of each of the lists above and add some things that none of the other lists have. These are the levels of interoperabilty as I see the world:
- System interoperability: System interoperabilty relates to moving something from one system to another system. While system interoperability is not really an issue any longer, I will include it in order to make a point. The common denominator these days to achieve system interoperability is the internet. I am specifically saying internet and not the "World Wide Web". There are two keys here: TCP/IP and HTTP. Standard: TCP/IP; HTTP. Benefit: Any system can easily communicate with any other system. (Personally, I think that the internet is more important than the Web. Consider this Wired article: The Web is Dead. Long Live the Internet)
- Syntactic interoperability: Syntactic interoperabilty relates to the technical syntax being exchanged between systems. To be included as a candidate syntax, the syntax must work within TCP/IP and HTTP. There is another little piece that is related to syntax but not a lot of people get, another standard called Unicode. Unicode is actually extremely important. The short explanation is that not every language in the world uses the same 26 characters as the English alphabet (i.e ASCII characters). I don't want to get into a discussion of syntax, see the Understanding Syntax blog post for more detail. But, I will say this. If I were asked 15 years ago what the most important syntax is, I would have said XML hands down. But there are other syntaxes being used, such as JSON, which are giving XML a run for the money. But today XML is still king of the hill. Standard; XML, Unicode, JSON. Benefit: Global standard, easy to use machine readable structured formats which are also readable (sort of) by humans.
- Structural interoperability: Structural interoperability means that all of the expected information components of the information model are present with the same arrangement. Structural interoperabiilty relates to the information model metadata, the structure of the concent, not the content itself. Structure is content independent. If I understand this correctly a really good example of this is XBRL. While XBRL is a global standard syntax for business reporting, it was pointed out by Rene van Egmond and my self in the document, XBRLS: How a Simpler XBRL can be a Better XBRL, that different XBRL taxonomies were not interoperable. I would not position XBRLS as "the answer" today as I did back in 2008. The answer is the application profile or "the model". I would position XBRLS, or rather something like XBRLS, as "an answer". Here is another explanation of this using XML. XML is great, but the real power of XML is not really XML itself; it is standard languages created using XML. Each XML language is a standard structure. Now, this next thing may seem a little odd. XML languages are not generally extensible. XML itself is extensible. But once you create a language, that language is fixed, generally NOT extensible. Now, this helps one understand the difference between a "tree" and a "graph" (see syntax). Finally, XBRL has created a "structure" model, the XBRL Abstract Model 2.0. The bottom line here is that syntaxes like XBRL, EVA and RDF are extensible. Most XML languages are not. Standard: Application profile or "the model". Benefit: Flexibility.
- Semantic interoperability: Semantic interoperability ensures that each system making use of information is consistent. Semantic interoperability relates to the content which is being exchanged, the business domain. Semantics are content dependent. For example, financial reporting under US GAAP is a business domain. IFRS is a different business domain. There could be some similarities and there for different levels might exist, but generally the business rules used to express the allowed and disallowed content and the relations between the content are expressed via business rules specific to the domain of the content.
- Process interoperability: Process or work flow interoperability enables shared understanding that is needed to coordinate work processes and enable business systems to interoperate. Process interoperabiity enable business processes housed at system A and system B to work together correctly and effectively. For example, SEC XBRL financial filings can be ammended if, for example, there is an error discloved in a filing. Companies submitting information to the SEC need to understand the rules of resubmitting a filing, analysts need to understand what the SEC does when a filing is ammended so they don't extract the incorrect information from financial reports. That is an example of process or work flow.
Seem complicated? It is complicated. Very complicated. But software will hide this complexity from the user to the extent that "patterns" or standards exist. All humans need to do is express this information in an organized manner which computers can read and use. Consider the OSI model. The OSI model has seven layers, very complicated. Frankly, I don't understand how the OSI model works, all I care about is THAT it works. The OSI model enables system level interoperabilty. It is a smorgasbord of standards. Digital financial reporting can be complicated under the hood, but easy for business users to make use of; it things are set up correctly.
Two final thoughts.
No matter how different information might look (different syntaxes, different names, different structures); if their conceptual model is the same, it is possible to transform one implementation model to another implementation model using completely automated processes.
Automated validation/verification many times may not be sufficient to guarantee complete interoperability. Human judgment and manual effort can be necessary in addition to automated validation/verification to effectively communicate information and thefore achieve interoperability. Where automated validation/verification can be created, it is more reliable, cheaper than human validation steps, and faster.
The following are additional helpful resources:
- Interoperability (Wikipedia)
- A Semantic Foundation for Achieving HIE Interoperability (Health care)
- What is Interoperability?(Health care)
- Information Integration and Interoperability (General)
- Changing Focus on Interoperability in Information Systems: From System, Syntax, Structure to Semantics (General)
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print
Understanding Business Rules
The most suscinct definition of business rules that I have come across is this:
Business rule: A formal and implementable expression of some user requirement.
This definition of what a busines rule is comes from the Business Rules Group which is a good source of information about business rules, particularly their Business Rules Manifesto.
There really is no standard definition for what a business rule is. Here are some definitions which others use to help you get a sense for what business rules are:
- A formal statement that defines or constrains some aspect of a business that is intended to assert business structure, or to control or otherwise influence the behavior of the business
- A way of expressing the business meaning (semantics) of a set of information
- A formal and implementable expression of some business user requirement
- The practices, processes, and policies by which an organization conducts its business
Business rules exist in the form of relationships between pieces of business information. Some examples can help you better understand exactly what they are:
- Assertions: For example asserting that the balance sheet balances or Assets = Liabilities + Equity.
- Computations: For example, calculating things, such as Total Property, Plant and Equipment = Land + Buildings + Fixtures + IT Equipment + Other Property, Plant, and Equipment.
- Process-oriented rules: For example, the disclosure checklist commonly used to create a financial statement which might have a rule, "If Property, Plant, and Equipment exists, then a Property, Plant and Equipment policies and disclosures must exist."
- Regulations: Another type of rule is a regulation which must be complied with, such as "The following is the set of ten things that must be reported if you have Property, Plant and Equipment on your balance sheet: deprecation method by class, useful life by class, amount under capital leases by class . . ." and so on. Many people refer to these as reportability rules.
- Instructions or documentation: Rules can document relations or provide instructions, such as "Cash flow types must be either operating, financing, or investing."
- Relations: How things can be related, such as whole-part relations. For example, how the business segments of an economic entity are related.
Business rules can be grouped into two broad categories: data quality logic related and business logic related. In their Decision Model, Knowledge Partners International points out the important difference between data quality logic and business logic:
- Data quality logic: is the logic used against data elements to determine if they meet various data quality dimensions such as completeness, reasonableness, etc.
- Business logic: is the logic that uses data elements as conditions leading to business-oriented (not data-validation-oriented) conclusions such as compliance, eligibility, etc.
Business rules are important. Why? Because the only way a meaningful exchange of information can occur is the prior existence of agreed upon technical syntax, domain semantics, and process/workflow rules rules. you cannot create business rules after-the-fact and then expect information to follow those rules. Business rules need to be agreed upon in advance.
Business rules implemented in most business systems are a mess for two reasons. (This one hour videowalks you through this.) First, the business rules are imbedded within the system. This causes to problems: (1) the business rules need to be created by progammers and not business people, (2) you cannot exchange the business rules between business systems. The second reason that the rules are very hard to manage. There are no groups or patterns utilized. I won't go into this further, watch the video for more details.
Business rules are implemented in XBRL using XBRL Calculations, XBRL Definitions and XBRL Formulas. XBRL calculations are fairly well understood and used. Basically these articulate roll up type relations. But lots of other mathematical relations exist such as a roll forward, adjustment, or variance. There are even more complex computations. To express these and other mathematical type relations something more powerful is necessary, and that is why XBRL Formula exists.
There are other business rules which have little or nothing to do with mathematical computations that need to be expressed. XBRL definition relations are available to express these types of business rules.
For example take the whole-part relation. The document A Taxonomy of Whole-Part Relations goes into detail. This presentation (on slide 9) explains the difference between a taxonomy and a partonomy and provides these general categories of relations:
- component-integral object: for example (pedal – bike)
- member-collection: for example (ship – fleet)
- portion-mass: for example (slice – pie)
- stuff-object: for example (steel – car)
- feature-activity: for example (paying – shopping)
- place-area: for example (Everglades – Florida)
While XBRL can express these sorts of whole-part relations, there are no real standard approaches within XBRL for doing this. For example, while XBRL Dimensions was created using XBRL definitions to be a standard approach to expressing allowed and disallowed dimensional relations; nothing exists to express other sorts of relations. I thought that something like OWL could fill this gap, but while OWL is powerful it does not fulfil 100% of what is required and OWL is extremely hard for business users to understand.
In 2003 the paper, Business rules validation - the Standard the W3C Forgot, pointed out that there was no real way to articulate business rules using XML. Since then, many different business rules syntaxes have been created: RuleML, SPIN, RIF, SWRL. I looked into all these things before and I reached two conclusions: this is very confusing, this is very complicated.
So the question is this: What is the best approach to expressing 100% of the business rules necessary to provide the appropriate level of semantic clarity for digital financial reporting and digital business reporting? What is the best syntax for expressing all these rules? How will these business rules be mantained and managed by business users?
To get a good grasp of the types of business rules which will be important to business users, read this blog post, this blog post, and this blog post.
Charlie
in Becoming an XBRL Master Craftsman
|
Post a Comment
| Email
| Print

